AzureのOCR、特に帳票認識といえばDocument Intelligenceですが、AI FoundryでMistral OCRが使えるぞとアップデートがあったので、適当に帳票認識のモデルを試してみます。

mistral-document-ai-2505というのを選択してみます。
カタログスペックでは、GeminiやAzure OCRよりも上で、日本語にも対応しているようです。

健康診断書のダミーデータをGPTで作成して読み取ってみます。

健康診断書
氏名
2025年1月15日
| 項 目 | 機査結果 |
|---|---|
| 身 長 | 172.4 cm |
| 体 重 | 68.2 kg |
| BMI | 22.9 |
| 視力(右) | 1.2 |
| 視力(左) | 128 / 82 mmHg |
| 心電図 | 異常なし |
| 尿検査 | 異常なし |
| 肝機能 | 19 U/L |
| 血糖 | 92 mg/L |
| 総コレステロール | 192 mg/dL |
| HDLコレステロール | 61 mg/dL |
| 中性脂肪 | 84 mg/dL |
| 判定 | A 特に異常は読めません |
さくらクリニック
document intelligence -read
健康診断書
氏名
受診日
2025年1月15日
検査結果
項 目
172.4 cm
体重
68.2 kg
BMI
22.9
視力(右)
1.2
視力(左)
128 / 82 mmHg
異常なし
異常なし
尿検査
19 U/L
肝機能
92mg/L
血糖
192mg/dL
HDLコレステロール
84 mg/dL
中性脂肪
判定
A 特に異常は認めません
さくらクリニック
総コレステロール
61 mg/dL
身長
document intelligenceのReadだと項目が不明だが、値はあっていそう。
mistral ocrは項目の値の読み取りはミスなし。
名前がちゃんと記載されていないのは画像通りで良い。

健康診断書
検査日 令和7年3月10日
受診者 山田 太郞
生年月日 1960年 8月25日
| 項目 | 給 累 |
|---|---|
| 身 具 | 168.5 cm |
| 体 重 | 71.2 kg |
| 視 力 | 1.0 |
| 血 圧 | 136/88 mmHg |
| 心電図 | 異常なし |
| 肝機能(AST/ALT) | 肝機能に改善の余地あり |
| 血 糖 | 25/32 U/L |
| 総コレステロール | 102 mg/dL |
| HDLコレステロール | 198 mg/dL |
| 中性脂肪 | 62/140 mg/dL |
| 判 定 | B |
document intelligence - read
健康診断書
検査日 合和7年3月10日
受診者 山田
太郎
生年月日 1960年8月25日
項目
給 果
身 長
168.5 cm
体 重
71,2 kg
視 力
1.0
血 圧
136/88 mmHg
心電 図
異常なし
肝機能(AST/ALT)
肝機能に改善の余地あり
血 糖
25 / 32 U/L
給コレステロール
102 mg/dL
HDLコレステロール
198 mg/dL
中性脂肪
62 / 140 mg/dL
判定
B
平成 医院
document ingelligenceはドットがカンマになったり、表記揺れも気になるのと、Readだと項目が不明。
mistral orcは項目の値の読み取りはミスなし。
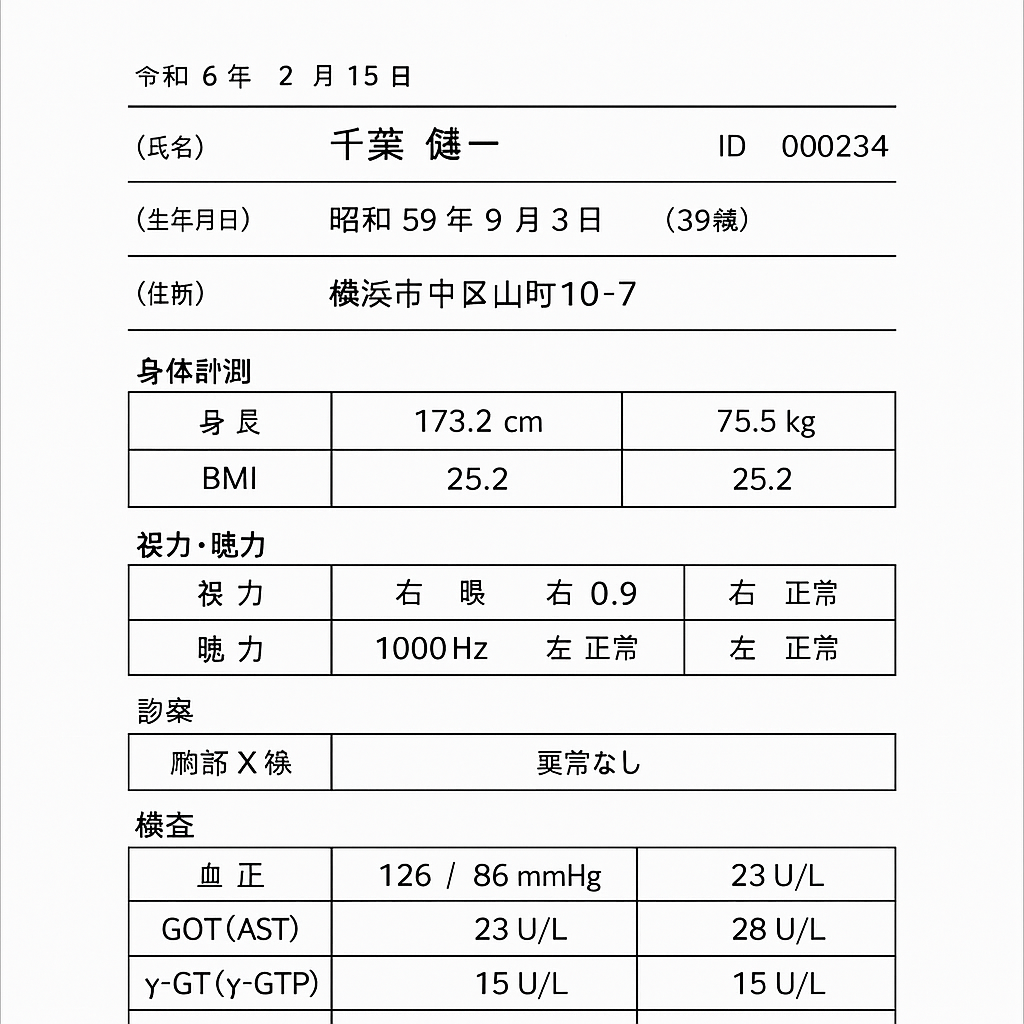
令和6年2月15日
(氏名) 千葉 健一 ID 000234
(生年月日) 昭和59年9月3日 (39襖)
(住所) 横浜市中区山町10-7
身体計測
| 身 炅 | 173.2 cm | 75.5 kg |
| BMI | 25.2 | 25.2 |
視力・聴力
| 視 力 | 右 眼 右 0.9 | 右 正常 |
| 聴 力 | 1000 Hz 左 正常 | 左 正常 |
診察
| 胸部 X 㼁 | 要常なし |
橫査
| 血 正 | 126 / 86 mmHg | 23 U/L |
| GOT(AST) | 23 U/L | 28 U/L |
| γ-GT(γ-GTP) | 15 U/L | 15 U/L |
これは元の画像がよくわからないが、ちゃんと読めていそう

2024年4月15日 氏 名 平田 健二
生年月日 診査年齢:1979年10月44歳
| 検 査 項 目 | 検査結果 | 検 査 項 目 |
|---|---|---|
| 体 重 (cm) | 170.0 cm | 右 右 1.2 |
| B M 重 | 68.5 kg | 早 見 |
| 射 M | 23.7 | 波 射 |
| 聴射(右 右) | 1.2 | 耳剃り |
