AWS Step Functions Mapステート実装時のハマリポイントと解決策
はじめに
AWS Step FunctionsのMAPステートを使用して動的な並列処理を行うことができますが、実装にはいくつか注意点があります。
今回はMAPステートのハマリポイントとその解決策をご紹介します。
最大のハマリポイント(?)である"並列処理のうち一つでも失敗するとステート全体が失敗してしまう"問題にも触れています。
また、実際の使用例も紹介しているので是非参考にしてみてください。
忙しい人向けのまとめ
- 配列以外にも渡したいパラメータがある場合はItemsPathとItemSelectorを使用する
- Catchフィールドを使用することでMAPステート全体を成功扱いすることができる。ただし後続の処理でどの配列処理が失敗したかわかるように処理を工夫するのがオススメ
- Amazon S3 のデータ整合性モデルの観点から、S3への書き込みをMAPステートで行うのはオススメできない
配列以外にも渡したいパラメータがある場合
単純に[1,2,3]みたいな配列だけを渡したいケースであれば問題ないですが、他にも各配列に共通して渡したい値があると思います。例えば、後述する使用例では、配列以外にもAmazon ConnectのインスタンスIDをパラメータとして渡す必要があります。
そのときはItemsPathとItemSelectorフィールドを使用しましょう。ASLの該当箇所(抜粋)は以下の通りです。
"ItemsPath": "$.csvcount.Payload.csvcount",
"ItemSelector": {
"number.$": "$$.Map.Item.Value",
"instanceId.$": "$.instanceId"
},
処理の流れは以下の通りになります。
- $.csvcount.Payload.csvcountから配列の値を取得する
- 配列の値をnumberという変数に格納する
- 取得したインスタンスIdをinstanceIdという変数に格納する
MAPステートでエラーが起きても全体を停止しないために
ClassmethodさんがAWS Step FunctionsのMapステート内でエラーが起きても全体を停止しない方法の記事でも紹介している通り、MAPステートは並列処理のうち一つでも失敗するとステート全体が失敗します。さらに、処理途中の並列処理はキャンセルとなります。
この問題を回避する為に、必ずCatchフィールドを使用してエラーが起きた場合でも並列処理自体は成功扱いとし、次の処理に進めるように設定しておきましょう。ASLの該当箇所(抜粋)は以下の通りです。
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Comment": "resultasfalse",
"ResultPath": "$.usercreate.result",
"Next": "Pass"
}
],
"End": true
},
"Pass": {
"Type": "Pass",
"End": true
}
ここではCatchフィールドを使用し、エラーとなった場合は"Pass"ステートを実行するように定義することで処理自体は成功扱いとなります。
ただし、後続の処理でどの配列処理がエラーとなったかを検証整理する為にもResultPathを使用して出力結果を渡すようにしましょう。 ResultPathを使用しないと、エラー文だけ出力されてしまうのでどの配列処理がエラーになったか追跡するのが非常に困難になります。逆に言えば、ResultPathを使用することで入力値を出力値をセットで後続処理に渡せるので、後続処理が可能になります。
S3への書き込みをMAPステートで行うのはオススメできない
公式ドキュメントのアプリケーションの同時実行にも記載がある通り、同一バケットに複数の書き込み処理が走った場合、一部の処理は反映されない可能性があります。MAPステート内ではS3への書き込みを行うことは控えたほうがよさそうです。
その代わり、MAPステートでS3への書き込み情報だけ整理して、後続のLambda等でループ処理を行ったほうが確実だと思います。
実際の使用例
今回は以下のようなケースを考えてみます。
- 最新のCSVファイルの情報をもとにAmazon Connectのユーザを自動作成したい
- CSVファイルが保持するユーザ情報には一部情報が不足 or 不適切なデータがものがある
- 自動作成完了後、どのユーザ登録が成功し、どのユーザ登録が失敗したのかをcsvファイル形式で出力したい
ステートマシンの作成
今回は以下のようなステートマシンを作成しました
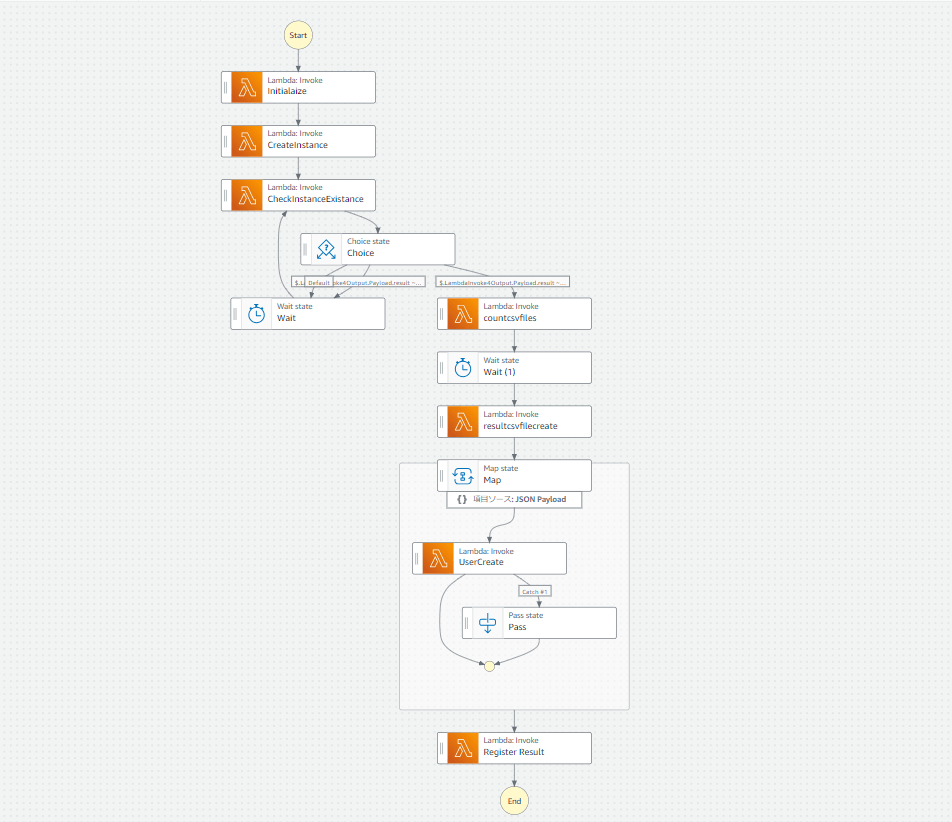
こちらを実行すると、Amazon Connectのインスタンスが作成され、その中にAmazon Connectのユーザが作成されます
(ユーザ情報はS3から取得したcsvファイルの内容を反映)
さらに、実行結果を新規作成したcsvファイルに出力し、S3に保存します
処理の流れは以下になります
- InitializeでLambdaを実行し、アカウント内の全Amazon Connect インスタンスを削除
※テストのたびに消すのが面倒だったため - CreateInstanceでLambdaを実行し、Amazon Connectインスタンスを作成
- CheckInstanceExistanceでLambdaを実行。RoutingProfileIdとSecurityProfileIdを取得し、どちらもNULLでなければ後続処理。一方でもNULLであれば15秒のWait処理を実行し再度同一Lambdaで存在チェックを実施
※CreateInstanceの直後にCreateUserAPIを実行するとなぜか"RoutingProfileとSecurityProfileIdが存在しません"のエラーになることがありました。その為、インスタンス作成後しばらく待機して確実にRoutingProfileとSecurityProfileが取得できるようになってから後続処理に流せるようにしています - countcsvfilesでLambdaを実行し、最新のcsvファイルに登録対象ユーザの人数を取得し、配列として数字を渡す
