🎮
Riot Games API で League of Legends のチーム構成の分析をしたい!
筆者について
- LoLに関しては総プレイ時間: 0時間、総配信視聴時間: 20時間程の超初学者
- ゲーム理解度が低すぎるため、何か不自然な点があればご指摘いただきたい
- 実際にゲームをプレイする人にとって何かしらの知見になったら嬉しい
はじめに
-
高ランク帯ほどチーム構成が煮詰まってきて、ジャンケンのような構造が見られるのでは、、、という浅い仮説検証
- チャレンジャー帯のマッチにおけるチーム構成のクラスタリング(分類)を行った
- ジャンケンとまではいかないまでも特徴的なチーム構成を観察することができた
- 鍵になるのはbotのEzrealとsupportのKarma
自分の学び・読者の学び(?)
- 自分の学び
- APIを使ってデータを収集する経験
- 自然言語処理による埋め込みの実装の経験
- 読者の変化
- Riot APIを使って高ランク帯のチーム構成に関する情報を収集する方法の理解
- League of Legendsにおけるチーム構成に関する発見がある(?)
開発環境
- Windows
- VScode
- Jupyter Notebook
キーワード
- League of Legends
- Riot API
- Python
- 自然言語処理
- TF-IDF
- 次元削減
- SVD
- クラスタリング
- k-Means
分析手順
0. 事前準備
0.1. Python(3.9.21) の仮想環境を作成
conda create -n lol_analysis python=3.9.21 -y
0.2. ライブラリのインストール
- バージョンを指定してライブラリをインストールする
conda activate lol_analysis
pip install requests==2.32.3 pandas==2.2.3 numpy==1.23.0 \
matplotlib==3.9.4 japanize_matplotlib==1.1.3 \
scikit-learn==1.6.1 gensim==4.3.3
0.3. ライブラリのインポート
import requests
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import time
from sklearn.feature_extraction.text import TfidfVectorizer
from gensim.models import Word2Vec
from sklearn.decomposition import TruncatedSVD
from sklearn.cluster import KMeans
from collections import Counter
from itertools import combinations
0.4. Riot API key の取得
- 下記のURLからアカウント作成
- API keyを取得
api_key = 'xxx'
# api_key についての確認
api_ulr = 'https://br1.api.riotgames.com/lol/league/v4/challengerleagues/by-queue/RANKED_SOLO_5x5' + '?api_key='+ api_key
resp = requests.get(api_ulr)
print("200 が出力されれば正常")
resp
1. プレイヤーIDの取得
- 現時点のチャレンジャー帯に属しているプレイヤーのID(puuid)を取得する
# チャレンジャー帯(グランドマスター帯・マスター帯)のプレイヤー情報を取得する関数
def get_summonerId(api_key):
challenger_url = 'https://br1.api.riotgames.com/lol/league/v4/challengerleagues/by-queue/RANKED_SOLO_5x5?api_key={}'.format(api_key)
# grandmaster_url = 'https://br1.api.riotgames.com/lol/league/v4/grandmasterleagues/by-queue/RANKED_SOLO_5x5?api_key={}'.format(api_key)
# master_url = 'https://br1.api.riotgames.com/lol/league/v4/masterleagues/by-queue/RANKED_SOLO_5x5?api_key={}'.format(api_key)
league_url_lists = [challenger_url]