| 聴射(左 右) | 異常なし | 心拍血圧 |
| 換 圧 圧 | 130 mmHg | 低血圧 |
| AST (GOT) | 21 U/L | AST |
| ALT (GPT) | 23 U/L | ALT |
| γ-GTP | 38 U/L | γ-GTP |
| LDLコレステール | 125 mg/dL | LDLコレステール |
| HDLコレステール | 72 mg/dL | HDLコレステール |
| 糖尿病 代謝 | 85 mg/dL | 共鶏足症 |
画像はカラムの中にカラムがあるよくわからない画像だったので、一部無視された。
JSON Schemaを定義したものを見ると、ちゃんと間違っている生年月日のconfidenceが0.5だった。
血圧がちゃんと取れていて良さそう。
{
"name": {
"value": "平田 健二",
"confidence": 1.0
},
"date_of_birth": {
"value": "1979年10月44日",
"confidence": 0.5
},
"height_cm": {
"value": 170.0,
"confidence": 1.0
},
"weight_kg": {
"value": 68.5,
"confidence": 1.0
},
"bmi": {
"value": 23.7,
"confidence": 1.0
},
"vision": {
"value": "右: 1.2, 左: 1.2",
"confidence": 1.0
},
"hearing": {
"value": "右: 異常なし, 左: 異常なし",
"confidence": 1.0
},
"blood_pressure": {
"value": "130/82 mmHg",
"confidence": 1.0
},
"hdl_cholesterol": {
"value": 72,
"confidence": 1.0
}
}

健康診断証明書
| 番 号 | 012345 |
|---|---|
| 氏 名 | 佐藤 太郎 |
| 生年月日 | 昭和60年4月10日 |
| 榜査項目 | 結 果 |
| 身 長 | 172.3 cm |
| 体 重 | 68.5 kg |
| 視 力 | 1.2 |
| 聴 力 | 正 |
| 胸部X線 | 正常 |
| 血 圧 | 正常 |
| G P T | 21 |
| 血 糖 | 92 |
上記の通り健康診断を実施したことを証明します
○○病院 院長 山田 匡師
検査結果のカラムの値が無視されている。。読み取り項目は指定した方が良さそう。
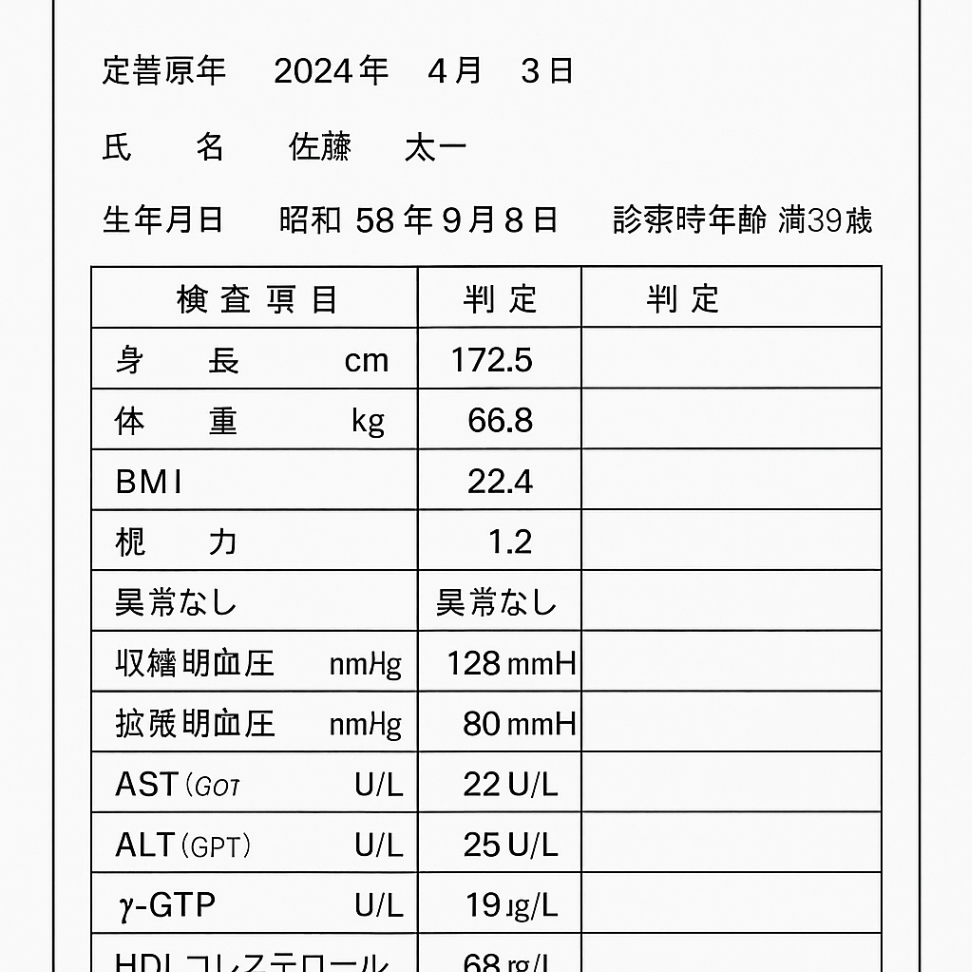
定普原年 2024年 4月 3日
氏 名 佐藤 太一
生年月日 昭和58年9月8日 診察時年齢満39歳
| 検 査 現 日 | 判 定 | 判 定 |
|---|---|---|
| 身 長 cm | 172.5 | |
| 体 重 kg | 66.8 | |
| BMI | 22.4 | |
| 根 力 | 1.2 | |
| 異常なし | 異常なし | |
| 収縮 明血圧 nmHg | 128 mmH | |
| 拡 緻 明血圧 nmHg | 80 mmH | |
| AST(GOT U/L | 22 U/L | |
| ALT(GPT) U/L | 25 U/L | |
|
|
19 |
|
| HDL コレステロール | 68 |
document intelligence - prebuild-layout
Extracted Fields
Table 1
- (0, 0): 定着原年
- (0, 1): 2024年 4月 3日
- (1, 0): 氏 名
- (1, 1): 佐藤 太一
- (2, 0): 生年月日
- (2, 1): 昭和 58年9月8日
Table 2
- (0, 0): 検査 項 目
- (0, 1): 判定
- (0, 2): 判定
- (1, 0): 身 長 cm
- (1, 1): 172.5
- (1, 2):
- (2, 0): 体 重 kg
- (2, 1): 66.8
- (2, 2):
- (3, 0): BMI
- (3, 1): 22.4
- (3, 2):
- (4, 0): 視 力
- (4, 1): 1.2
- (4, 2):
- (5, 0): 異常なし
- (5, 1): 異常なし
- (5, 2):
- (6, 0): 収縮明血圧 nmHg
- (6, 1): 128 mmH
- (6, 2):
- (7, 0): 拡張明血圧 nmHg
- (7, 1): 80 mmH
- (7, 2):
- (8, 0): AST (GOT U/L
- (8, 1): 22 U/L
- (8, 2):
