やること
①.SQLDBにデータ(商品レビューデータ)をinsertする
②.DataFactoryでデータを取り込む
③.組み込みAIを使い、データを前処理する
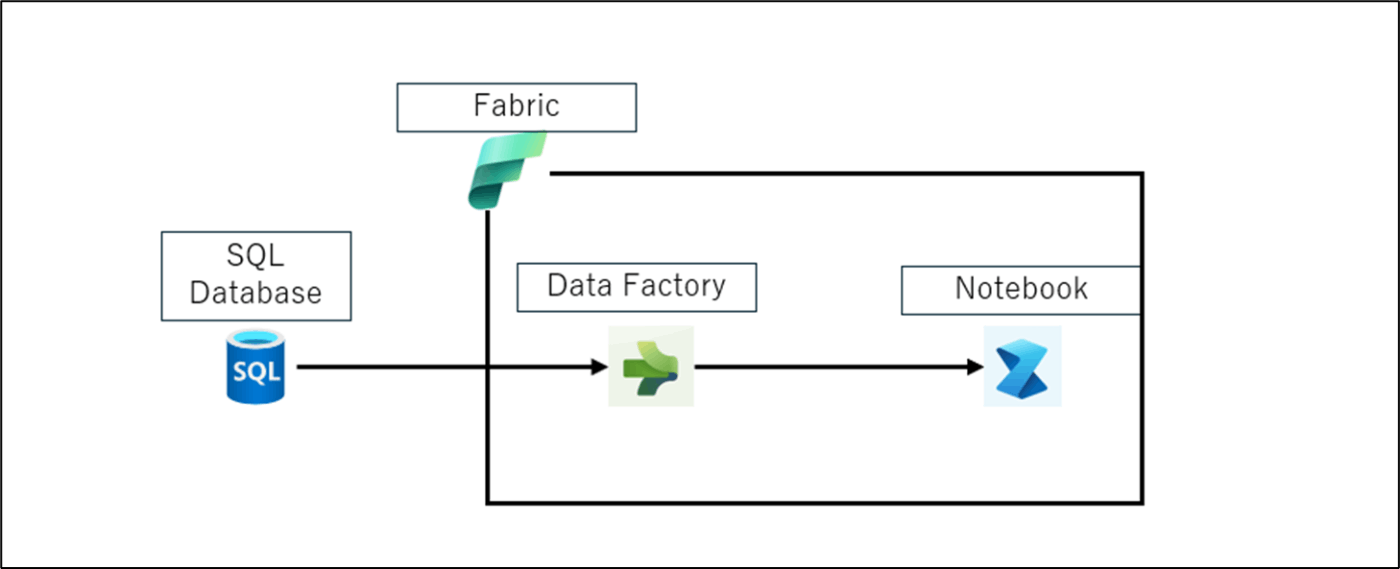
検証手順
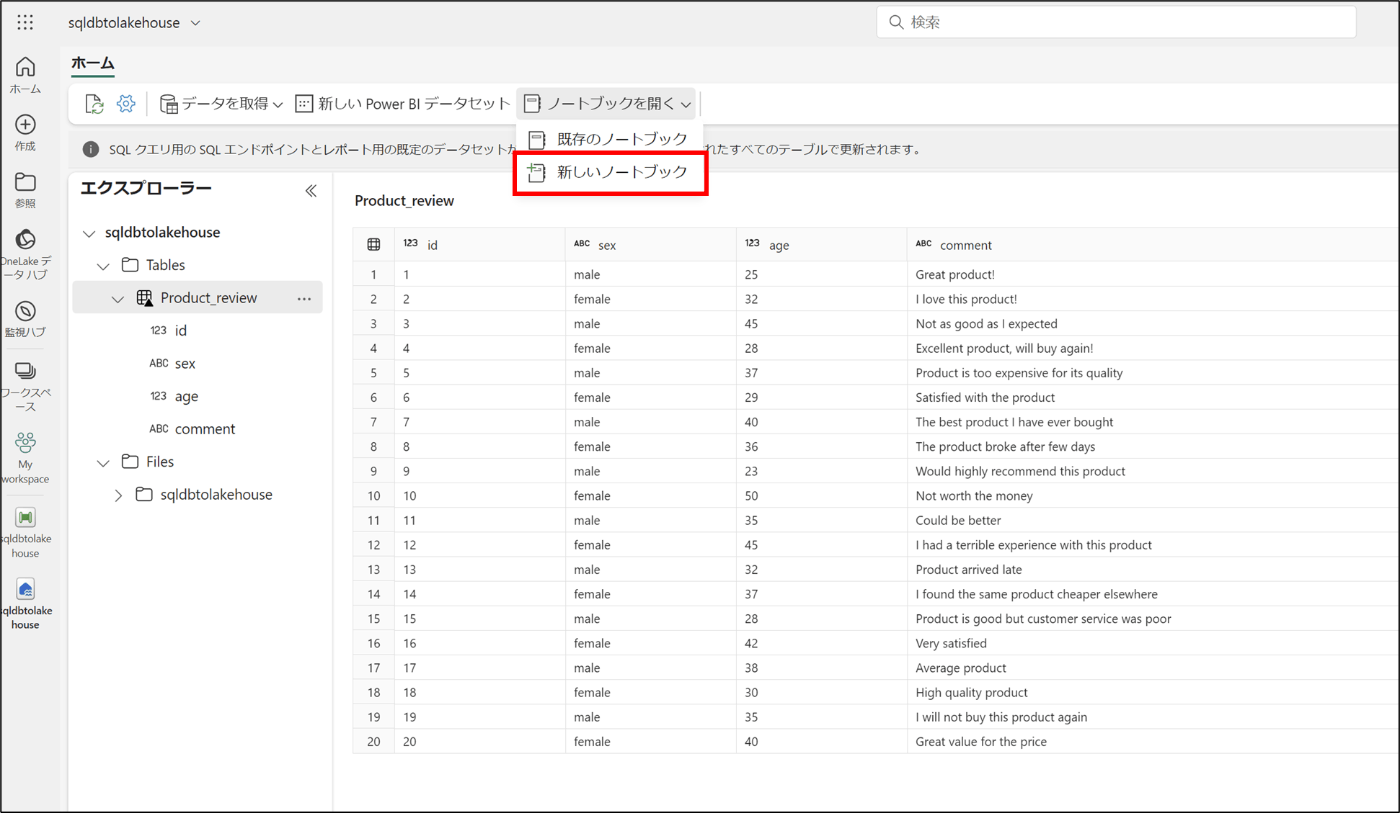
- 「新しいノートブック」をクリック
- ノートブックが開いていることを確認
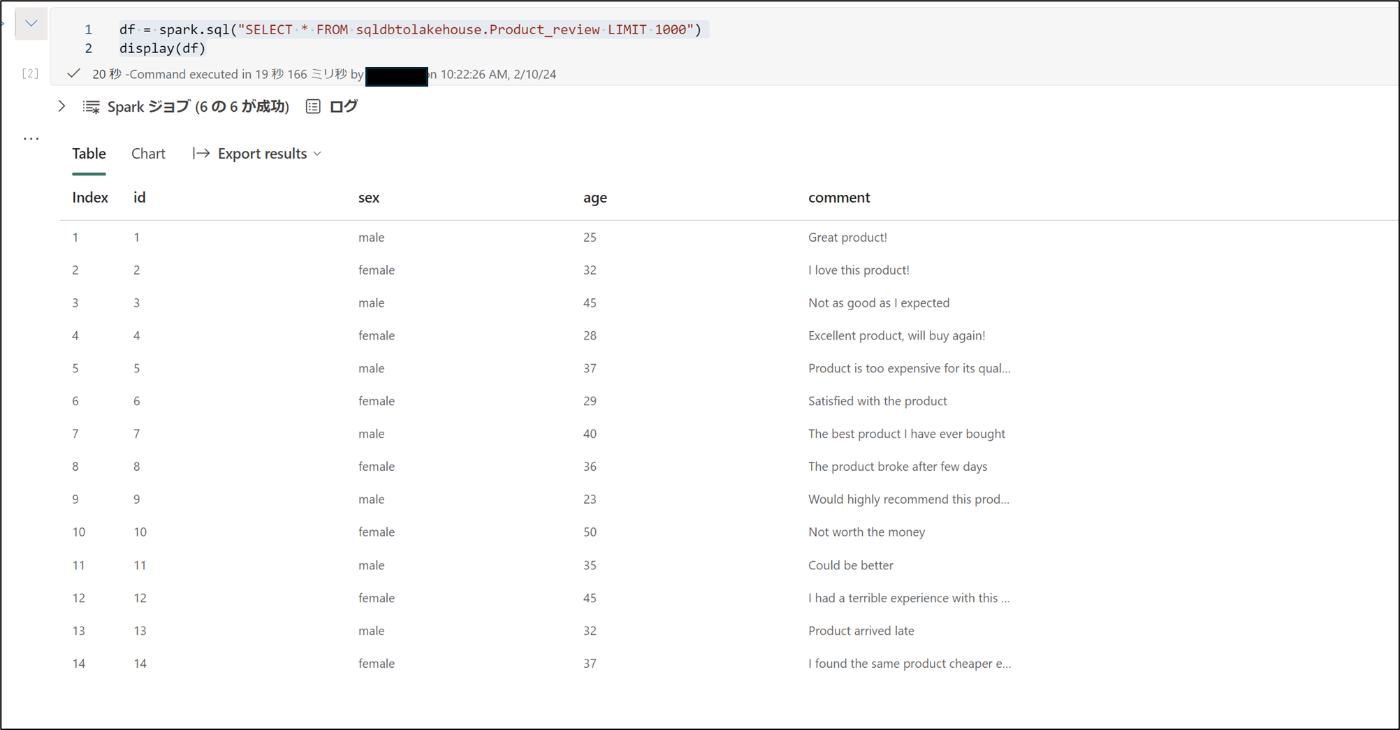
- 下記のコードを実行し、テーブルの中身を確認
df = spark.sql("SELECT * FROM sqldbtolakehouse.Product_review LIMIT 1000")
display(df)
4. 下記のコードを実行し、commentの感情分析を行う
# Get workload endpoints and access token
from synapse.ml.mlflow import get_mlflow_env_config
import json
import requests
from pprint import pprint
import uuid
mlflow_env_configs = get_mlflow_env_config()
pandas_df = df.toPandas()
access_token = access_token = mlflow_env_configs.driver_aad_token
prebuilt_AI_base_host = mlflow_env_configs.workload_endpoint + "cognitive/textanalytics/"
print("Workload endpoint for AI service: \n" + prebuilt_AI_base_host)
service_url = prebuilt_AI_base_host + "language/:analyze-text?api-version=2022-05-01"
# Make a RESful request to AI service
post_headers = {
"Content-Type" : "application/json",
"Authorization" : "Bearer {}".format(access_token)
}
def printresponse(response):
print(f"HTTP {response.status_code}")
if response.status_code == 200:
try:
result = response.json()
print(json.dumps(result, indent=2, ensure_ascii=False))
except:
print(f"pasre error {response.content}")
else:
print(response.headers)
print(f"error message: {response.content}")
# 'comment'列からテキストを取得して感情分析APIに送信
for idx, row in pandas_df.iterrows():
post_body = {
"kind": "SentimentAnalysis",
"parameters": {
"modelVersion": "latest",
"opinionMining": "True"
},
"analysisInput":{
"documents":[
{
"id": str(idx),
"language":"ja",
"text": row['comment']
}
]
}
}
post_headers["x-ms-workload-resource-moniker"] = str(uuid.uuid1())
response = requests.post(service_url, json=post_body, headers=post_headers)
response_json = response.json()
# Get 'confidenceScores' from the response
confidence_scores = response_json.get('results', {}).get('documents', [{}])[0].get('confidenceScores', {})
# Output all information of the request process
print(confidence_scores)
- 下記が出力される
{'positive': 1.0, 'neutral': 0.0, 'negative': 0.0}
{'positive': 0.98, 'neutral': 0.02, 'negative': 0.0}
{'positive': 0.0, 'neutral': 0.0, 'negative': 1.0}
{'positive': 1.0, 'neutral': 0.0, 'negative': 0.0}
{'positive': 0.01, 'neutral': 0.0, 'negative': 0.99}