df_list = []
for url in league_url_lists:
resp = requests.get(url)
league_df = pd.json_normalize(resp.json()['entries'])
df_list.append(league_df)
final_league_df = pd.concat(df_list)
return final_league_df
# プレイヤー情報の取得
league_df = get_summonerId(api_key)
print('league_df has information about {} players in challenger elo'.format(league_df.shape[0]))
# csvとして保存
league_df.to_csv('00_data_source//player_df.csv', index = False)
-
league_dfの作成例
- 各columnの意味については参考資料を参照
| summonerId | puuid | leaguePoints | rank | wins | losses | veteran | inactive | freshBlood | hotStreak |
|---|---|---|---|---|---|---|---|---|---|
| xxx | yyy | 1851 | I | 202 | 236 | True | False | False | False |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
2. マッチIDの取得
- 各プレイヤーの過去20試合分のマッチID(matchid)を取得する
# `puuid` から `matchid` を取得する関数
def get_matchids_by_puuid(df, api_key, count=20):
matchids_list = []
for i in range(len(df)):
puuid = df['puuid'].iloc[i]
api_url = f'https://americas.api.riotgames.com/lol/match/v5/matches/by-puuid/{puuid}/ids?queue=420&type=ranked&start=0&count={count}&api_key={api_key}'
retry_count = 0
while retry_count < 10:
resp = requests.get(api_url, api_key)
if resp.status_code == 200:
try:
matchids = pd.DataFrame(resp.json(), columns=['matchid'])
matchids_list.append(matchids)
print(f"No.{i+1}: Request for puuid {puuid}: Success")
except Exception as e:
print(f"Error parsing puuid {puuid}: {e}")
break
elif resp.status_code in [500, 502, 503, 504]:
print(f"No.{i+1}: Request for puuid {puuid}: Server Error")
time.sleep(5)
retry_count += 1
else:
print(f"No.{i+1}: Request for puuid {puuid}: {resp.status_code}")
break
# データの統合
if matchids_list:
matchids_df = pd.concat(matchids_list, ignore_index=True)
return matchids_df
else:
return pd.DataFrame(columns=['matchid'])
# `matchid` を取得する
matchids_df = get_matchids_by_puuid(league_df, api_key)
matchids_df.reset_index(inplace=True)
matchids_df.drop(columns = 'index', inplace = True )
# 重複した`matchid`の削除
matchids_df_without_duplicates = matchids_df.drop_duplicates()
# 削除された数を確認
matchids_count_before = matchids_df.shape[0]