- (9, 0): ALT (GPT) U/L
- (9, 1): 25 U/L
- (9, 2):
- (10, 0): Y-GTP U/L
- (10, 1): 19 1g/L
- (10, 2):
diのprebuild-layoutだと項目と値が概ね合っていることが確認できるが、
一部「19 1g/L」や画像が切れている最後のHDLコレステロールの項目が欠けた。
mistral ocrはちゃんと値が読めてそう。
Json Schemaを定義してみる
{
"name": {
"value": "佐藤 太一",
"confidence": 1.0
},
"date_of_birth": {
"value": "1986-09-08",
"confidence": 1.0
},
"height_cm": {
"value": 172.5,
"confidence": 1.0
},
"weight_kg": {
"value": 66.8,
"confidence": 1.0
},
"bmi": {
"value": 22.4,
"confidence": 1.0
},
"vision": {
"value": "1.2",
"confidence": 1.0
},
"hearing": {
"value": "無常なし",
"confidence": 1.0
},
"blood_pressure": {
"value": "128/80 mmHg",
"confidence": 1.0
},
"hdl_cholesterol": {
"value": 68,
"confidence": 1.0
}
}
まとめ
生成ドキュメントのため画像項目やレイアウトはおかしかったが、mistralはかなり忠実にOCRをしてくれた印象。項目との紐付けもわかりやすかった。
また、structured_outputのようにJSON Schemaを定義することで、特定項目の取得精度が上がりそうな気はしました。
HDLとLDLの違いなどは読めていそうですが、もっと類似の項目をしっかり分類できるかや解像度が低い場合、ノイジーなケースでの検証は必要だと思いますが、帳票OCRは類似項目分類と確信度を定義、算出できることが大事だと思うので、希望だなーと思いました。
実行したスクリプト - mistral_ocr.py
from __future__ import annotations
import argparse
import base64
import json
import mimetypes
import pathlib
import sys
from typing import Any, Dict
import requests
DEFAULT_OCR_URL = (
"https://xxxx.services.ai.azure.com"
"/providers/mistral/azure/ocr"
)
DEFAULT_API_KEY = "your api key"
DEFAULT_MODEL = "mistral-document-ai-2505"
def encode_image(path: pathlib.Path) -> str:
mime, _ = mimetypes.guess_type(path.name)
if not mime:
raise ValueError("Unsupported image type")
data = base64.b64encode(path.read_bytes()).decode("ascii")
return f"data:{mime};base64,{data}"
def build_payload(path: pathlib.Path, model: str, include_image: bool) -> Dict[str, Any]:
return {
"model": model,
"document": {"type": "image_url", "image_url": encode_image(path)},
"include_image_base64": include_image,
}
def call_ocr(url: str, api_key: str, payload: Dict[str, Any]) -> Dict[str, Any]:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
}
resp = requests.post(url, headers=headers, json=payload, timeout=60)
resp.raise_for_status()
return resp.json()
