やりたいこと
AdvancedRAGのPlaygroundのようなOSSがあったので、試してみます。
Azure系のリソースに接続してローカルでKnowlege GraphやGraphRAGなどが試せそうです。
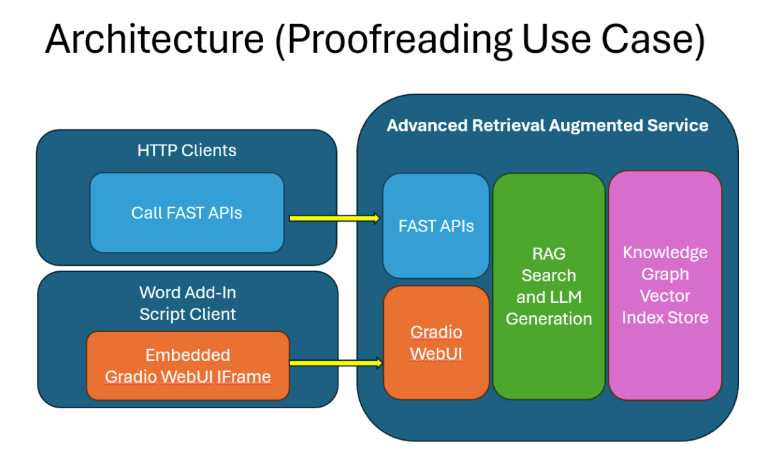
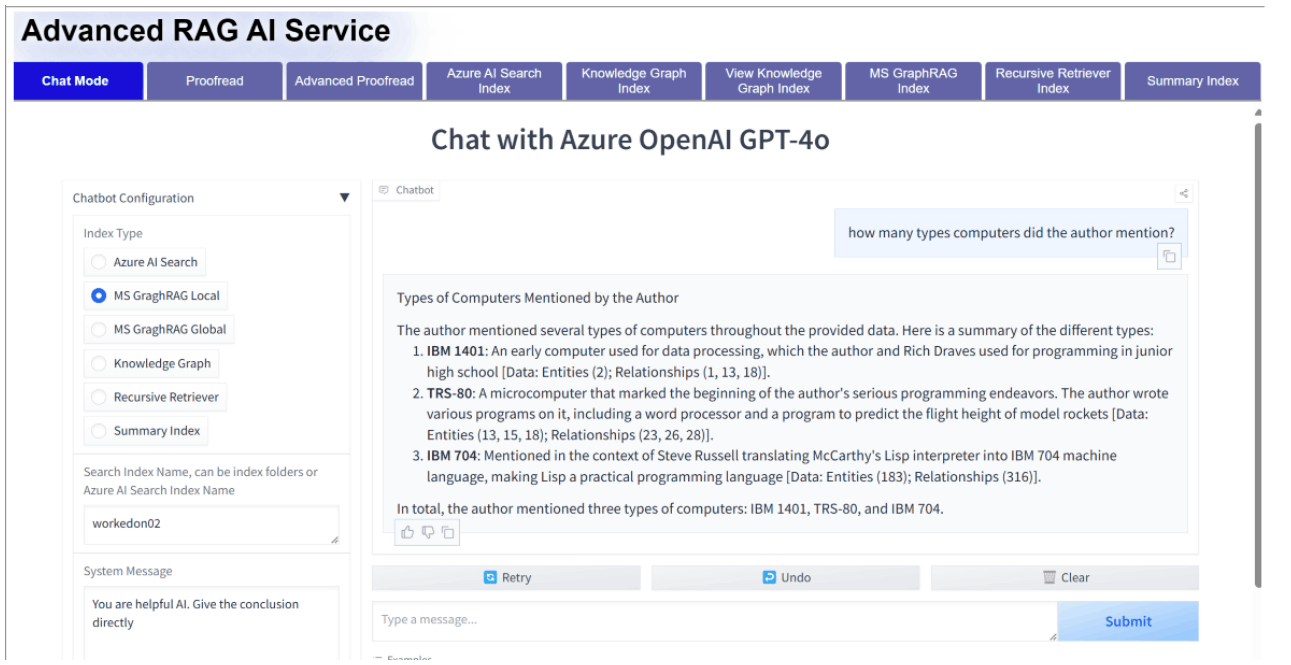
こんな感じで、お手軽にAdvancedRAGの方針検討ができたら良さげだなと。
使うための準備
ReadmeのQuick Startを試します。
とりあえずクローン
IMPORTANT: Rename .env.sample to .env, input necessary environment variables.
