AWS Panorama + YOLOv5を使用した物体検出


はじめに
AWS Panoramaを使用することがありましたが、日本語での知見がほとんど見当たらなかったため記事としてまとめたいと思います
注意事項
1. フレームワークのバージョンについて
AWS Panoramaはデプロイ時にSageMaker Neoを利用してモデルをコンパイルするため、SageMaker Neoで対応しているフレームワークのバージョンでモデルをトレーニングさせる必要があります
PyTorchはフレームワークは1.7、1.8をサポートしており、モデルは1.7、1.8およびそれ以前のバージョンをサポートと記載されています
通常そのままYOLOv5をインストールした場合最新のPyTorchが入ってしまうためにデプロイ時にエラーが発生してしまいます
AWS Panoramaで正常に読み込めるモデルを生成するためにはPyTorchとPythonのバージョンを固定する必要があるので注意が必要です
2. Panoramaデバイスについて
ディスプレイ出力
アプライアンスの構成に記載がある通り、電源を入れた後にディスプレイを接続してもカメラの映像を出力されません
正常にデプロイが終了して時間が経過しても映像が出力されない場合は一度電源を落とし、ディスプレイを接続し直して電源を入れなおして再確認してみると良いでしょう
登録時のUSBメモリについて
Panoramaデバイスを登録する際にUSBメモリを使う必要があります
セットアップに使うUSBはセキュリティ機能が付いていないもの、パーティション処理が行われていないものを使用した方が良いです
もしPanoramaの登録後、AWS側でPanoramaがオンラインにならないなど、セットアップが正常に完了しない場合は上記のようなUSBメモリからデータをコピーできていない可能性がありますのでUSBメモリを変更した方が良いかもしれません
3. YOLOv5とSiLU関数について
モデルをトレーニングしてPanorama用にエクスポートする場合、こちらのIssueに記載されているようにいくつかの修正が必要です
PyTorchのSiLU関数がランタイムに実装されていないため、そのままトレーニングしたモデルをエクスポートするとPanoramaへアプリケーションをデプロイするときにモデルのコンパイルエラーが発生してしまいます
そのためエクスポート時にPyTorchの活性化関数をYOLOv5のカスタム活性化関数に変更する必要があります
今回の調査に当たりDeploy an Object-Detector Model at the Edge on AWS Panoramaと記事に付随しているリポジトリのノートブックを参考にさせて頂きました
前提条件
- AWS環境を既に準備していること
- AWS Panorama デバイスを所持していること
- 開発環境
- MacまたはLinuxであること
(ARMベースのDockerイメージを作成する必要があるため) - Windowsの場合はWSL2が使用可能であること
- MacまたはLinuxであること
- Python3.8の開発環境が構築済みであること
※Apple Silicon搭載Macの場合は追加手順の部分に構築方法の記載有 - Dockerがインストール済みであること
- USBメモリを所持していること
事前準備
1 Pythonのバージョン確認
インストールされているPythonのバージョンを確認する
3.9以上になるとPyTorch1.8がインストールできないので3.8以下にする
YOLOv5でモデルのトレーニング及びエクスポート時にPython3.8になっていればよいのでpyenvやasdfで特定のディレクトリのみバージョンを指定する形でもよい
> python --version
Python 3.8.10
2 Windowsの場合の追加手順