def build_markdown(result: Dict[str, Any], path: pathlib.Path, url: str, model: str) -> str:
sections = []
pages = result.get("pages")
if isinstance(pages, list):
for i, page in enumerate(pages, start=1):
text = page.get("markdown")
if text:
sections.append(
f"## Page {i} Markdown\n\n```markdown\n{text}\n```\n"
)
page["markdown"] = "<see Markdown section below>"
body = [
"# OCR Result",
"",
f"- Endpoint: `{url}`",
f"- Model: `{model}`",
f"- Image: `{path}`",
"",
"## Response",
"",
"```json",
json.dumps(result, indent=2, ensure_ascii=False),
"```",
]
if sections:
body.extend([""] + sections)
return "\n".join(body)
def parse_args(argv: list[str]) -> argparse.Namespace:
parser = argparse.ArgumentParser()
parser.add_argument("image", type=pathlib.Path)
parser.add_argument("--url", default=DEFAULT_OCR_URL)
parser.add_argument("--api-key", default=DEFAULT_API_KEY)
parser.add_argument("--model", default=DEFAULT_MODEL)
parser.add_argument(
"--no-include-image-base64",
action="store_true",
)
parser.add_argument("--output-md", type=pathlib.Path)
return parser.parse_args(argv)
def main(argv: list[str]) -> int:
args = parse_args(argv)
if not args.image.exists():
print(f"Image not found: {args.image}", file=sys.stderr)
return 1
payload = build_payload(
args.image,
args.model,
include_image=not args.no_include_image_base64,
)
try:
result = call_ocr(args.url, args.api_key, payload)
except requests.HTTPError as exc:
print(f"Request failed: {exc.response.text}", file=sys.stderr)
return 1
print(json.dumps(result, indent=2, ensure_ascii=False))
if args.output_md:
args.output_md.write_text(
build_markdown(result.copy(), args.image, args.url, args.model),
encoding="utf-8",
)
return 0
if __name__ == "__main__":
raise SystemExit(main(sys.argv[1:]))
実行コマンド
mistral_ocr.py testX.png --output-md testX_ocr_result.md
mistral JSON Schemaと確信度あり
FIELD_DEFINITIONS = [
{"id": "name", "title": "氏名", "type": "string"},
{"id": "date_of_birth", "title": "生年月日", "type": "string"},
{"id": "height_cm", "title": "身長 (cm)", "type": "number"},
{"id": "weight_kg", "title": "体重 (kg)", "type": "number"},
{"id": "bmi", "title": "BMI", "type": "number"},
