押さえておきたいプログラムの仕組み
こんにちはシムディ合同会の開発チームです。
OS関連で勉強した備忘録です。(間違いもあるかもしれませんのでご容赦下さい。) 全部は書ききれないので押さえておきたいポイントだけをメモ。
本記事の図や例はコンピュータアーキテクチャの名著パタヘネを参考にして書いてます。
1 プロセスとは
プロセスとは実行されたプログラムの存在のことを指す。よくjobとかtaskとか言われることもあるが、基本的にはprocessと同じと考えて良い。例えば、AWSbatchでjobを渡すという表現をよくするが、それはつまりプログラムを実行する=プロセスを実行させるのと同義。
プロセスはソースコード(binary code)、入力・出力(fileとか)、状態/コンテキストから構成される。コンテキストとはプロセス実行中の状態のことで以下のような情報を指す。
・プログラムカウンタ
⇨実行している命令が格納されたメモリのアドレス。
・registerの値
⇨計算途中のCPUにある値
・変数
⇨計算途中にメモリに退避されている変数の値
つまり、プロセスを理解しようとしたらプログラムがどのように動いているのかを理解する必要がある。
2 プログラムの仕組み
例えば、以下のようなソースコードはコンピュータ上でどのように処理されるか?
int main(void)
{
···
sample();
···
}
void sample(void)
{
printf("Hello World.\n");
}
上記のCファイルはコンパイルされてメモリにロードされると下左図のように命令が一行ずつ上から順にメモリに格納された形になる。
1つのプロセスは右図のようにtext領域、静的領域、heap領域、stack領域に分けてメモリを使用している。(他にも予約済みで使えない領域もある。実際はページングという手法でメモリを最適化しているため、1プロセスが使うメモリ空間は細かく刻まれた上で、メモリ上に飛び飛びに保存されている。)
メモリにロードされるCのプログラムは上記のメモリ空間のうち、text領域と呼ばれる場所にバイナリコードとしてロードされる。プログラムはこのtext領域の命令を上から順に実行していき、現在実行されている命令のアドレスをprogram counterと呼ぶ。program counterは通称PCと略されてレジスタが値を保持している。