AWS Panorama Application CLIはMacかLinuxのみサポートと記載されているが、AWSの公式ドキュメントではWindowsでPanoramaアプリケーションを開発するための構築手順も用意されている
2.1 WSL
まずAWS Panorama用のWSLディストリビューションを作成する必要がある
AWSの手順ではUbuntuをそのまま使用していたが、今回は作成後にディストリビューションをコピーしてPanorama専用とする
下記の手順はWSL2の設定は完了し、Ubuntu-22.04のディストリビューションの作成が完了しているものとする
2.2 ディストリビューションのコピー
作成したディストリビューションをエクスポートし、任意の場所にインポートを行う
wsl -l -vでインポートしたディストリビューションが認識されていれば正常に完了している
> wsl -l -v
NAME STATE VERSION
* Ubuntu Stopped 2
Ubuntu-22.04 Stopped 2
Ubuntu-20.04 Stopped 2
> wsl --export Ubuntu-22.04 "【エクスポート先のパス】/Ubuntu-22.04.tar"
エクスポートが進行中です。これには数分かかる場合があります。
この操作を正しく終了しました。
> wsl --import Ubuntu-22.04-Panorama "【インポート】/Ubuntu-22.04-Panorama" "【エクスポート先のパス】/Ubuntu-22.04.tar"
インポート中です。この処理には数分かかることがあります。
この操作を正しく終了しました。
> wsl -l -v
NAME STATE VERSION
* Ubuntu Stopped 2
Ubuntu-22.04 Stopped 2
Ubuntu-20.04 Stopped 2
Ubuntu-22.04-Panorama Stopped 2
2.3 Pythonのインストール
sudo apt update && sudo apt upgrade -y && sudo apt autoremove
sudo apt install unzip python3-pip
2.4 Docker Desktop
公式のドキュメントに従いDocker Desktopをインストール
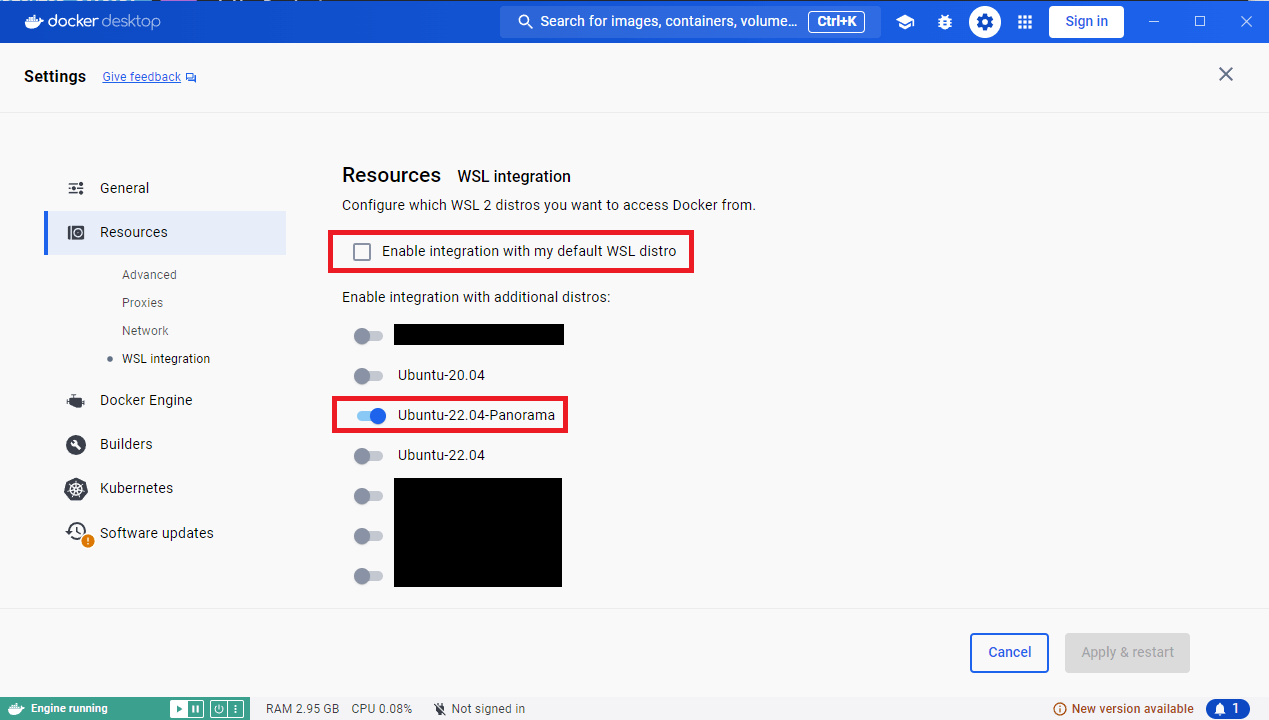
インストール後、右上の歯車アイコンをクリック、「Resources」、「WSL integration」の順にクリック
「Enable integration with my default WSL distro」のチェックを外す
「Ubuntu-22.04-Panorama」にチェック
3 各種ツールのインストール
3.1 AWS CLI
3.1.1-a インストール手順(Mac、Linux)
公式ドキュメントに従いインストールを行う
Windowsの場合はWSL2を使用してインストールを行う必要があるため、先に追加手順を実施しておくこと
3.1.1-b インストール手順(WSL)
AWSの公式ドキュメントに従いインストールを行う
公式ドキュメントではAWS Panorama Application CLIも同時にインストールを行っているため、この手順でも公式に従いインストールしている
pip3 install awscli panoramacli
インストールが終わったらAWS CLIとAWS Panorama Application CLIのバージョンの確認を行う
aws --version
panorama-cli --version
この時command not foundが発生した場合pip show panoramacliを実施してLocationの場所をPATHに追加する
> pip show panoramacli
Name: panoramacli