※csvファイルに記載された登録対象ユーザが5名の場合[1,2,3,4,5]を渡す - resultcsvfilecreateではLamdaを実行し、ユーザ登録結果を記録するcsvファイルを作成(既に存在する場合は初期化)
- MapステートではLambdaを実行しAmazon ConnectのCreate User APIを実施。このときCatchフィールドを使用し、Lambda側でエラーになった際はPassステートを使用することで、Mapステートとしては成功となるように設定
※上述の通り、配列番号の他にAmazon ConnectのinstanceIdも入力値として渡す必要があったので、ItemsPathとItemSelectorフィールドを使用
※Mapステートから渡された配列番号Nを使用し、csvファイルのN行目を読み取ってAPIのパラメータに代入する - Mapステートから渡されたパラメータをもとにLambdaが実行結果のcsvファイルを作成し、S3に保存する。
※Mapステート上でResultPathを使用し、6のLambdaが入力値と出力値をセットで渡しているので7のLambdaで解析が可能
※上述の通り、S3への書き込みは配列処理で行うのは危険である為、Mapステートから渡されたパラメータをもとにループ処理で書き込む方式を採用しています
ASLは以下になります。AccountID等を適宜変更して使用いただければと思います。
ASL(折りたたんであります)
{
"Comment": "ステートマシンの説明",
"StartAt": "Initialaize",
"States": {
"Initialaize": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:ap-northeast-1:AccountID:function:DeleteAllInstance:$LATEST"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2
}
],
"Next": "CreateInstance"
},
"CreateInstance": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:ap-northeast-1:AccountID:function:CreateAmazonConnectInstance:$LATEST"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2
}
],
"Next": "CheckInstanceExistance"
},
"CheckInstanceExistance": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:ap-northeast-1:AccountID:function:instanceexistcheck:$LATEST"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2
}
],
"Next": "Choice",
"ResultPath": "$.LambdaInvoke4Output"
},
"Choice": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.LambdaInvoke4Output.Payload.result",
"StringMatches": "Fail",
"Next": "Wait"
},
{
"Variable": "$.LambdaInvoke4Output.Payload.result",
"StringMatches": "Success",
"Next": "countcsvfiles"
}
],
"Default": "Wait"
},
"countcsvfiles": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:ap-northeast-1:AccountID:function:CountCSV:$LATEST"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2
}
],
"Next": "Wait (1)",
"ResultPath": "$.csvcount"
},
"Wait (1)": {
"Type": "Wait",
"Seconds": 15,
"Next": "resultcsvfilecreate"
},
"resultcsvfilecreate": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:ap-northeast-1:AccountID:function:csvfilecreate:$LATEST"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2
}
],
"Next": "Map",
"ResultPath": "$.csvfilecreate"
},
"Map": {
"Type": "Map",
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "INLINE"
},
"StartAt": "UserCreate",
"States": {
"UserCreate": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "arn:aws:lambda:ap-northeast-1:AccountID:function:CreateUser20231124:$LATEST",