matchids_count_after = matchids_df_without_duplicates.shape[0]
print('Before we had {} matchids, after we have {} matchids'.format(matchids_count_before, matchids_count_after))
# csvとして保存
matchids_df_without_duplicates.to_csv('00_data_source//matchids_df.csv', index = False)
matchids_df = matchids_df_without_duplicates
- matchids_dfの作成例
| matchid |
|---|
| BR1_3078876493 |
| ... |
3. マッチ情報の取得
-
matchid からマッチ情報を取得する
- 1904試合分のデータ取得に約40分かかる
# マッチIDから試合情報を取得(レート制限付き)
def get_match_info_by_matchId(match_ids, api_key):
matchid_info_list = []
for i in range(len(match_ids)):
match_id = match_ids['matchid'].iloc[i]
api_url = f'https://americas.api.riotgames.com/lol/match/v5/matches/{match_id}?api_key={api_key}'
retry_count = 0
while retry_count < 10:
resp = requests.get(api_url, api_key)
if resp.status_code == 200:
try:
match_data = resp.json()
matchid_info = pd.json_normalize(match_data['info']['participants'])
matchid_info_list.append(matchid_info)
print(f"No.{i+1}: Request for match {match_id}: Success")
except Exception as e:
print(f"Error parsing match {match_id}: {e}")
break
elif resp.status_code == 429:
print(f"No.{i+1}: Request for match {match_id}: Too Many Requests")
time.sleep(30)
retry_count += 1
elif resp.status_code in [500, 502, 503, 504]:
print(f"No.{i+1}: Request for match {match_id}: Server Error")
time.sleep(5)
retry_count += 1
else:
print(f"No.{i+1}: Request for match {match_id}: {resp.status_code}")
break
# データの統合
if matchid_info_list:
matchid_info_df = pd.concat(matchid_info_list, ignore_index=True)
return matchid_info_df
else:
return pd.DataFrame()
# 1904試合分: 40分程度
matchData_df = get_match_info_by_matchId(matchids_df, api_key)
# csvとして保存
matchData_df.to_csv('00_data_source//matchData_df.csv', index = False)
-
matchData_dfの作成例
- 各columnの意味については参考資料を参照
| PlayerScore0 | PlayerScore1 | ... | challenges.earliestElderDragon | challenges.hadAfkTeammate |
|---|---|---|---|---|
| 0 | 0 | ... | NaN | NaN |
| ... | ... | ... | ... | ... |
4. データの整形
- データを分析しやすい形に整形する
def process_and_aggregate_match_data(matchData_df):
# 必要な列を抽出
match_df = matchData_df[["teamId", "championName", "individualPosition", "teamPosition", "win"]].copy()