Version: 1.1.6
Summary: Panorama CLI
Home-page: https://github.com/aws/aws-panorama-cli
Author: AWS Panorama
Author-email:
License: Apache License 2.0
Location: 【ホームディレクトリ】/.local/lib/python3.10/site-packages
Requires: setuptools
Required-by:
export PATH=【ホームディレクトリ】/.local/lib/python3.10/site-packages:$PATH
設定
公式ドキュメントに従い設定を行う
Default output formatをjson以外にしていた場合、原因不明でPanoramaのデプロイ時にエラーが発生したためjsonに設定した方が無難だと思われる
3.2 AWS Panorama Application CLI
3.2.1-a インストール手順(Mac、Linux)
公式のREADMEに従いインストールを行う
pip3 install panoramacli
3.2.1-b インストール手順(WSL)
AWS CLIのインストール時にまとめて実施しているためこちらでは記載しない
3.3 YOLOv5
モデルの取得及びトレーニングのためにインストールを行う
他の環境やSageMakerで学習させる場合は実施不要
Apple Silicon搭載Macは3.3.1を実施すること
Linux及びWindowsの場合は3.3.2から実施すること
3.3.1 Apple Silicon搭載Macの場合の追加手順
Apple Silicon搭載Macの場合、Python3.8のインストーラーが存在しないために通常の手順ではPython3.8をインストールすることができない
そのためAnaconda等を用いてx86-x64版アーキテクチャの仮想環境を構築し、Python3.8をインストールする
conda create -n 【環境名】
conda activate 【環境名】
conda config --env --set subdir osx-64
conda install python=3.8
Pythonのインストールが完了したら作成した仮想環境にJupyterLabをインストール
JupyterLabを起動後にpythonのバージョンが3.8になっていることを確認する
3.3.2 前提ライブラリのインストール
3.3.3のYOLOv5の必要ライブラリインストール時にエラーが発生した場合は都度必要なライブラリを追加でインストールすること
pip install torch==1.8.0 torchvision==0.9.0
pip install numpy # pip install -r requirements.txtでエラーが発生したときのみ対応
3.3.3-a インストール(CPU環境)
公式のREADMEに従いインストールを行う
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt
3.3.3-b インストール(GPU環境)
学習をGPU環境で実施したい場合は以下の手順で行う
注意点
もしGPU環境でYOLOv5のトレーニングを実行時に「ページング ファイルが小さすぎるため、この操作を完了できません」というエラー内容が出た場合は仮想メモリのサイズを大きくする
PyTorch1.8でインストール可能なCUDAのバージョンを確認する
今回はCUDA11.1を使用する
CUDA11.1でインストール可能なcuDNNのバージョンも確認する
使用するバージョンが決まったらCUDAとcuDNNのインストールを行う
CUDA Toolkit 11.1のインストール
cuDNN v8.9.7のインストール