"Payload.$": "$"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2
}
],
"ResultPath": "$.usercreate.result",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Comment": "resultasfalse",
"ResultPath": "$.usercreate.result",
"Next": "Pass"
}
],
"End": true
},
"Pass": {
"Type": "Pass",
"End": true
}
}
},
"ItemsPath": "$.csvcount.Payload.csvcount",
"ItemSelector": {
"number.$": "$$.Map.Item.Value",
"instanceId.$": "$.instanceId"
},
"Next": "Lambda Invoke"
},
"Lambda Invoke": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:ap-northeast-1:AccountID:function:resultregister:$LATEST"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2
}
],
"End": true
},
"Wait": {
"Type": "Wait",
"Seconds": 15,
"Next": "CheckInstanceExistance"
}
}
}
Lambdaの作成
使用したLambdaのソースコードは以下になります。ただし、 これらのソースコードはすべて生成系AI(ChatGpt)により作成しているので業務での使用を検討されている方は十分注意してください また、諸事情ですべてpythonの標準ライブラリのみで構成されています。必要に応じてpandasなどの外部ライブラリを使用することをお勧めします
Initialize Lambda(折りたたんであります)
import boto3
def lambda_handler(event, context):
# Create a Connect client using boto3
connect_client = boto3.client('connect')
# List all Amazon Connect instances
try:
instances = connect_client.list_instances()
except Exception as e:
return {
'statusCode': 500,
'body': f"Error listing instances: {str(e)}"
}
# Iterate over each instance and delete it
for instance in instances.get('InstanceSummaryList', []):
instance_id = instance['Id']
try:
connect_client.delete_instance(InstanceId=instance_id)
print(f"Deleted instance: {instance_id}")
except Exception as e:
print(f"Error deleting instance {instance_id}: {str(e)}")
return {
'statusCode': 200,
'body': 'Instances deleted successfully'
}
# For local testing, you can invoke the lambda_handler function
# Remove or comment out this line when deploying to AWS Lambda
# print(lambda_handler({}, {}))
CreateInstance(折りたたんであります)
import boto3
import uuid
import re
def lambda_handler(event, context):
# Create a Connect client using boto3
connect_client = boto3.client('connect')
# Generate a random alias that conforms to the naming rule
random_alias = generate_random_alias()
# Define parameters for creating the instance
params = {
'IdentityManagementType': 'CONNECT_MANAGED',
'InstanceAlias': random_alias,
'InboundCallsEnabled': True, # Set to True or False based on your requirement
'OutboundCallsEnabled': True # Set to True or False based on your requirement
}
# Create the instance
try:
response = connect_client.create_instance(**params)
instance_id = response['Arn'].split('/')[-1] # Extracting the Instance ID from the ARN
return {
'statusCode': 200,
'instanceId': instance_id # Returning the Instance ID for the next step
}