# 1試合10行ごとに試合番号を割り振る
num_rows_per_match = 10
match_df['match_num'] = (match_df.index // num_rows_per_match) + 1
# ポジションのリスト(TOP, JUNGLE, MIDDLE, BOTTOM, UTILITY)
positions = ['TOP', 'JUNGLE', 'MIDDLE', 'BOTTOM', 'UTILITY']
# tempPosition を追加(5人ずつ繰り返し)
match_df['tempPosition'] = [positions[i % 5] for i in range(len(match_df))]
# 試合データの集約処理
match_data_list = []
num_matches = len(match_df) // 10
for match_num in range(num_matches):
# Aチーム(行1-5)
a_team = match_df.iloc[match_num * 10 : match_num * 10 + 5]
a_team_composition = ",".join(a_team['championName'])
a_team_win = a_team['win'].iloc[0]
a_team_positions = {pos.lower() + "_champion": champ for pos, champ in zip(a_team["tempPosition"], a_team["championName"])}
# Bチーム(行6-10)
b_team = match_df.iloc[match_num * 10 + 5 : match_num * 10 + 10]
b_team_composition = ",".join(b_team['championName'])
b_team_win = b_team['win'].iloc[0]
b_team_positions = {pos.lower() + "_champion": champ for pos, champ in zip(b_team["tempPosition"], b_team["championName"])}
# Aチームのデータをリストに追加
match_data_list.append({
'match_num': match_num + 1,
'team_composition': a_team_composition,
'win': a_team_win,
**a_team_positions
})
# Bチームのデータをリストに追加
match_data_list.append({
'match_num': match_num + 1,
'team_composition': b_team_composition,
'win': b_team_win,
**b_team_positions
})
result_df = pd.DataFrame(match_data_list)
return result_df
# データの整形
team_composition_df = process_and_aggregate_match_data(matchData_df)
- team_composition_dfの作成例
| match_num | team_composition | win | top_champion | jungle_champion | middle_champion | bottom_champion | utility_champion |
|---|---|---|---|---|---|---|---|
| 1 | Fiora, Xin Zhao, Orianna, Seraphine, Nami | True | Fiora | Xin Zhao | Orianna | Seraphine | Nami |
| 1 | Gwen, Naafiri, Akali, Ezreal, Karma | False | Gwen | Naafiri | Akali | Ezreal | Karma |
| 2 | Swain,Talon,Orianna,Varus,Rell | False | Swain | Talon | Orianna | Varus | Rell |
| ... | ... | ... | ... | ... | ... | ... | ... |
5. TF-IDF を用いた埋め込みの作成+次元削減+クラスタリング
- TF-IDF を用いてチーム構成の埋め込みを作成する
- 作成した埋め込みをSVDを用いて2次元に削減する
- k-Means法を用いて3つのクラスターに分類する