CUDAとcuDNNのインストールおよび環境変数の確認が終わったらYOLOv5のインストールを行う
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt
インストールが終わったら下記コマンドを実行
実行した際にtrueが表示されていればGPU環境でのセットアップが完了している
import torch
print(torch.cuda.is_available())
参考資料
GPU環境のYOLOv5の設定方法は以下のサイトを参考にさせて頂きました
[Python]YOLOv5のGPU環境を構築(まとめ)
CUDA複数バージョンインストール後のシステム環境変数の変更
labelImg(任意)
カスタムモデル作成のためのアノテーションツールをインストールする
他にアノテーションツールがある場合はインストール不要
また、現在labelImgはLabel Studioに機能が集約されているため、Label Studioを使用する形でも良い
インストール
pip installだと何故かpredefined_classes.txtを使用するやり方が上手くいかなかったためソースからビルドする形式を推奨する
トラブルシューティング
1. TypeError: expected str, bytes or os.PathLike object, not NoneType Abortedというエラーが発生する
labelImg.pyの1309行目を修正する
2. unexpected type 'float'というエラーが発生する
labelImgのPythonのバージョンが古いために発生する
labelImg実行時のPythonのバージョンを3.9にするか、canvas.pyとlabelImg.pyを以下のように書き換える
# 526行目
p.drawRect(int(left_top.x()), int(left_top.y()), int(rect_width), int(rect_height))
# 530行目
p.drawLine(int(self.prev_point.x()), 0, int(self.prev_point.x()), int(self.pixmap.height()))
# 531行目
p.drawLine(0, int(self.prev_point.y()), int(self.pixmap.width()), int(self.prev_point.y()))
#965行目
bar.setValue(int(bar.value() + bar.singleStep() * units))
AWS Panoramaの初期設定
1. Panoramaデバイスの登録
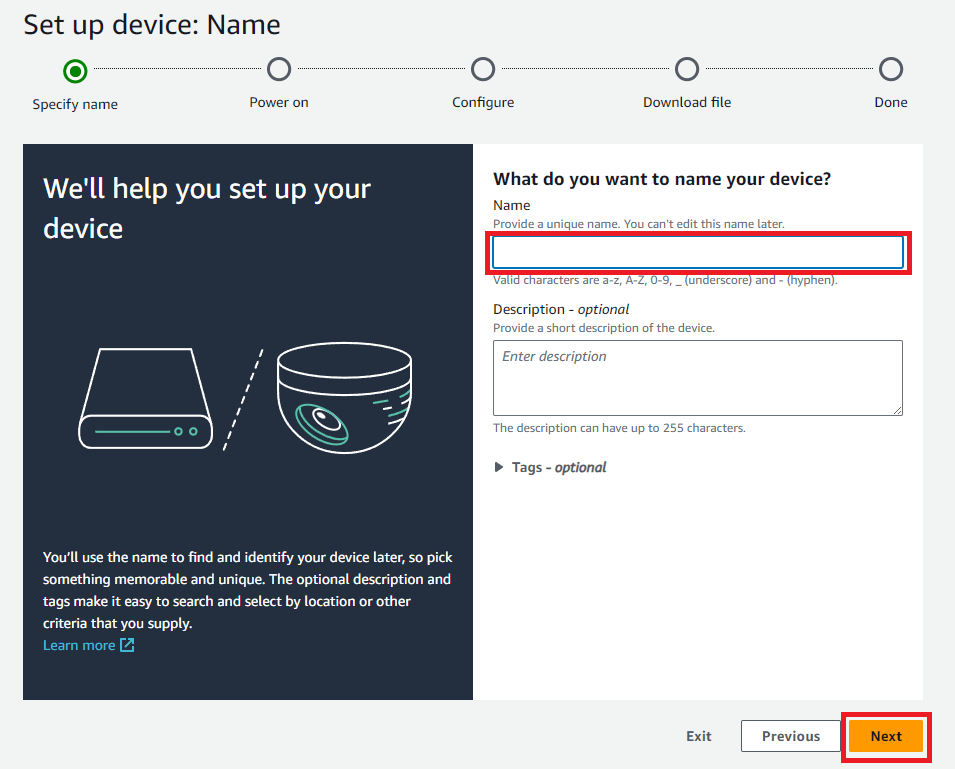
セットアップに従い登録を行う
Nameは任意の名称を入力して「Next」をクリック
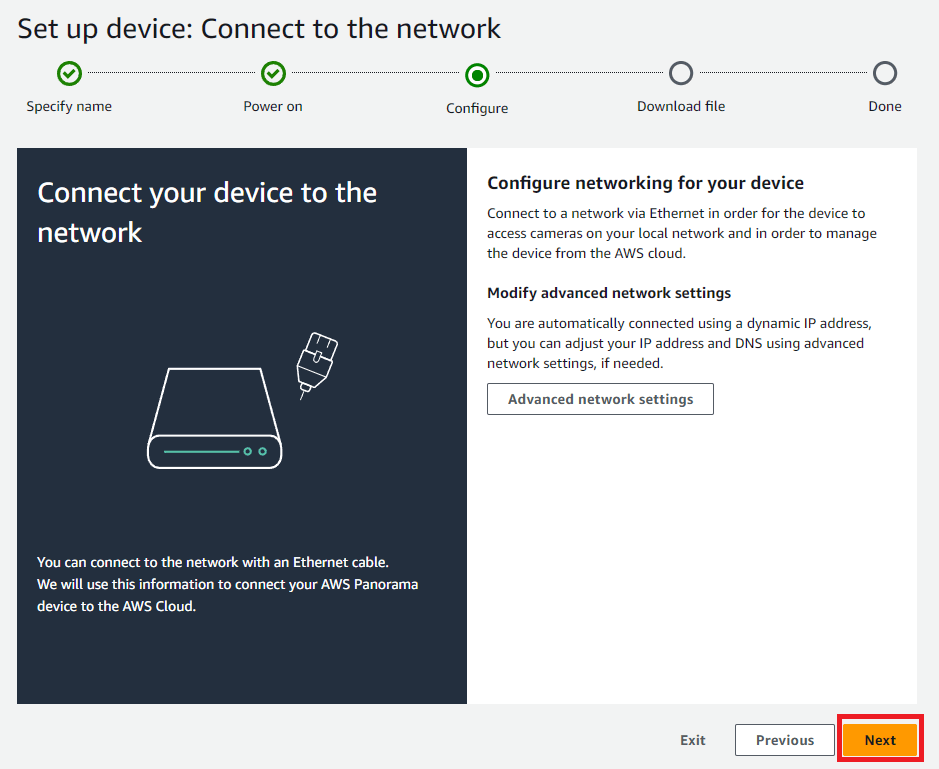
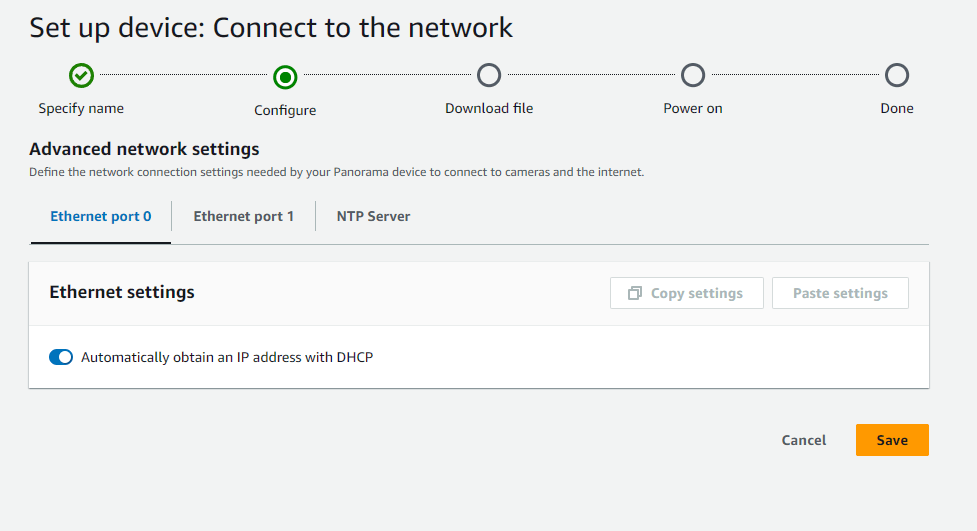
ネットワーク設定はDHCPであればそのまま「NEXT」、固定IPにしたい場合は「Advanced network settings」をクリックして設定を行う
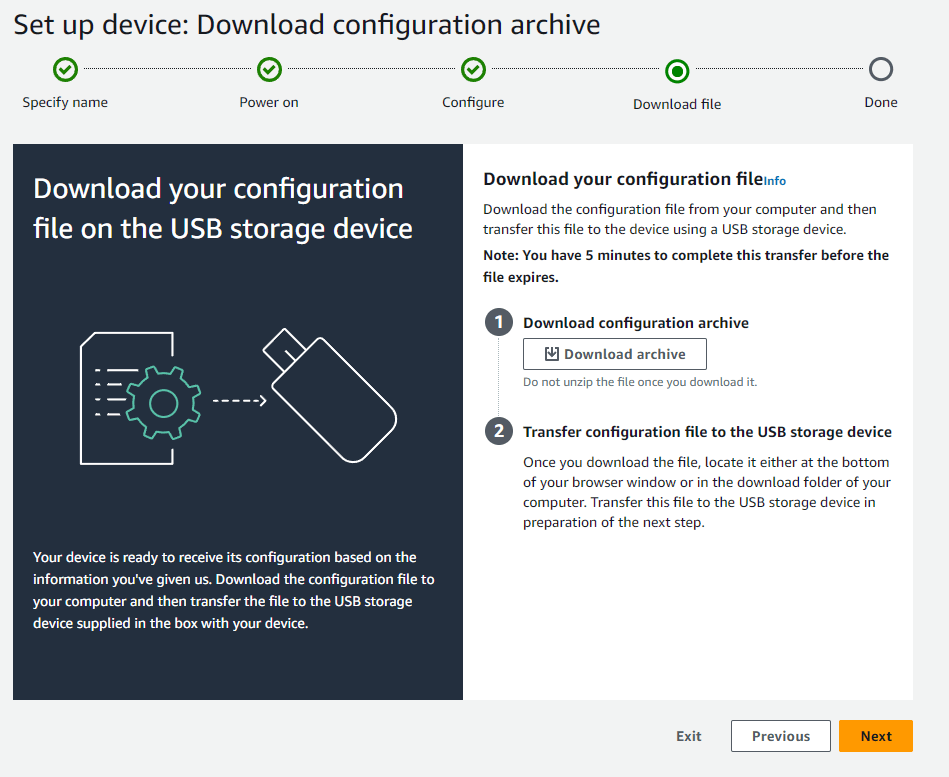
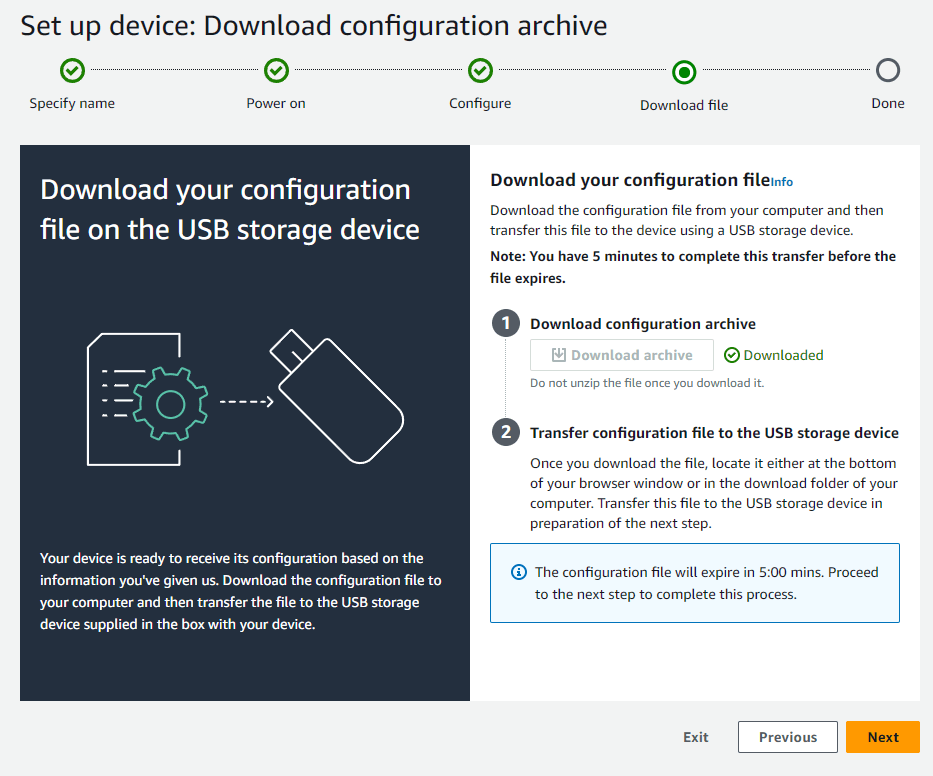
「Downlaod archive」をクリックして証明書をダウンロード
ダウンロードしたファイルは「certificates-xxx_【入力したデバイス名】.zip」という名称になっているのでUSBメモリの直下に格納する
AWS側ではダウンロードが正常に完了したらDownloadedと表示されるので「Next」をクリック
注意
証明書はダウンロードしてから5分間のみ有効