except Exception as e:
return {
'statusCode': 500,
'error': str(e)
}
def generate_random_alias():
# Generate a unique string using uuid4
unique_string = str(uuid.uuid4()).replace('-', '')
# Ensure the alias does not start with 'd-' and follows the naming rule
return re.sub(r'^d-', '', unique_string)
# For local testing, you can invoke the lambda_handler function
# Remove or comment out this line when deploying to AWS Lambda
# print(lambda_handler({}, {}))
CheckInstanceExistence(折りたたんであります)
import boto3
def lambda_handler(event, context):
connect_client = boto3.client('connect')
# Retrieve Instance ID passed from Step Functions
instance_id_to_check = event.get('instanceId')
if not instance_id_to_check:
return {'result': 'Fail', 'error': 'Instance ID not provided'}
try:
# List all instances
response = connect_client.list_instances()
# Check if the specified Instance ID exists
if any(instance['Id'] == instance_id_to_check for instance in response.get('InstanceSummaryList', [])):
# If instance ID exists, check security and routing profiles
security_profile_response = connect_client.list_security_profiles(InstanceId=instance_id_to_check)
routing_profile_response = connect_client.list_routing_profiles(InstanceId=instance_id_to_check)
if security_profile_response and routing_profile_response:
return {'result': 'Success'}
else:
return {'result': 'Fail', 'error': 'One or both profiles are null'}
else:
return {'result': 'Fail', 'error': 'Instance ID does not exist'}
except Exception as e:
return {'result': 'Fail', 'error': str(e)}
countcsvfiles(折りたたんであります)
import os
import boto3
def lambda_handler(event, context):
# 環境変数からS3バケット名を取得
bucket_name = os.environ['BUCKET_NAME']
# S3リソースを初期化
s3 = boto3.resource('s3')
bucket = s3.Bucket(bucket_name)
# バケット内のファイルをリストアップし、最新のCSVファイルを見つける
files = bucket.objects.filter(Prefix='TestFile_')
latest_file = None
latest_date = None
for file in files:
file_date = file.key.split('_')[-1].split('.')[0]
if latest_date is None or file_date > latest_date:
latest_date = file_date
latest_file = file.key
if latest_file is None:
return {"csvcount": []}
# CSVファイルを読み込む
obj = s3.Object(bucket_name, latest_file)
try:
data = obj.get()['Body'].read().decode('utf-8')
except UnicodeDecodeError:
return {"csvcount": []}
# CSVデータを解析し、"No."列の最大値を見つける
max_no = 0
for row in data.split('\n'):
columns = row.split(',')
if len(columns) > 1 and columns[0] == 'No.':
continue
try:
no = int(columns[0])
max_no = max(max_no, no)
except ValueError:
# 列が数値でない場合は無視
pass
# 1から最大値までの文字列リストを生成
string_list = [str(i) for i in range(1, max_no + 1)]
return {"csvcount": string_list}
resultcsvfilecreate(折りたたんであります)
