やりたいこと
Microsoft Fabricにログインして、ワークスペースを作成すると「タスクフロー」を選択する画面になります。
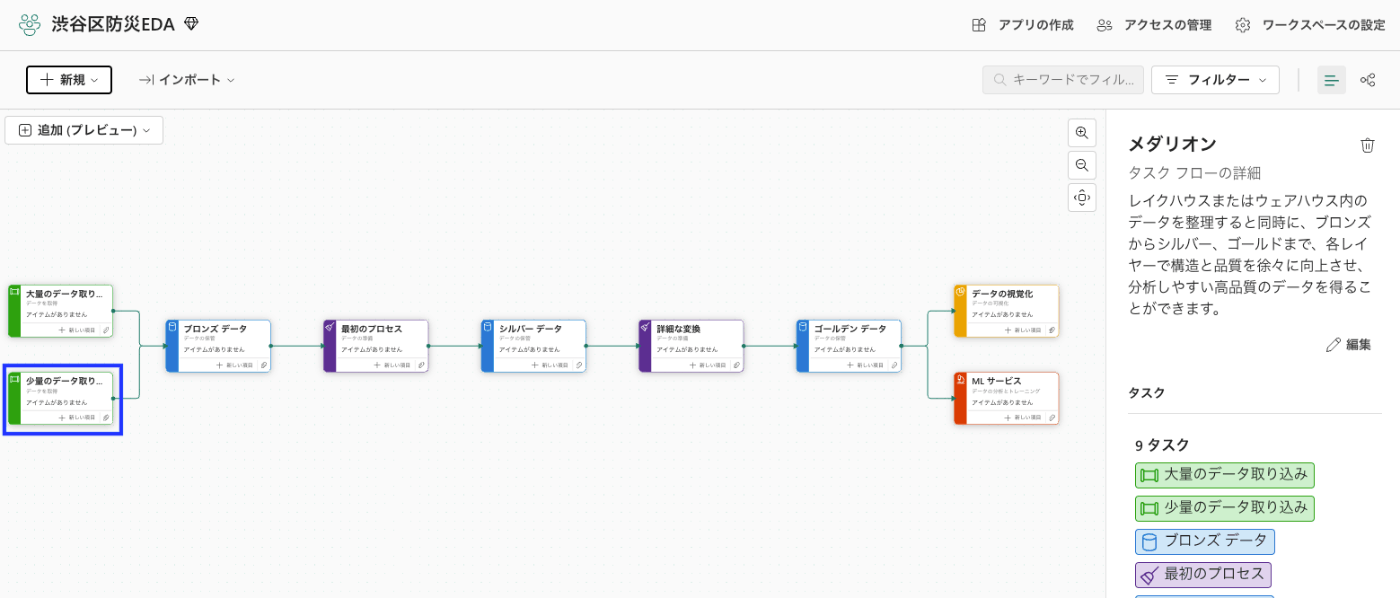
そこで、「メダリオン」というタスクフローがあったので、作成されたタスクに沿ってデータ分析をしてみようかなと。
長くなりそうなので、データ取り込みからシルバーデータ作成までを試そうかと。

タスクフロー選択
Fabricにログインしてワークスペースを作成したら、タスクフローが選択できるので、メダリオンを選んでみる。

データ取り込み
取り込むデータ
今回はSHIBUYA OPEN DATA(渋谷区のオープンデータ)から防犯に関するデータを取り込んで試してみる。
ざっと眺めていると、刑法犯数とパトロールの指導実績というデータがありそうだったので、
この2つに相関があるかみてみたいと。

アイテム選択と追加

タスクの右下にある「新しい項目」を選択すると、そのタスクでの推奨アイテムが出てきます。
今回は外部サイトのCSVを一度取り込むため、データフロー(Gen2)を選択しました。


これで、データが取り込めたようです。
データの保管

次にブロンズデータのアイテム選択をします。
こちらはブロンズレイヤーのためレイクハウスを選択しました。

レイクハウス作成

bronz_hanzaiというレイクハウスを作成しました。
で、レイクハウス側でもデータ取得(pull)ができるのですが、先ほどデータフローでデータ取得したので、そのデータを同期させます。
データを同期する
データ取り込みをしたアイテムで「データ同期先の追加」で、作成したレイクハウスを選択します。


同期ができたら、画面の右下でデータ同期されているのが分かります。

ブロンズのデータを確認する

「最初のプロセス」での推奨タスクはノートブックかデータフローかがあり、
タスクの位置的にはブロンズとシルバー層の間なので、データ整形などを行うところだと思いますが、まずは取り込んだデータをノートブックで確認かと思い、ノートブックを選択しました。

ノートブックでレイクハウスを選択して、データ確認をしていきます。

なんとなく、刑法犯数が別地域でも同じ数字だったので、データが怪しいのかと思って確認しましたが

そこまでおかしいこともないのかなと思いました。たまたまソートの都合で同じ刑法犯数が並んだだけかなと。

という感じでデータを見ましたが、特に重複しているレコードや欠損データを埋めるとかも必要なさそうだったので、そのままシルバー層にデータを入れれば良さそうかなと。
duplicate_rows = df[df.duplicated()]
print(duplicate_rows)
通報を埋めようかとも思いましたが、まー使わないかと思ったので、スルー。

シルバーデータ作成

まず、今回はELT的なことをしなくても良さそうなので、データ取り込み→ブロンズへ保管の流れと同様にレイクハウス作成、データフローのデータ同期で良さそうです。
ただ、仮にノートブックでデータ変換をしてシルバーへ保管する際に、ノートブックで作成したテーブルをそのままシルバーのレイクハウスに保存したかったのですが、レイクハウスまたぎのデーブル保存がよくわからなかったので、ここは要調査かなと。
(レイクハウスの切り替えはできるけど、ノートブック側でのレイクハウスの指定方法が不明)

と思ったら、パスのコピーを指定して、レイクハウスを指定する方法がありました。

# ブロンズのTableを読み込む
df_bronz = spark.read.format('delta').load(f'abfss://xxxxx@onelake.dfs.fabric.microsoft.com/xxxxx/Tables/hanzai_num')
df_bronz.show()
# シルバーのパスを指定する
silver_layer_table_path = "abfss://xxxxx@onelake.dfs.fabric.microsoft.com/xxxxx/Tables/silver_hanzai_num"
# Deltaフォーマットでシルバー層のテーブルにデータを書き込む
df_bronz.write.format("delta").mode("append").save(silver_layer_table_path)
これで、シルバー層にデータ保管ができました。

まとめ
シルバー層へのデータ保管までのざっくりとした流れを試してみました。
次は、シルバーからゴールドのざっくりした流れを試します。

Discussion
Fabricってゴールドまでいけるんでしたっけ?
もちろんいけるかと。
返信ありがとうございます!