環境変数に設定をする。下記のような感じで、色々使えそう。
#Azure OpenAI Setting
AZURE_OPENAI_API_KEY=
AZURE_OPENAI_Deployment=gpt-4o-mini
AZURE_OPENAI_EMBEDDING_Deployment=text-embedding-3-small
AZURE_OPENAI_ENDPOINT=https://[name].openai.azure.com/
AZURE_OPENAI_API_VERSION=2023-05-15
# Don't modify the following
OPENAI_API_VERSION=2023-12-01-preview
OPENAI_API_TYPE=azure
# Azure Document Intellenigence
DOC_AI_BASE=https://[name].cognitiveservices.azure.com/
DOC_AI_KEY=
#Azure AI Search
AZURE_SEARCH_ENDPOINT=https://[name].search.windows.net
AZURE_SEARCH_API_KEY=
AZURE_SEARCH_API_VERSION="2023-11-01"
USE_SUB_QUERY_ENGINE = False
・・・
Azure OpenAI resource and Azure Document Intelligence resource are must required.
AOAIは必須。
Azure AI Search is optional if you don't build Azure AI Search index or use it.
AI Searchはオプション
MS GRAPHRAG is optional. If you want to use it please go through these steps to create GraphRAG backend service on Azure: https://github.com/azure-samples/graphrag-accelerator
GraphRAGもオプションでできるみたい
オプションのキーなどは下記の表。
docker imageをビルドして、実行
docker build -t docaidemo .
docker run -p 8000:8000 docaidemo
にアクセスするとgradioで作ったっぽいUIのアプリが開きます。
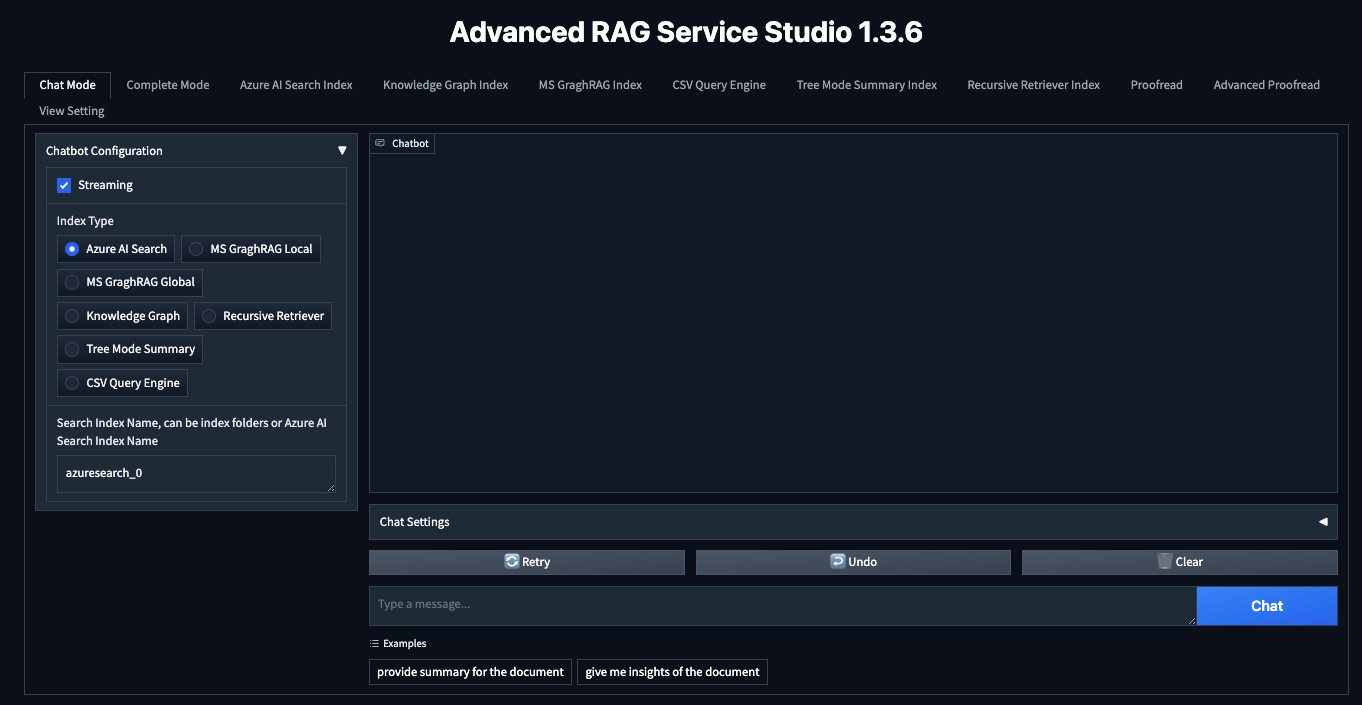
試す