import os
import boto3
from datetime import datetime
def lambda_handler(event, context):
# S3クライアントの設定
s3_client = boto3.client('s3')
bucket_name = os.environ['BUCKET_NAME'] # 環境変数からバケット名を取得
# ファイル名の設定
file_name = f"UserCreateResult_{datetime.now().strftime('%Y%m%d')}.csv"
# S3バケット内にファイルが存在するか確認
try:
s3_client.head_object(Bucket=bucket_name, Key=file_name)
file_exists = True
except:
file_exists = False
# 処理の実行
if file_exists:
# 1-1: ファイルが存在する場合、カラム名のみにリセット
reset_csv(s3_client, bucket_name, file_name)
return "CSVFileReseted"
else:
# 1-2: ファイルが存在しない場合、新しいファイルを作成
create_csv(s3_client, bucket_name, file_name)
return "CSVFileCreated"
def reset_csv(s3_client, bucket_name, file_name):
# カラム名のみのCSVデータを作成
csv_content = "No.,CSVRowNumber,result,UserId,UserArn,errorMessage\n"
write_to_s3(s3_client, bucket_name, file_name, csv_content)
def create_csv(s3_client, bucket_name, file_name):
# カラム名を含む空のCSVデータを作成
csv_content = "No.,CSVRowNumber,result,UserId,UserArn,errorMessage\n"
write_to_s3(s3_client, bucket_name, file_name, csv_content)
def write_to_s3(s3_client, bucket_name, file_name, content):
# S3にファイルを書き込む
s3_client.put_object(Bucket=bucket_name, Key=file_name, Body=content)
# 環境変数の設定例
# os.environ['BUCKET_NAME'] = 'your-bucket-name'
UserCreate(折りたたんであります)
import os
import csv
import boto3
import random
from datetime import datetime
import logging
# Initialize logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
try:
s3_client = boto3.client('s3')
connect_client = boto3.client('connect')
# Get bucket name from environment variable
bucket_name = os.environ['S3_BUCKET_NAME']
target_file = get_latest_file(s3_client, bucket_name)
target_number = event['number']
user_data = get_user_data(s3_client, bucket_name, target_file, target_number)
if user_data:
routing_profile_id = get_random_routing_profile_id(connect_client, event['instanceId'])
security_profile_id = get_random_security_profile_id(connect_client, event['instanceId'])
instance_id = event['instanceId']
if not routing_profile_id or not security_profile_id:
return {"Error": "Missing routing or security profile"}
# Create user in Amazon Connect
create_user_response = connect_client.create_user(
Username=user_data['username'],
Password=user_data['default_password'],
IdentityInfo={
'FirstName': user_data['first_name'],
'LastName': user_data['last_name']
},
PhoneConfig={
'PhoneType': 'SOFT_PHONE',
'AutoAccept': False,
'AfterContactWorkTimeLimit': 0
},
SecurityProfileIds=[security_profile_id],
RoutingProfileId=routing_profile_id,
InstanceId=instance_id
)
return create_user_response
else:
logger.info("No user data found for the given number.")