{"id": "vision", "title": "視力", "type": "string"},
{"id": "hearing", "title": "聴力", "type": "string"},
{"id": "blood_pressure", "title": "血圧", "type": "string"},
{"id": "hdl_cholesterol", "title": "HDLコレステロール (mg/dL)", "type": "number"},
]
SCHEMA_DEFINITION = {
"type": "object",
"additionalProperties": False,
"properties": {
field["id"]: {
"title": field["title"],
"type": "object",
"properties": {
"value": {
"type": ["number", "string"] if field["type"] == "number" else "string"
},
"confidence": {"type": "number"},
},
"required": ["value", "confidence"],
}
for field in FIELD_DEFINITIONS
},
}
CONFIDENCE_SUSPECT_THRESHOLD = 0.6
def encode_image(path: pathlib.Path) -> str:
mime, _ = mimetypes.guess_type(path.name)
if not mime:
raise ValueError("Unsupported image type")
data = base64.b64encode(path.read_bytes()).decode("ascii")
return f"data:{mime};base64,{data}"
def build_payload(path: pathlib.Path, model: str, include_image: bool) -> Dict[str, Any]:
return {
"model": model,
"document": {"type": "image_url", "image_url": encode_image(path)},
"include_image_base64": include_image,
"document_annotation_format": {
"type": "json_schema",
"json_schema": {
"name": "health_check",
"strict": False,
"schema": SCHEMA_DEFINITION,
},
},
}
def call_ocr(url: str, api_key: str, payload: Dict[str, Any]) -> Dict[str, Any]:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
}
resp = requests.post(url, headers=headers, json=payload, timeout=60)
resp.raise_for_status()
return resp.json()
def coerce_value(obj: Any) -> Any:
if isinstance(obj, dict):
for key in ("value", "valueString", "value_number", "valueNumber", "text", "content"):
if key in obj:
return coerce_value(obj[key])
return obj
def coerce_confidence(obj: Any) -> float | None:
if isinstance(obj, dict):
if "confidence" in obj:
return coerce_confidence(obj["confidence"])
if "score" in obj:
return coerce_confidence(obj["score"])
if "value" in obj:
return coerce_confidence(obj["value"])
if isinstance(obj, (int, float)):
return float(obj)
if isinstance(obj, str):
try:
return float(obj)
except ValueError:
return None
return None
def find_structured_candidate(data: Any) -> Dict[str, Any] | None:
stack: List[Any] = [data]
field_ids = {field["id"] for field in FIELD_DEFINITIONS}
while stack:
node = stack.pop()
if isinstance(node, dict):
matches = [fid for fid in field_ids if fid in node and isinstance(node[fid], dict)]
if matches:
valid = True
for fid in matches:
entry = node[fid]
if not isinstance(entry, dict):
valid = False
break
if coerce_value(entry) is None and coerce_confidence(entry) is None:
valid = False
break
if valid:
return node
stack.extend(node.values())
elif isinstance(node, list):
stack.extend(node)
return None
def extract_structured_fields(result: Dict[str, Any]) -> List[Dict[str, Any]]:
candidate = find_structured_candidate(result)
extracted: List[Dict[str, Any]] = []
for field in FIELD_DEFINITIONS:
raw = candidate.get(field["id"]) if isinstance(candidate, dict) else None
value = coerce_value(raw)
confidence = coerce_confidence(raw)
if isinstance(value, (list, dict)):
value_display = json.dumps(value, ensure_ascii=False)
elif value is None:
value_display = ""
else:
value_display = str(value)
status = "OK"
if not value_display:
status = "未取得"
elif confidence is None:
status = "信頼度不明"
elif confidence < CONFIDENCE_SUSPECT_THRESHOLD:
status = "要確認"
extracted.append(
{
"id": field["id"],
"title": field["title"],
"value": value_display,
"confidence": confidence,
"status": status,
}
)
return extracted
def build_structured_table(extracted: List[Dict[str, Any]]) -> str:
if not extracted:
return ""
lines = ["|項目|値|確信度|ステータス|", "|---|---|---|---|"]
for item in extracted:
confidence = item["confidence"]
confidence_str = "-" if confidence is None else f"{confidence:.2f}"
value = item["value"] or ""
lines.append(
f"|{item['title']}|{value}|{confidence_str}|{item['status']}|"
)
return "\n".join(lines)
def build_markdown(
result: Dict[str, Any],
path: pathlib.Path,
url: str,
model: str,
extracted_fields: List[Dict[str, Any]],
) -> str:
structured_table = build_structured_table(extracted_fields)
sections = []
pages = result.get("pages")