- クラスタリング結果を可視化する
- 勝敗を可視化する
# -------------------------
# 1. データの定義
# -------------------------
df_pca = team_composition_df
# -------------------------
# 2. TF-IDF を用いたチーム構成の埋め込み
# -------------------------
vectorizer = TfidfVectorizer()
team_vectors = vectorizer.fit_transform(df_pca['team_composition'])
# -------------------------
# 3. 次元削減(SVD)
# -------------------------
# 2次元に削減
svd = TruncatedSVD(n_components=2, random_state=42)
embedding_svd = svd.fit_transform(team_vectors)
# SVD後の次元をDataFrameに追加
df_pca['pca1'] = embedding_svd[:, 0]
df_pca['pca2'] = embedding_svd[:, 1]
# -------------------------
# 4. クラスタリング(k-Means)
# -------------------------
kmeans = KMeans(n_clusters=3, random_state=42)
df_pca['cluster'] = kmeans.fit_predict(embedding_svd)
# -------------------------
# 5. クラスタリング結果の可視化
# -------------------------
plt.figure(figsize=(8, 6))
scatter = plt.scatter(df_pca['pca1'], df_pca['pca2'], c=df_pca['cluster'], cmap='viridis', s=10)
plt.title("Team Composition Clusters (TF-IDF + SVD)")
plt.xlabel("SVD Component 1")
plt.ylabel("SVD Component 2")
plt.legend(*scatter.legend_elements(), title="Cluster")
plt.show()
# -------------------------
# 6. 勝敗の可視化
# -------------------------
plt.figure(figsize=(8, 6))
scatter = plt.scatter(df_pca['pca1'], df_pca['pca2'], c=df_pca['win'], cmap='viridis', s=10)
plt.title("Team Composition Clusters (TF-IDF + SVD)")
plt.xlabel("SVD Component 1")
plt.ylabel("SVD Component 2")
plt.legend(*scatter.legend_elements(), title="Win")
plt.show()
-
クラスタリング結果の可視化

-
勝敗の可視化
- win=1 が勝利チームを表す

- win=1 が勝利チームを表す
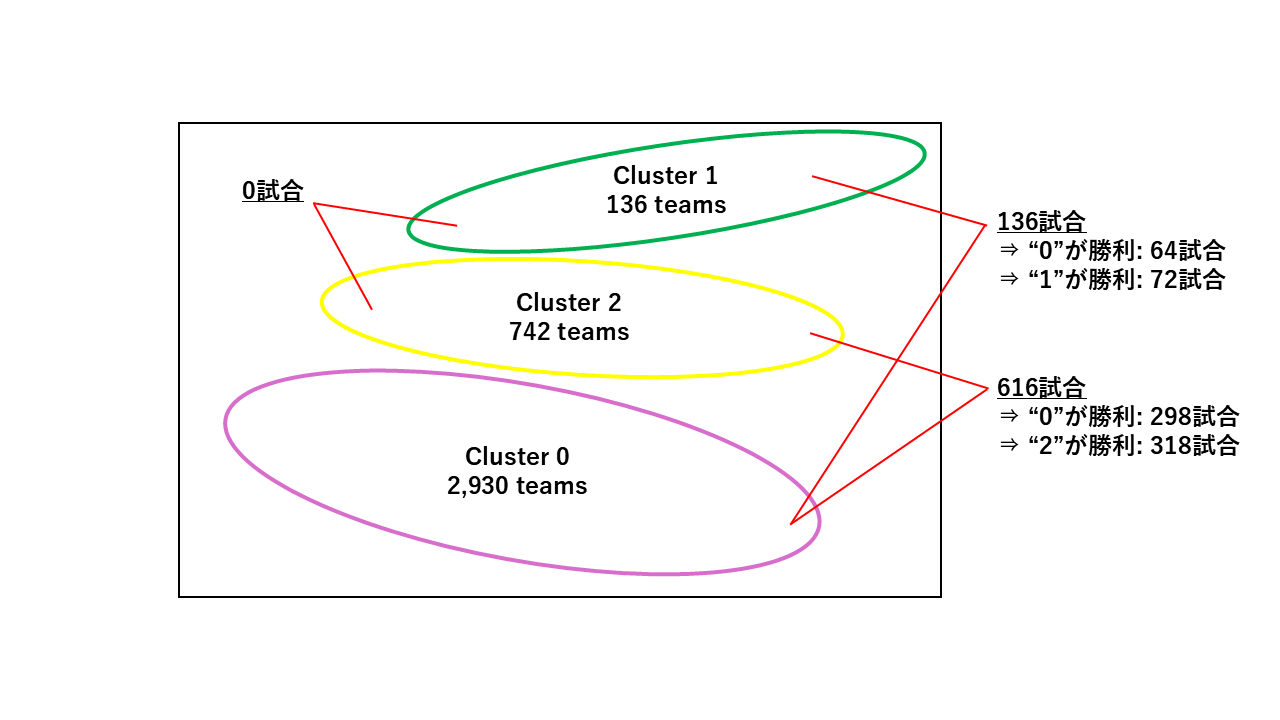
6. 各クラスター間の勝敗の集計+可視化
-
あまり綺麗なコードではないのでAppendixに記載した
-
クラスター間の勝敗の模式図
7. 各クラスターにおけるチャンピオン使用回数
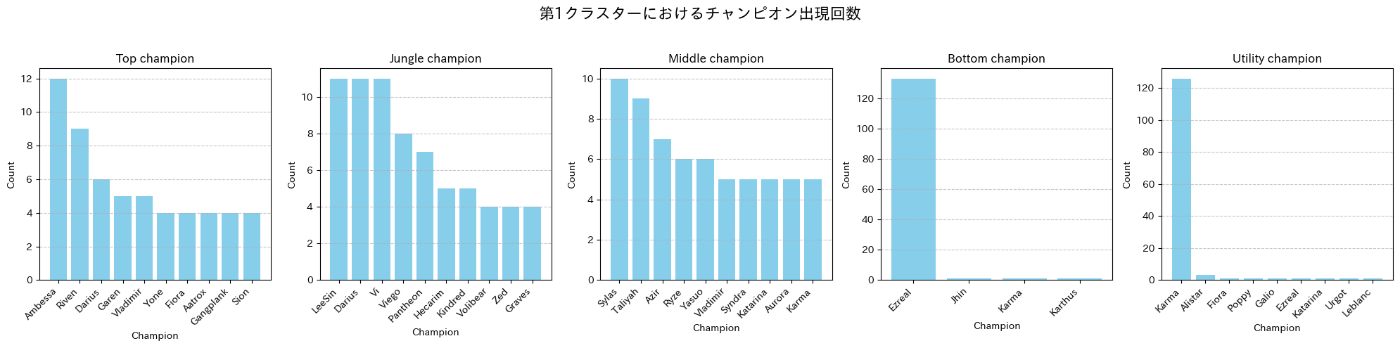
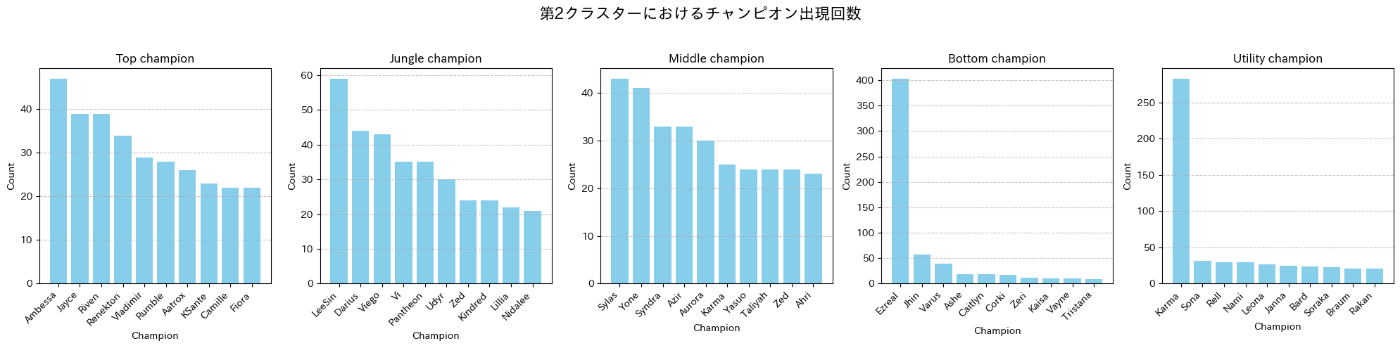
- 前項で分類したクラスター0, 1, 2における各ロールのチャンピオン使用回数を集計する
# クラスターごとに5つのロールにおけるチャンピオンの出現回数を1つの図にまとめて表示
for i in range(max(df_pca["cluster"]+1)):
fig, axes = plt.subplots(1, 5, figsize=(20, 5))
fig.suptitle(f"第{i}クラスターにおけるチャンピオン出現回数", fontsize=16)
for ax, pos in zip(axes, ["top_champion", "jungle_champion", "middle_champion", "bottom_champion", "utility_champion"]):