時間が過ぎてしまった場合最初からやり直す必要がある
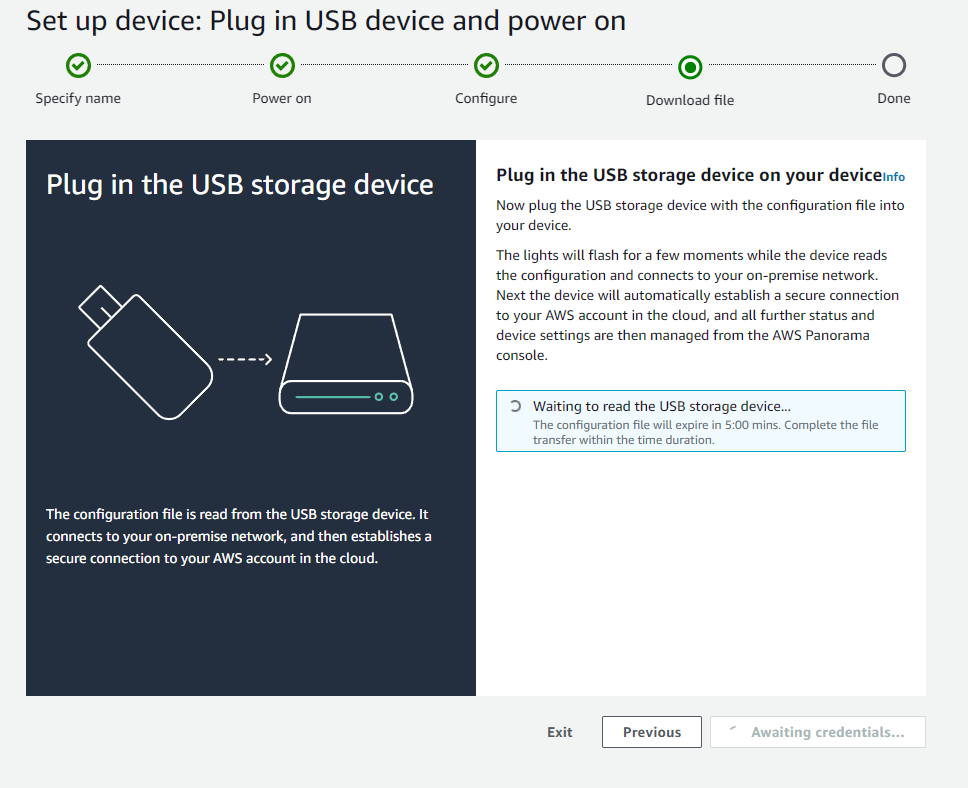
証明書を格納したUSBメモリをPanoramaデバイスに接続
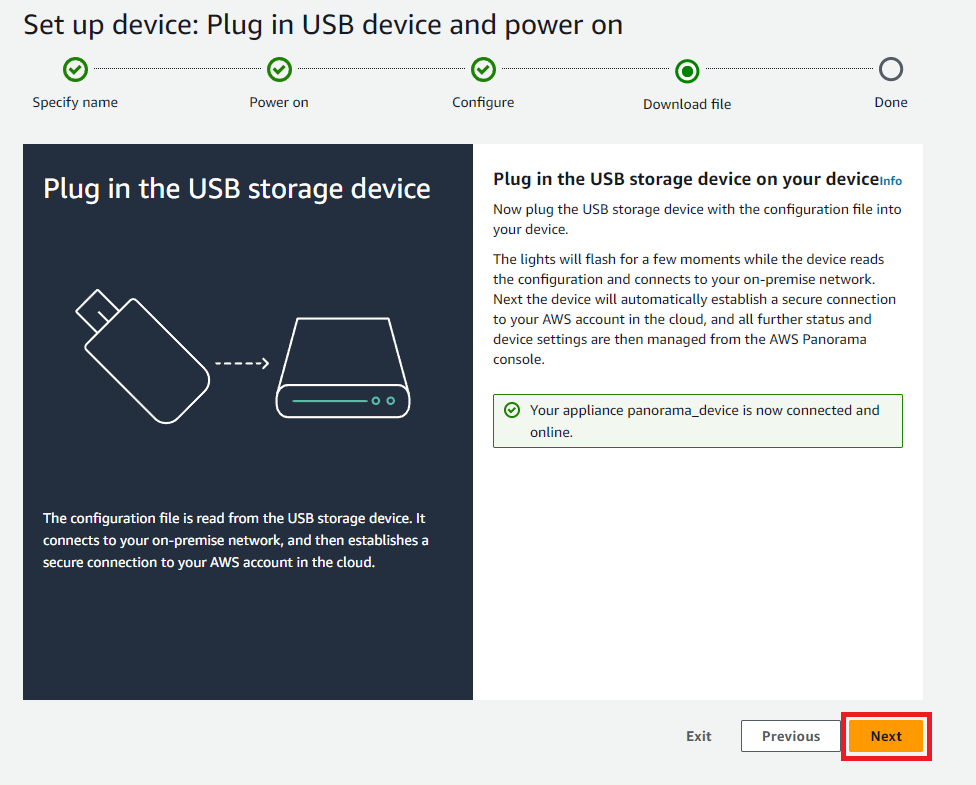
証明書がPanoramaデバイス側で処理され、AWS側に認識されると下記画像2枚目のような状態になるので「Next」をクリック
登録を再度やり直したい場合や証明書が切れた場合
Panoramaデバイスを一度初期化する必要がある
電源が切れている状態でリセットボタンと電源ボタンを5秒以上長押しして起動すると全てのアカウントデータが削除されるので再登録を行う
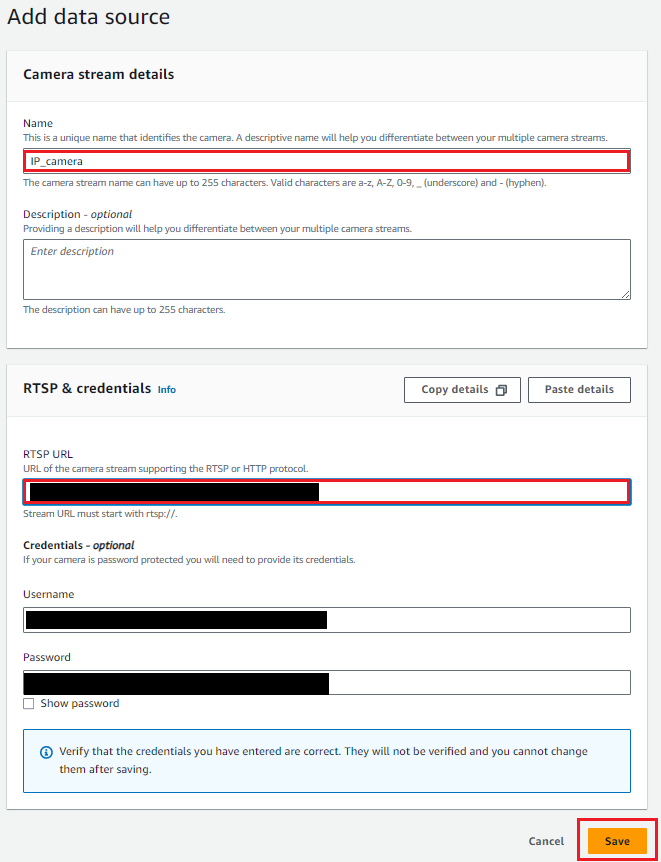
2. カメラの登録
セットアップに従い登録を行う
認証を行っている場合はCredentialsにユーザー名とパスワードを入力する
サンプルアプリケーションのデプロイ
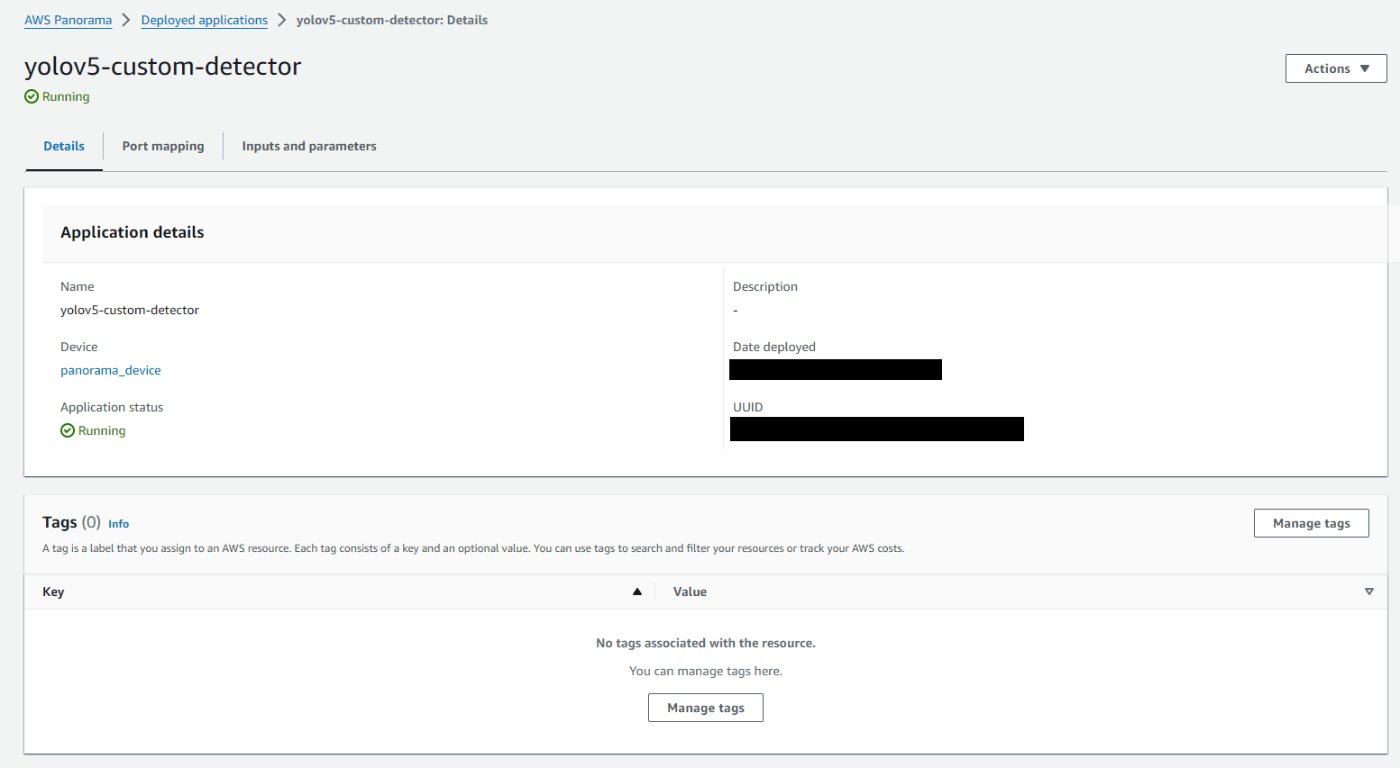
初めにサンプルアプリケーションのデプロイが正常に実施出来るかを確認する
公式のドキュメントに従い、サンプルアプリケーションをダウンロードしてAWS Panoramaにデプロイを行い、Panoramaデバイスに接続したディスプレイに表示されることを確認する
正常にデプロイが完了した場合は以下のように「Application status」がRunningになる
トラブルシューティング
panorama-cli build-containerコマンド実行時に「Container asset for the package has been succesfully~」と表示された場合はコンテナの作成に成功している
それ以外が表示される場合はDockerが起動していない、Dockerの作成に失敗しているなどを確認すること
panorama-cli package-applicationコマンド実行時に「All packages uploaded and registered successfully」と表示された場合はアセットのアップロードに成功している
それ以外が表示される場合はネットワークが途中で切断されている、権限が存在しないなどを確認すること
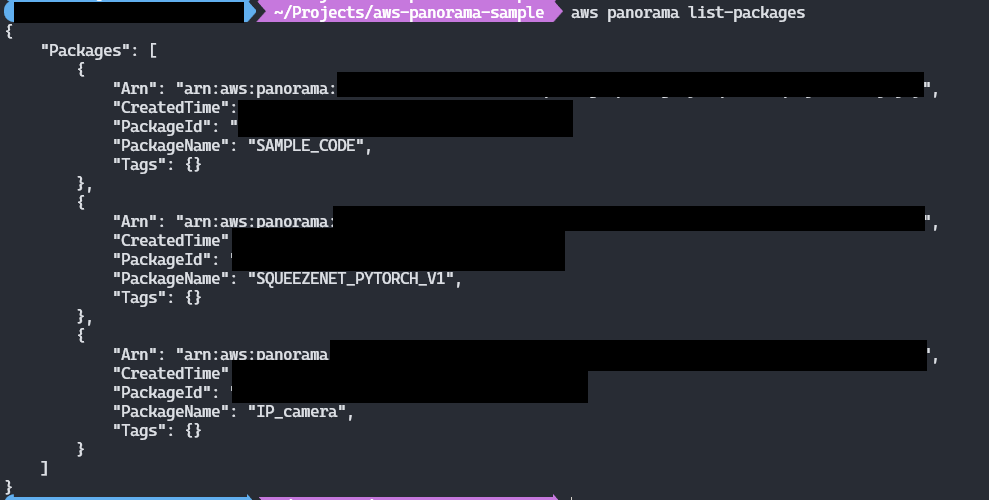
アップロードされたパッケージの確認
S3にアップロードされたパッケージの一覧を確認したい場合はaws panorama list-packagesを使用する
不要になったパッケージはaws panorama delete-package --force-delete --package-id "【PackageId】"で削除することが可能
事前トレーニング済みモデルのデプロイ
次にYOLOv5の事前トレーニング済みモデルをTorchScriptへ変換してサンプルアプリケーションに適用し、Panoramaへアプリケーションのデプロイが正常に実施できるかを確認する
YOLOv5
export.pyの修正
注意事項に記載した通り、モデルをエクスポートする際に活性化関数を変更する必要がある
export.pyを下記のように修正してPyTorchの活性化関数をYOLOv5のものに変更する
from torch.utils.mobile_optimizer import optimize_for_mobile
# 62行目前後
+ import models
+ import torch.nn as nn
+ from utils.activations import Hardswish, SiLU
FILE = Path(__file__).resolve()
f = file.with_suffix(".torchscript")
#156行目前後
+ for k, m in model.named_modules():