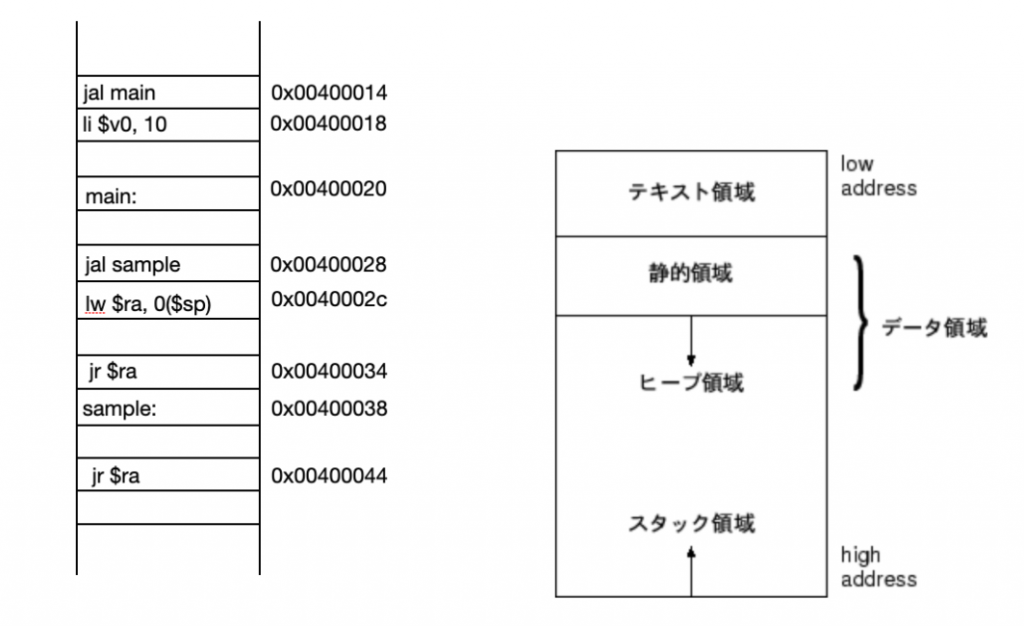
ちなみに、静的領域はグローバル変数とか長さを予め定義した配列などが格納される。heap領域はプログラム動作中に動的に確保されるものでmalloc等が該当する。stack領域はユーザーからの操作はできず、プログラム進行に応じてローカル変数等の一時退避に使われる。
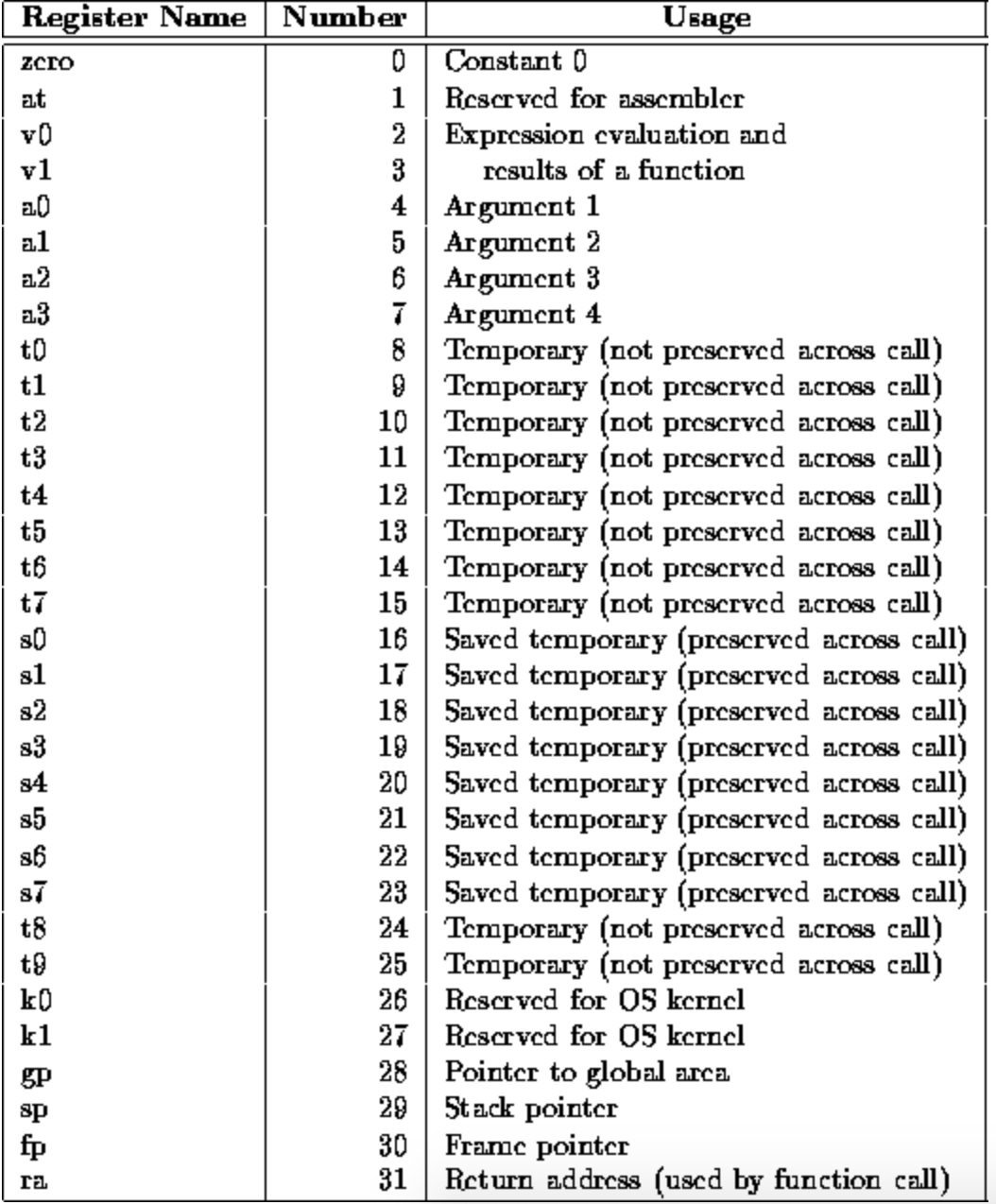
プログラムはtext領域にロードされた命令セットを上から(低位から)順番に実行して動いている。ただし、一命令ごとに毎回メモリから変数等のデータをCPUにロードするには時間がかかってしまうため、計算に必要な変数等はある程度registerと呼ばれるメインメモリとは別のCPU内部のメモリにロードしつつ演算を進めていくことになるregisterの構成はCPUのアーキテクチャーによって変わるが以下に示すのはMIPSと呼ばれる命令セット・アーキテクチャー。
MIPSのregisterは32本あって、一本辺り32bitの長さがある。64bitのパソコンだとこれが64bitの長さになる。詳しくはパタヘネを読みましょう。
registerは32本の中で役割が分かれている。例えば、s番のregister(s0,s1,s2,s3…)は変数の保存用、t番のregister(t0,t1,t2,t3…)は一時保存用など。この$t0みたいな記号はレジスタのある一本に該当する名前。(下図参照)
registerとメモリを使った簡単な計算の方法を以下に示す。
(例1)
f = (g + h) - (i + j);
register上では以下のように計算される。(g,h,i,jは$s1,$s2,$s3,$s4に割り付けられてる場合)
add $t0, $s1, $s2
add $t1, $s3, $s4
sub $s0, $t0, $t1
(例2)
A[12] = h + A[8];