{'positive': 1.0, 'neutral': 0.0, 'negative': 0.0}
{'positive': 1.0, 'neutral': 0.0, 'negative': 0.0}
{'positive': 0.0, 'neutral': 0.0, 'negative': 1.0}
{'positive': 0.96, 'neutral': 0.04, 'negative': 0.0}
{'positive': 0.0, 'neutral': 0.0, 'negative': 1.0}
{'positive': 0.91, 'neutral': 0.02, 'negative': 0.07}
{'positive': 0.0, 'neutral': 0.0, 'negative': 0.99}
{'positive': 0.11, 'neutral': 0.0, 'negative': 0.89}
{'positive': 0.05, 'neutral': 0.83, 'negative': 0.12}
{'positive': 0.0, 'neutral': 0.0, 'negative': 1.0}
{'positive': 1.0, 'neutral': 0.0, 'negative': 0.0}
{'positive': 0.1, 'neutral': 0.51, 'negative': 0.4}
{'positive': 0.98, 'neutral': 0.02, 'negative': 0.0}
{'positive': 0.0, 'neutral': 0.0, 'negative': 1.0}
{'positive': 1.0, 'neutral': 0.0, 'negative': 0.0}
- 下記のコードを実行し、新たな列(positive,neutral,negative)を追加してテーブルを作成
from pyspark.sql.functions import udf
from pyspark.sql.types import StructType, StructField, DoubleType, StringType
# UDFを定義
def analyze_sentiment(comment):
post_body = {
"kind": "SentimentAnalysis",
"parameters": {
"modelVersion": "latest",
"opinionMining": "True"
},
"analysisInput":{
"documents":[
{
"id":"1",
"language":"ja",