+ m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
+ if isinstance(m, models.common.Conv): # assign export-friendly activations
+ if isinstance(m.act, nn.Hardswish):
+ m.act = Hardswish()
+ elif isinstance(m.act, nn.SiLU):
+ m.act = SiLU()
+ # elif isinstance(m, models.yolo.Detect):
+ # m.forward = m.forward_export # assign forward (optional)
+ model.model[-1].export = True # set Detect() layer export=True
ts = torch.jit.trace(model, im, strict=False)
export.pyを修正した後モデルをTorchScriptへ変換する
python export.py --weights yolov5m.pt --include torchscript
# yolov5m.torchscriptをyolov5m.pthに拡張子を変更した後実施
tar vczf yolov5m.tar.gz yolov5m.pth
サンプルアプリケーション
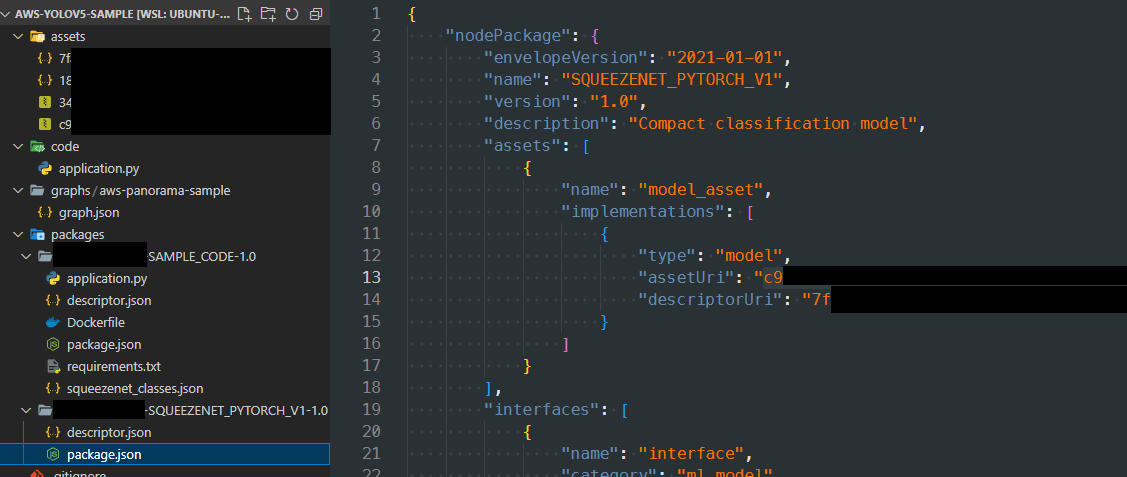
モデルのインポート
YOLOv5でエクスポートしたモデルをインポートする
ACCOUNT_IDに代入していない場合は先に代入する
# 実施していなければ先に実施する
ACCOUNT_ID=$(aws sts get-caller-identity --output text --query 'Account')
panorama-cli add-raw-model --model-asset-name model_asset --model-local-path 【モデルの格納先パス】/yolov5m.tar.gz --descriptor-path 【アプリケーションの格納先パス】/aws-panorama-sample/packages/${ACCOUNT_ID}-SQUEEZENET_PYTORCH_V1-1.0/descriptor.json --packages-path 【アプリケーションの格納先パス】/aws-panorama-sample/packages/${ACCOUNT_ID}-SQUEEZENET_PYTORCH_V1-1.0
インポートが正常に終了した場合は下記の図のようにassetsフォルダ内のファイルとモデルのパッケージフォルダ内のpackage.jsonのURLが置き換わっている
アプリケーションの修正
置き換えたモデルを読み込むようにアプリケーションを修正する必要がある
# 19行目
- self.MODEL_DIM = 224
+ self.MODEL_WIDTH = 640
+ self.MODEL_DIM = (self.MODEL_WIDTH, self.MODEL_WIDTH)
# 99行目
- inference_results = self.call({"data":image_data}, self.MODEL_NODE)
+ inference_results = self.call({"images":image_data}, self.MODEL_NODE)[0]
# 161~163行目
- def preprocess(img, width):
+ def preprocess(img, input_size):
"""Resizes and normalizes a frame of video."""