if isinstance(pages, list):
for i, page in enumerate(pages, start=1):
text = page.get("markdown")
if text:
sections.append(
f"## Page {i} Markdown\n\n```markdown\n{text}\n```\n"
)
page["markdown"] = "<see Markdown section below>"
body: List[str] = [
"# OCR Result",
"",
f"- Endpoint: `{url}`",
f"- Model: `{model}`",
f"- Image: `{path}`",
"",
]
if structured_table:
body.extend([
"## Structured Extraction",
"",
structured_table,
"",
])
body.extend(
[
"## Response",
"",
"```json",
json.dumps(result, indent=2, ensure_ascii=False),
"```",
]
)
if sections:
body.extend([""] + sections)
return "\n".join(body)
def parse_args(argv: list[str]) -> argparse.Namespace:
parser = argparse.ArgumentParser()
parser.add_argument("image", type=pathlib.Path)
parser.add_argument("--url", default=DEFAULT_OCR_URL)
parser.add_argument("--api-key", default=DEFAULT_API_KEY)
parser.add_argument("--model", default=DEFAULT_MODEL)
parser.add_argument(
"--no-include-image-base64",
action="store_true",
)
parser.add_argument("--output-md", type=pathlib.Path)
return parser.parse_args(argv)
def main(argv: list[str]) -> int:
args = parse_args(argv)
if not args.image.exists():
print(f"Image not found: {args.image}", file=sys.stderr)
return 1
payload = build_payload(
args.image,
args.model,
include_image=not args.no_include_image_base64,
)
try:
result = call_ocr(args.url, args.api_key, payload)
except requests.HTTPError as exc:
print(f"Request failed: {exc.response.text}", file=sys.stderr)
return 1
extracted_fields = extract_structured_fields(result)
print(json.dumps(result, indent=2, ensure_ascii=False))
structured_summary = {
item["id"]: {
"value": item["value"],
"confidence": item["confidence"],
"status": item["status"],
}
for item in extracted_fields
}
print(json.dumps({"structured_fields": structured_summary}, ensure_ascii=False, indent=2))
if args.output_md:
args.output_md.write_text(
build_markdown(
json.loads(json.dumps(result)),
args.image,
args.url,
args.model,
extracted_fields,
),
encoding="utf-8",
)
return 0
if __name__ == "__main__":
raise SystemExit(main(sys.argv[1:]))

Discussion