return None
except Exception as e:
logger.error(f"An error occurred in lambda_handler: {e}")
raise
def get_latest_file(client, bucket):
try:
response = client.list_objects_v2(Bucket=bucket, Prefix='TestFile_')
files = [obj['Key'] for obj in response.get('Contents', []) if 'TestFile_' in obj['Key']]
latest_file = max(files, key=lambda x: datetime.strptime(x.split('_')[1].split('.')[0], '%Y%m%d'))
return latest_file
except Exception as e:
logger.error(f"Error in get_latest_file: {e}")
raise
def get_user_data(client, bucket, file, number):
try:
obj = client.get_object(Bucket=bucket, Key=file)
csv_content = obj['Body'].read().decode('utf-8-sig').splitlines()
rows = csv.DictReader(csv_content)
for row in rows:
if str(row.get('No.')).strip() == number.strip():
return row
logger.info(f"No match found for number: {number}")
except Exception as e:
logger.error(f"Error in get_user_data: {e}")
raise
def get_random_routing_profile_id(client, instance_id):
try:
response = client.list_routing_profiles(InstanceId=instance_id)
routing_profiles = response['RoutingProfileSummaryList']
if not routing_profiles:
logger.error(f"No routing profiles found for instance: {instance_id}")
return None
return random.choice(routing_profiles)['Id']
except Exception as e:
logger.error(f"Error in get_random_routing_profile_id: {e}")
raise
def get_random_security_profile_id(client, instance_id):
try:
response = client.list_security_profiles(InstanceId=instance_id)
security_profiles = response['SecurityProfileSummaryList']
if not security_profiles:
logger.error(f"No security profiles found for instance: {instance_id}")
return None
return random.choice(security_profiles)['Id']
except Exception as e:
logger.error(f"Error in get_random_security_profile_id: {e}")
raise
Register Result(折りたたんであります)
import os
import csv
import boto3
from io import StringIO
from datetime import datetime
def lambda_handler(event, context):
# Get the S3 bucket name from environment variable
bucket_name = os.environ['BUCKET_NAME']
# Set the filename with the current date
today = datetime.now().strftime('%Y%m%d')
filename = f'UserCreateResult_{today}.csv'
# Create an S3 client
s3_client = boto3.client('s3')
# Download the file from S3
try:
csv_file = s3_client.get_object(Bucket=bucket_name, Key=filename)
data = csv_file['Body'].read().decode('utf-8')
except Exception as e:
# Handle exceptions, e.g., if the file does not exist
print(e)
data = ''
# Convert the CSV data to a list of dictionaries
lines = []
fieldnames = ['No.', 'CSVRowNumber', 'result', 'UserId', 'UserArn', 'errorMessage']
# If there is existing data, read it into lines
if data:
reader = csv.DictReader(StringIO(data))
lines = list(reader)
# Find the highest 'No.' value
nos = [int(line['No.']) for line in lines if line['No.'].isdigit()]
max_no = max(nos) if nos else 0
# Process each item in the event
for item in event:
number = item['number']
usercreate = item['usercreate']
result = usercreate.get('result', {})
# Initialize error_message
error_message = ''
# Determine success and extract error message if needed
if 'Payload' in result and 'UserId' in result['Payload'] and 'UserArn' in result['Payload']:
success = 'Success' if result['Payload']['UserId'] and result['Payload']['UserArn'] else 'False'
else:
success = 'False'
# Handle case for error messages
if 'Error' in result:
error = result.get('Error', {})
if isinstance(error, dict):
error_message = error.get('Cause', '')
elif isinstance(error, str):
error_message = error
# Prepare the new row
new_row = {
'No.': str(max_no + 1),
'CSVRowNumber': number,
'result': success,
'UserId': result['Payload'].get('UserId', '') if success == 'Success' else '',
'UserArn': result['Payload'].get('UserArn', '') if success == 'Success' else '',
'errorMessage': error_message
}
# Add the new row to the lines
lines.append(new_row)
max_no += 1
# Convert the lines back to CSV
output = StringIO()
writer = csv.DictWriter(output, fieldnames=fieldnames)
# Write the header
writer.writeheader()
# Write the data rows
writer.writerows(lines)
# Upload the updated file to S3
s3_client.put_object(Body=output.getvalue(), Bucket=bucket_name, Key=filename)
return {
'statusCode': 200,
'body': 'File updated successfully'
}
やってみる
まず、以下のようなcsvファイルを作成します。No.1~9,20~22は登録成功。No.10~19はパラメータが不足 or 不適なのでエラーになります。

StepFunctionsを実行します。ステートマシン全体が正常終了しました。

作成されたcsvファイルをみると、それぞれの実行結果とユーザ情報・失敗理由が記載されています

まとめ
Mapステートを無理やり成功となるように処理したあと、どの配列処理が成功・失敗したのかを把握するのも冪等性の観点からは重要なのではないかと思います。
上記の処理をもとにすれば、登録処理に失敗したユーザだけリストアップして通知を行ったり、パラメータを適宜修正して再実行することも可能になります。
是非参考にしていただければと思います。
Discussion