"text": comment
}
]
}
}
post_headers["x-ms-workload-resource-moniker"] = str(uuid.uuid1())
response = requests.post(service_url, json=post_body, headers=post_headers)
# Get 'confidenceScores' from the response
response_json = response.json()
confidence_scores = response_json.get('results', {}).get('documents', [{}])[0].get('confidenceScores', {})
return (confidence_scores.get('positive'), confidence_scores.get('neutral'), confidence_scores.get('negative'))
# Define the schema for the return value
schema = StructType([
StructField("positive", DoubleType(), True),
StructField("neutral", DoubleType(), True),
StructField("negative", DoubleType(), True)
])
# Register the UDF
sentiment_udf = udf(analyze_sentiment, schema)
# Add new columns
df = df.withColumn("sentiment", sentiment_udf(df['comment']))
# Split the struct column into separate columns
df = df.select("*", "sentiment.*").drop("sentiment")
df.write.saveAsTable("sqldbtolakehouse.Product_review_with_sentiment")
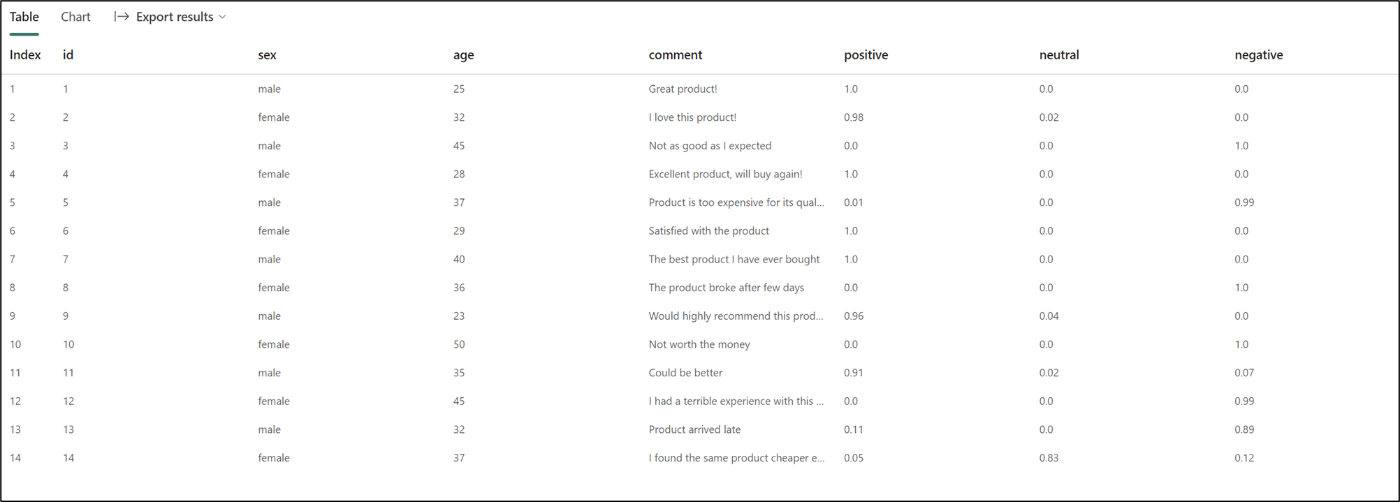
- 下記のコードを実行し、テーブルが作成されていることを確認
df = spark.sql("SELECT * FROM sqldbtolakehouse.product_review_with_sentiment LIMIT 1000")
display(df)

Discussion