- resized = cv2.resize(img, (width, width))
+ resized = cv2.resize(img, (input_size[0], input_size[1]))
packages/${ACCOUNT_ID}-SQUEEZENET_PYTORCH_V1-1.0ディレクトリ内のdescriptor.jsonもモデルに合わせて修正する
{
"mlModelDescriptor": {
"envelopeVersion": "2021-01-01",
"framework": "PYTORCH",
"inputs": [
{
"name": "images",
"shape": [ 1, 3, 640, 640 ]
}
]
}
}
デプロイ
サンプルアプリケーションと同様にデプロイする
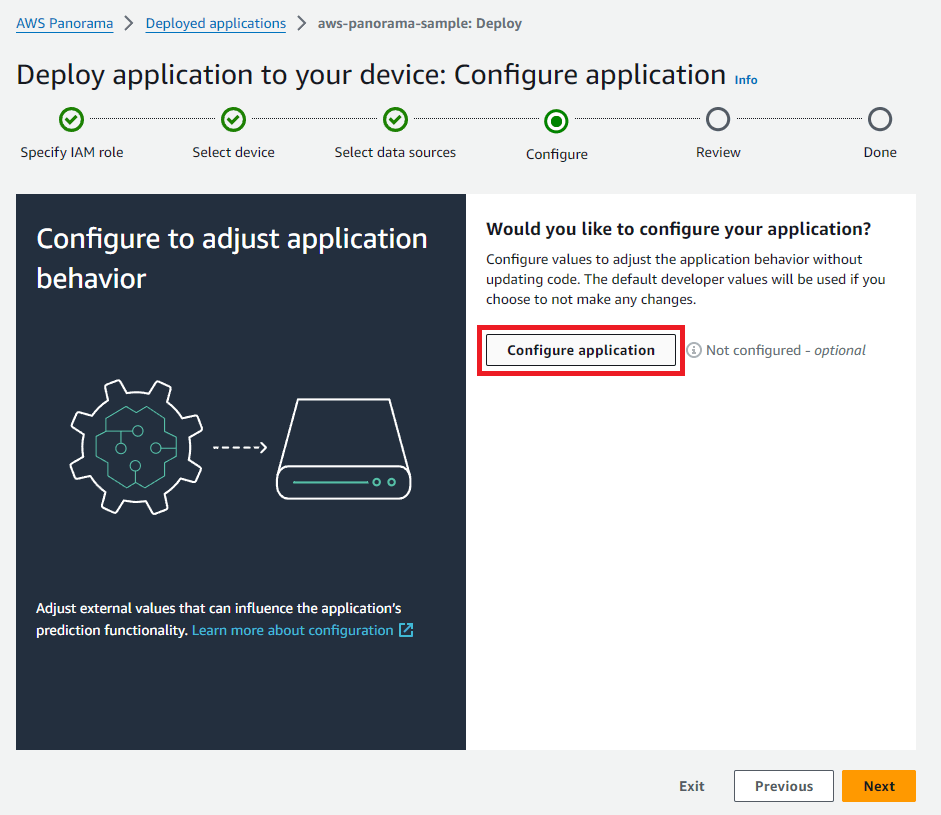
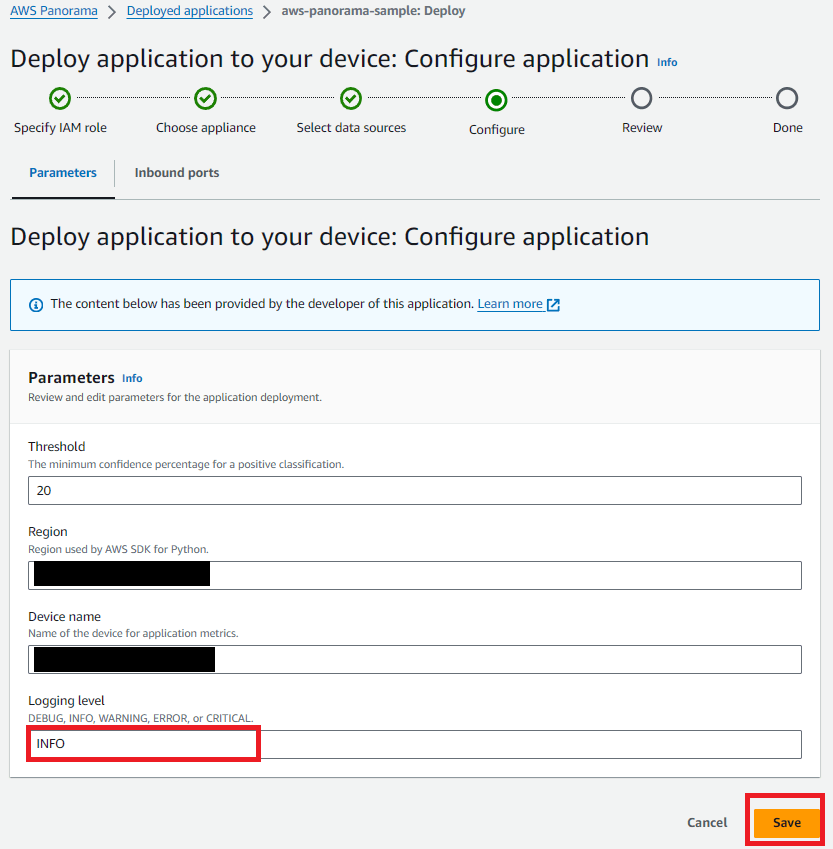
デバッグログを出したい場合は「Configure」で「Configure Application」をクリックして「Logging level」を「DEBUG」に変更する
トラブルシューティング
デプロイエラーになった場合に、エラー部分にカーソルを合わせて「Model compilation failed.」のような表示が出た場合はSageMaker Neoでコンパイルできないモデルになっている可能性がある
デプロイ後にエラーになった場合はCloudWatchにエラーが出力されている可能性がある
「Error」をクリック後にCloudWatchに遷移できるのでエラーを確認する
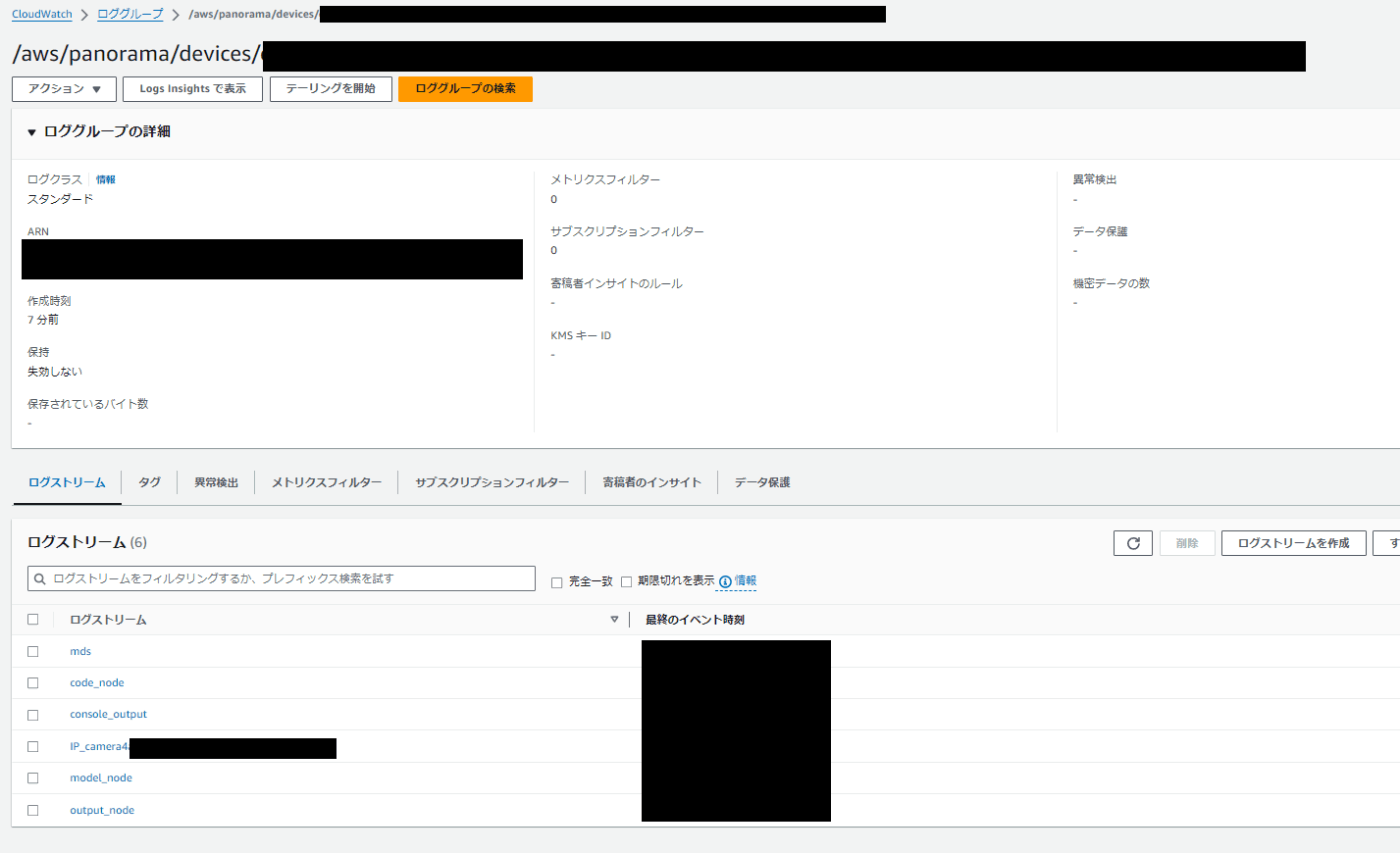
各ログストリームはこのような分類になっている
model_node、code_node、output_nodeはアプリケーション作成時にgraphs/aws-panorama-sample/graph.jsonで指定した名称が使用されるため、他の名称になる場合もある
- console_output: コンソールログ
- model_node: モデルのログ
- code_node: アプリケーションログ
- output_node: 映像出力時のログ
- 【使用したカメラのdata source名】: カメラのログ
- mds: アプライアンスメタデータサーバーからのログ(とのこと)
エラー時にcode_nodeが存在しない場合、アプリケーションの起動自体に失敗している可能性が高い
その場合はconsole_outputを確認すること
code_nodeが存在している状態でエラーが発生する場合、コーディングエラーの可能性がある
その場合はcode_nodeを確認する
RTSPのURLが誤っているなどカメラ入力にエラーが発生している場合は【使用したカメラのdata source名】のログストリームを見ることで確認が可能
複数検出
サンプルアプリケーションは一番指標が高いかつ閾値を越えた一つだけ表示するようになっている
こちらを閾値を越えたもの全て表示するように変更する
かつ、ボックス表示をYOLOv5のものを使用するようにする
アプリケーションの修正
名称変更
前の手順でアップロードしたパッケージと分けるため、アプリケーション名とパッケージ名を変更する
VSCodeなどで一括置換をすること
また、ディレクトリ名にも書かれているため忘れずにディレクトリ名も変更しておくこと
- aws-panorama-sample
→yolov5-custom-detector - ${ACCOUNT_ID}-SAMPLE_CODE
→${ACCOUNT_ID}-CUSTOM_DETECTOR - ${ACCOUNT_ID}-SQUEEZENET_PYTORCH_V1
→${ACCOUNT_ID}-YOLOV5_PYTORCH_MODEL
YOLOv5からgeneral.pyとmetrics.pyの移植・修正
YOLOv5の以下のファイルをpackages/${ACCOUNT_ID}-CUSTOM_DETECTOR-1.0/utils配下に格納する
- utils/general.py
- utils/metrics.py
移植後、不要な関数を削除する
今回はutils.generalのnon_max_suppression関数とその関数で使用しているutils.metricsのbox_iou関数以外を削除する
修正例はこちらにアップロードしている
application.py
インポート部分とprocess_results関数を修正する
修正例はこちらにアップロードしている
graph.json