register上では以下のように計算される。(Aのポインタが$s3,$s2にhが割り付けられてる場合)
lw $t0, 32($s3) #load word
add $t0, $s2, $t0
sw $t0, 48($s3) #store word
では先ほどのサンプルコードもう一度以下に示す。関数が呼ばれると命令アドレスが連続ではなくなるため工夫が必要。そこで$ra(return address)と$spを使ってやりくりする。
int main(void)
{
···
sample();
···
}
void sample(void)
{
printf("Hello World.\n");
}
register上では以下のように計算される。
jal main #jump and link $raに次の命令のアドレスを割り当てる
li $v0, 10
.
.
.
main:
.
.
.
jal sample #jump and link $raに次の命令のアドレスが割り当てる
lw $ra, 0($sp) #load word
.
.
.
jr $ra #jump register
sample:
.
.
.
jr $ra #jump register
処理の順番
- jal mainでmainの処理のアドレスにジャンプする。この時、jal mainの一個次のアドレスを$raに割り付ける。
- main関数の何かしらの処理を行う。
- jal sampleでsampleの処理のアドレスにジャンプする。この時、jal sampleの一個次のアドレスを$raに割り付ける。
- sample関数の何かしらの処理を行う。
- sample関数の処理が終わり、$raに割り付けておいたアドレスに戻る。
- main関数の処理が終わり、$raに割り付けておいたアドレスに戻る。
しかし、上記の処理順番だけだと以下の問題が発生する。
・関数に引数を渡している場合、その値を書き換えると参照元の変数も書き換わってしまう。 (そもそもregisterの数に限りがあって上位関数の変数をいちいち保持していられない。)
・関数が入れ子になると$raの値が上書きされて戻り先がわからなくなってしまう。
そこでstack pointerの登場!