# 各クラスター内でのチャンピオンの出現回数をカウントし、上位10個を取得
champ_counts = df_pca[df_pca["cluster"] == i][pos].value_counts().head(10)
# ヒストグラムの描画
ax.bar(champ_counts.index, champ_counts.values, color='skyblue')
ax.set_title(pos.replace("_", " ").capitalize())
ax.set_xlabel("Champion")
ax.set_ylabel("Count")
ax.set_xticklabels(champ_counts.index, rotation=45, ha='right')
# グリッドを追加
ax.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()
-
クラスター0の各ロールのチャンピオン使用回数(上位10)

-
クラスター1の各ロールのチャンピオン使用回数(上位10)
-
クラスター2の各ロールのチャンピオン使用回数(上位10)
まとめ
- クラスター0のチーム構成に対して、クラスター1, 2のチーム構成がカウンターになっている可能性がある(もしくはその逆?)
- 勝敗に注目すると、クラスター1, 2が僅かながらクラスター0に勝ち越していることを確認できる
- クラスター0のチーム構成には目立った特徴は見られないが、クラスター1, 2のチーム構成はbotのEzreal, support(utility)のKarmaのピック率が非常に高い
- クラスター1, 2を比較するとtopにおけるJayceのピック率に違いがみられる
- クラスター2の方が相対的にtopでのJayceのピック率が高い傾向にある
- クラスター1, 2を比較するとtopにおけるJayceのピック率に違いがみられる
参考資料
- Riot API について(公式ページ)
- Riot API を用いたデータ取得の実装例
Appendix
各クラスター間の勝敗の集計コード
- クラスター間の試合回数の集計
# `match_num` ごとにクラスタのリストを取得
match_clusters = df_pca.groupby("match_num")["cluster"].apply(list)
# クラスタの組み合わせをカウント
pair_counts = Counter()
for clusters in match_clusters:
if len(clusters) == 2: # ちょうど2チームのデータがある場合のみカウント
pair = tuple(sorted(clusters)) # クラスタの順序を統一
pair_counts[pair] += 1
# 指定された組み合わせのみ抽出
target_combinations = [(0, 0), (0, 1), (0, 2), (1, 1), (1, 2), (2, 2)]
result_counts = {pair: pair_counts.get(pair, 0) for pair in target_combinations}
# 結果の表示
print(result_counts)
- 違うクラスター間の勝敗を集計
# `match_num` ごとに `cluster` と `win` のリストを作成
match_cluster_win = df_pca.groupby("match_num")[["cluster", "win"]].apply(lambda x: list(zip(x["cluster"], x["win"])))
# 指定ペアごとに勝利数をカウント
win_counts = { (0, 1): 0, (0, 2): 0, (1, 2): 0 }
for clusters_wins in match_cluster_win:
# クラスタの組み合わせを取得
pairs = list(combinations(sorted(clusters_wins), 2)) # ((cluster1, win1), (cluster2, win2)) のリスト
for (c1, w1), (c2, w2) in pairs:
if (c1, c2) in win_counts:
if c1 == 0 and w1: # (0,1) または (0,2) で 0 の勝利数
win_counts[(c1, c2)] += 1
elif c1 == 1 and c2 == 2 and w1: # (1,2) で 1 の勝利数
win_counts[(c1, c2)] += 1
# 結果を表示
print(win_counts)
Discussion