Azure OpenAI Serviceの設定しかしていないので、一番簡単そうな「CSV Query Engine」というタブで試します。
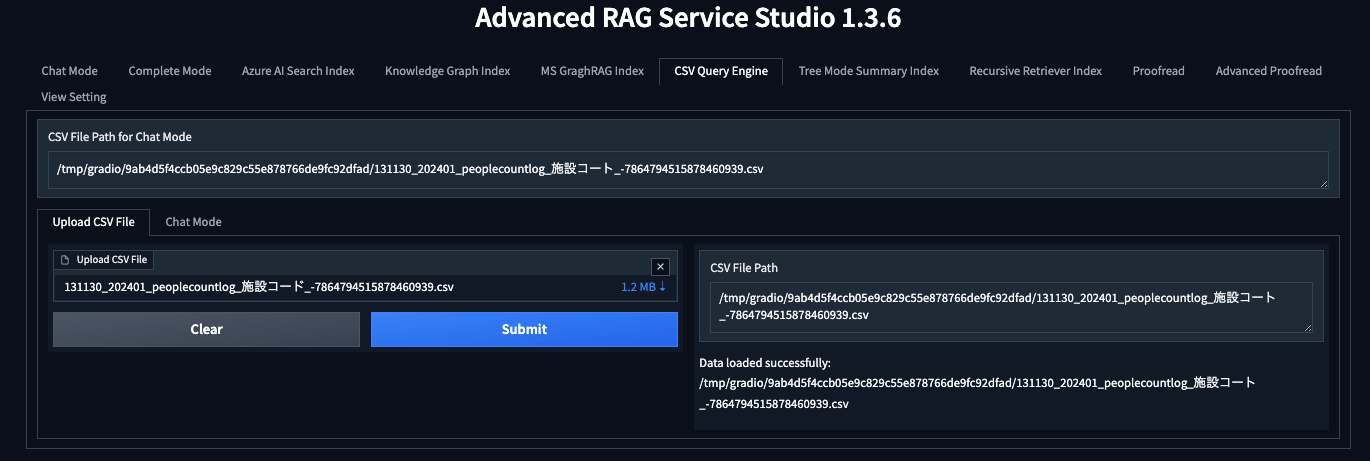
CSVのファイルをアップロードします。
なんとなく、SHIBUYA OPEN DATAの2024/1の施設利用のCSVをあげました。
適当にcsvに書いてあることを質問すると、それっぽく答えてくれました。
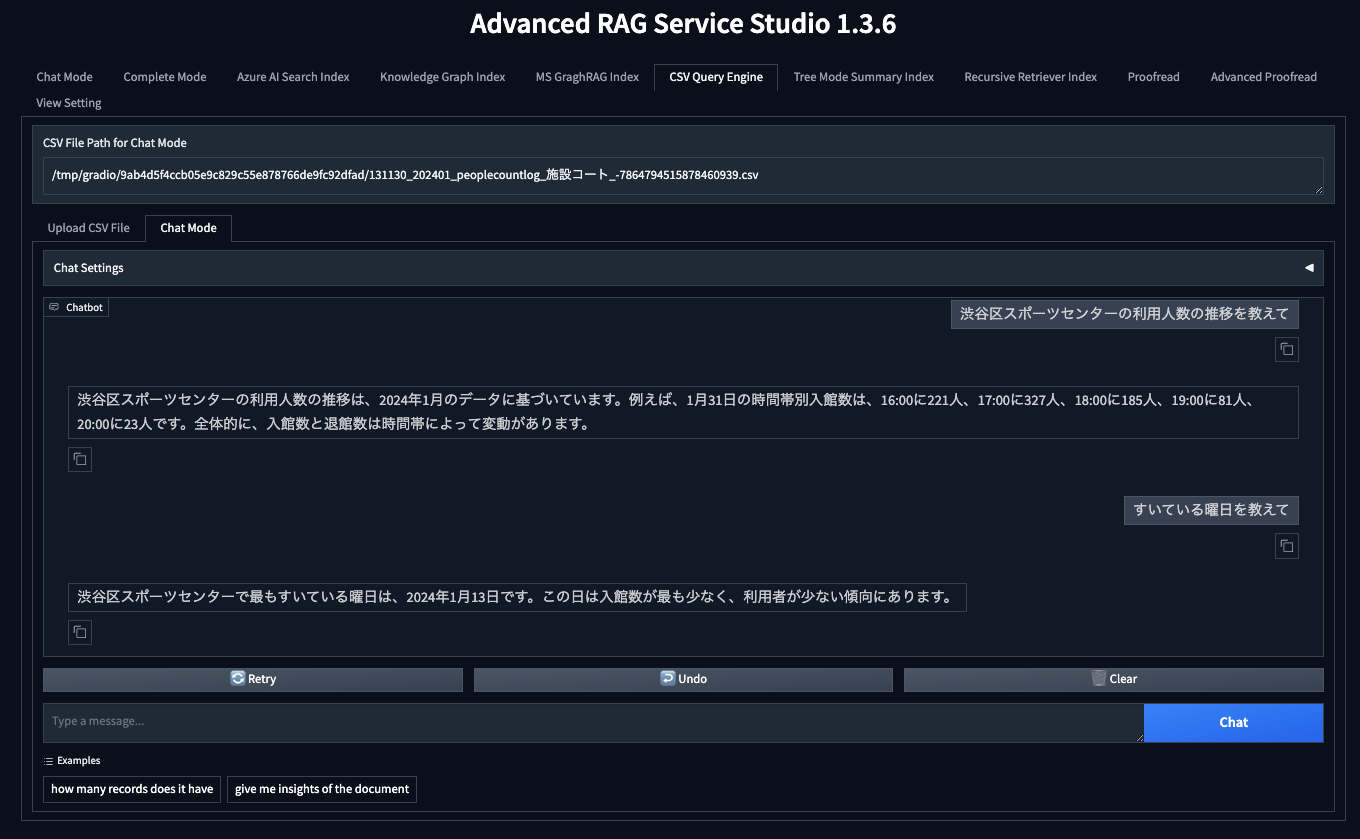
ログを見ると、コードを実行した結果から回答してくれてそうです。
df[df['施設名称'] == '渋谷区スポーツセンター'][['日時', '入館数', '退館数']].groupby('日時').sum()
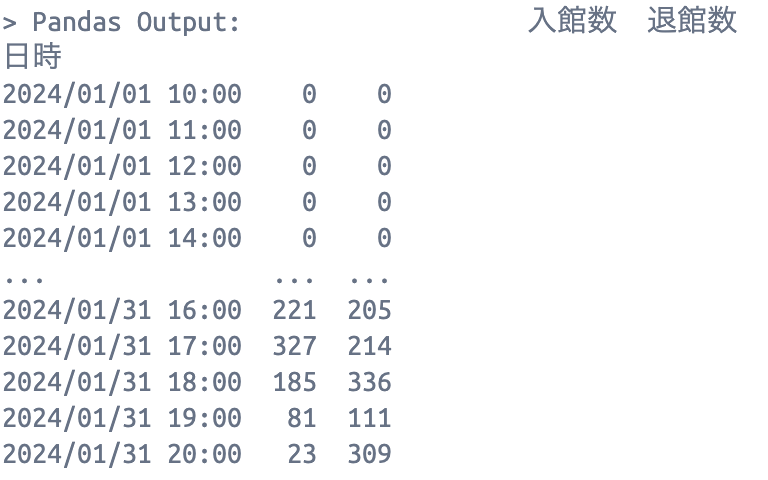
df[df['施設名称'] == '渋谷区スポーツセンター'].groupby(df['日付']).agg({'入館数': 'sum'}).idxmax()
Pandas Output: 入館数 2024/1/13
曜日ではなく、日付を返してくれましたが、まー元データに曜日入ってないからなと。
まとめ
本当はGraphRAGをやりたかったのですが、下記のデプロイが必要とのことで、
こっちを先にやろうかなと。

Discussion