入れ子の関数の処理にジャンプする時に呼び元の関数の情報(ローカル変数と$ra)をメモリのstack領域に一時退避させる。stack領域はプログラム実行中に動的に使用量が変わるのでheap領域と同様に領域の大きさが可変であり、アドレスの高い方から低い方に向かって伸びて行く。registerが現在扱っているstack領域のアドレスをstack pointer($sp)と呼ぶ。また、関数が使っているstack領域の始発点をframe pointer($fp)と呼ぶ。
例えば以下のようなプログラムがあるとすると、(このコードでは>>error: ‘a’ undeclaredのエラーを吐く。説明は下記。)
#include <stdio.h>
int sample()
{
printf("%i",a);
return 0;
}
int main()
{
int a = 3;
sample();
return 0;
}
下図のようにメモリの値が操作される。
上記のプログラムはsample関数内でaが宣言されてないというエラーが出るが、これはmain関数からsample関数に移行したあとはsampl関数内でmain関数のstack領域を参照しないからである。(詰まるところ、ローカル変数のスコープ外ということ。)
下図は上記のエラーが出ない(つまりsample関数内で変数aを使わない)場合の処理イメージ。

まずローカル変数はstack領域のmain関数が使う領域に保持される。この時、registerに保持されている$fpと$spのアドレスがmain関数の使用するstack領域となる。次にmain関数内でsample関数が呼び出される。この時、registerに割り当てられている$fp、$spは一旦stack領域に退避される。そしてsample関数からreturnされる時に再びregisterにloadされる。
処理の順番(main関数内の変数が$a0に割り付けられてるとする。)
- stack pointerを1個下にずらす。
- main関数を呼び出した関数(caller)のframe pointerを退避する。
- stack pointerをmain関数のframe pointerとする。
- stack pointerを3個下にずらす。
- frame pointerの1個下にaの値を退避する。
- frame pointerの2個下にreturn addressの値を退避する。
- Sample関数の処理実行。
- ローカル変数$a0を復活させる。
- 古い$raを復活させる。
- 古いframe pointerを復活させる。
では、最後にもう1例。
int fact(int n)
{
...
}
int comb(int n, int k)
{
return fact (n) / fact (k) / fact (n - k);
}
register上では以下のように計算される。ただし、comb関数の中身のみ記載。
comb:
addi $sp, $sp, -4 #stack pointerを1個下にずらす。
sw $fp, 0($sp) #comb関数を呼び出した関数のframe pointerを退避。
move $fp, $sp #comb関数のframe pointerをセット。
addi $sp, $sp, -12 #stack pointerを3個下にずらす。
sw $ra, -4($fp) #return addressを退避。
sw $a0, -8($fp) #comb関数のローカルn変数を退避。
sw $s0, -12($fp) #comb関数のローカルk変数を退避。
jal fact #fact(n)実行。
move $s0, $v0 #fact(n)の結果を$s0に割り付け。
lw $a0, 12($sp) #引数kをregisterにロード。
jal fact #fact(k)実行。
div $s0, $s0, $v0 #fact(n)/fact(k)を計算
lw $a0, 8($sp) #引数nをregisterにロード。
lw $a1, 12($sp) #引数kをregisterにロード。
sub $a0, $a0, $a1 #n-kを計算。
jal fact #fact(n-k)を実行。
div $s0, $s0, $v0 #(fact(n)/fact(k))/fact(n - k)を計算。
move $v0, $s0 #returnの値を$v0に割り付け。
lw $s0, -12($fp) #ローカルk変数を復元。
lw $ra, -4($fp) #$raを復元。
addi $sp, $fp, 4 #$spを復元。
lw $fp, 0($fp) #$fpを復元。
jr $ra #comb関数のcallerにreturn。
結論
プログラムがどうやって動くのか、アセンブリとCPUのレジスタの観点で説明した。
プロセスのコンテクスト(実行中に刻々と変わる情報)として、プログラムカウンター、stack pointerやローカル変数やregisterの値などが存在する。これらのプロセス情報がOSのプロセス管理で重要になってくる。
自社プロダクト開発、システム開発の請負やってます。
開発チームにご参画いただける方やお仕事のご依頼などお気軽にお問い合わせください。
Discussion