detection_thresholdの値を20から0.25あたりに変更する
"name": "detection_threshold",
"interface": "float32",
- "value": 20.0,
+ "value": 0.25,
"overridable": true,
"decorator": {
"title": "Threshold",
"description": "The minimum confidence percentage for a positive classification."
}
requirements.txt
application.pyのインポートを追加したので必要なライブラリをインストールする
boto3
opencv-python
+ torch
+ torchvision
+ pandas
+ ultralytics
Dockerfile
詳細を失念してしまったがpip install時に追加したパッケージのビルドに必要だったため以下のライブラリのインストールを追加している
もしかしたら不要なライブラリもあるかもしれない
FROM public.ecr.aws/panorama/panorama-application
WORKDIR /panorama
COPY . .
+ RUN apt update && apt install -y --no-install-recommends build-essential libssl-dev libffi-dev python-dev python3-dev gcc python3.7-dev
RUN pip install --no-cache-dir --upgrade pip && \
pip install --no-cache-dir -r requirements.txt
アップロード
修正が終わったらアセットをビルド・アップロードする
panorama-cli build-container --container-asset-name code_asset --package-path packages/${ACCOUNT_ID}-CUSTOM_DETECTOR-1.0
panorama-cli package-application
デプロイ
正常にアップロードが完了したらアプリをデプロイする
既にアプリケーションをデプロイしている場合は「Delete from Device」で削除してからデプロイすること
モデルのトレーニング・デプロイ
上記が成功したら最後にカスタムモデルをインポートしてアプリケーションのデプロイを行う
モデルのトレーニング
YOLOv5の事前トレーニング済みモデルをトレーニングなどを実施してカスタムモデルを作成する
詳細はここでは記載しない
作成後にTorchScriptへ変換する
python export.py --weights custom.pt --include torchscript
# custom.torchscriptをcustom.pthに拡張子を変更した後実施
tar vczf custom.tar.gz custom.pth
カスタムモデルのインポート
作成したモデルをインポートする
# 実施していなければ先に実施する
ACCOUNT_ID=$(aws sts get-caller-identity --output text --query 'Account')
panorama-cli add-raw-model --model-asset-name model_asset --model-local-path 【モデルの格納先パス】/custom.tar.gz --descriptor-path 【アプリケーションの格納先パス】/yolov5-custom-detector/packages/${ACCOUNT_ID}-YOLOV5_PYTORCH_MODEL-1.0/descriptor.json --packages-path 【アプリケーションの格納先パス】/yolov5-custom-detector/packages/${ACCOUNT_ID}-YOLOV5_PYTORCH_MODEL-1.0
デプロイ
正常にアップロードが完了したらアプリをデプロイする
既にアプリケーションをデプロイしている場合は「Delete from Device」で削除してからデプロイすること
最後に
物体検出ライブラリは初めて扱いましたが、手軽に学習させることができるのがとても良いと思いました
ただしYOLOv5はAGPL-3.0ライセンスなので業務などで使用する場合は注意が必要です
モデルのトレーニング関連は省略してしまった内容が多いので後々追記したいと思います
Discussion