執筆日
2025/07/19
概要
今更Dify第2弾です。テキストファイルからナレッジを作成します。RAGの基盤になるやつですね。
Notionやウェブサイトから同期してナレッジ作成もできますがNotionは自分のアカウントとの接続が、ウェブサイトも Jina Reader, Firecrawl, WaterCrwl のどれかでアカウント作成してAPIが利用できるようにする必要があります。WaterCrwl は Dify チームが作成しているらしく、軽量で最適化されていそうなのでいつか試したいです。また外部リソースによる接続も可能でこちらで解説されています。AWS Bedrockのみ詳細な設計方法が解説されていますが、頑張れば色んな外部ナレッジへのAPIによる統合が可能なようです。そのうちAzure Ai Searchと統合する方法とかも書き……たくはないです。
前提
- 執筆時 Dify Version latest 1.7.1
- 第1弾 [Dify] 1. DockerでDifyを立ち上げる でDifyを立ち上げてアクセスできるようになっていること。
作業
モデルプロバイダー設定
ベクトル検索を用いるナレッジの登録・検索には当然ですが埋め込みモデルが必要になります。
ローカルで埋め込みモデルを動かせるのであればそれでもいいですが、基本的に有料のAPIを使うことになると思います。右上のアカウントアイコンの設定から[モデルプロバイダー設定]を開きます。
今回はAzure OpenAIでtext-embedding-3-smallを使います。
まず、モデルプロバイダーをインストールする、からAzure OpenAIを選択してインストールします。反映されるまでに何故か時間がかかることがありますが追加されるとモデルプロバイダー一覧に表示されるので[モデルを追加]を選択して、Azure OpenAIでデプロイした埋め込みモデルの設定を入れて保存を押します。どうせ使うのでついでにLLMの設定も済ませておきましょう。

上手くいけばこんな感じの表示になります。(反映が遅くなることがままあるので待つか何回か試してみてください)

ファイルアップロード
ヘッダーから[ナレッジ]を選択して[テキストファイルからインポート]を選択してファイルを入れて次へ

チャンク設定
チャンク分割設定が出来ます。CSVの場合はたぶん設定は関係なくなり、1レコード1チャンクでkey1: value1;key2: value2;...という形で登録されます。(JSONも同じ感じでやってくれたらいいのになぜか.jsonファイルは使えません)
親子分割モードを使うと分割された子チャンクが検索に、段落又はテキスト全文の親チャンクを検索結果として使用できます。ベクトル検索の弱点(テキスト序盤にほとんど重みがいってしまう)を補う面白い機能ですね。

インデックス方法
RAG構築者にとってハイブリッド検索の詳細は耳にタコだと思うので、ベクトル検索設定の説明だけさせていただきます。
上記モデルプロバイダー設定が上手くいっていれば、設定したモデルを選択できるようになっています。ハイブリッド検索を選択することでベクトルと全文検索が有効になります。リランキングモデルは今回使っていませんが使用したい場合は同じくモデルプロバイダーで設定しましょう。Cohereのrerank-multilingual-v2.0がいい感じらしいです。

確認・テスト
保存して終了を押すとデータベースへの登録が始まります。埋め込みが走るのでチャンク分量次第ではそこそこ時間がかかります。
作成したナレッジを開くと分割されたチャンクを確認することが出来ます。今回はヘッドウォータースのZenn記事のタイトル・著者・記事リンクのリストをCSVにして登録してみました。
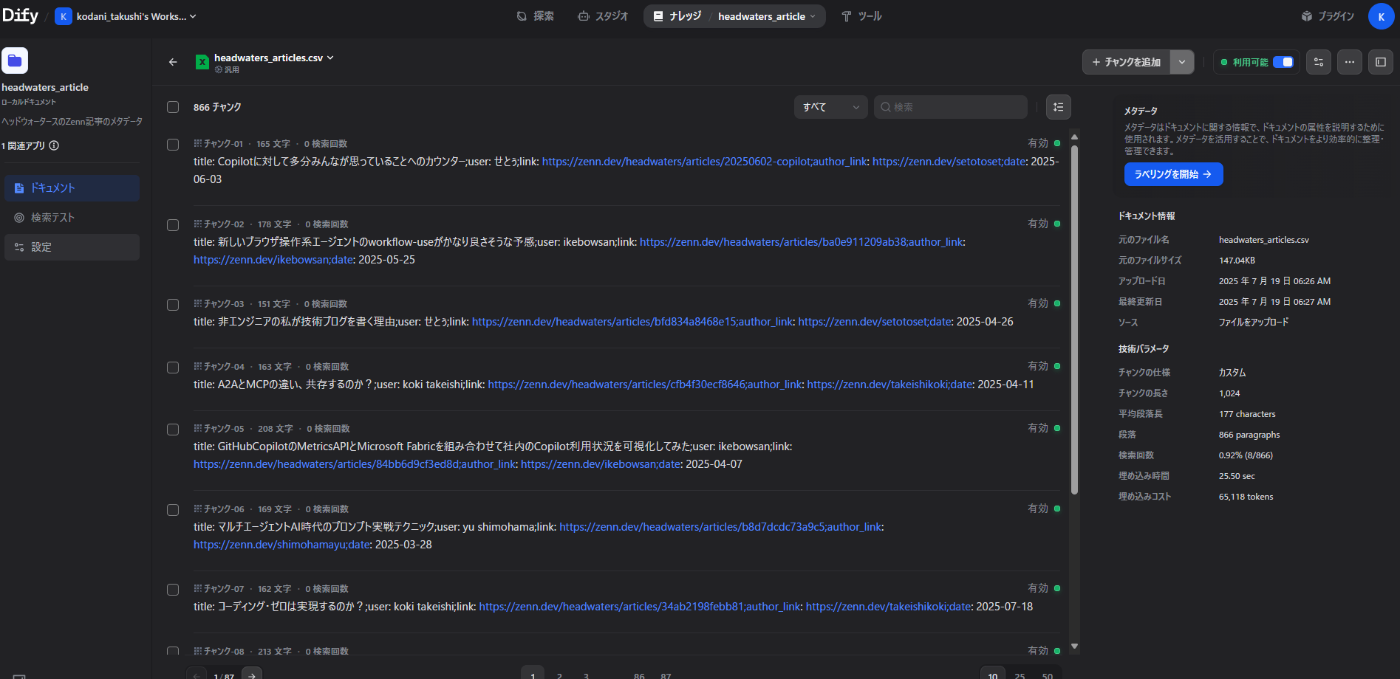
検索テストから検索のテスト実行が出来ます。
Fabricで検索してみるとこんな感じで関連するブログの情報が取得できました。いい感じに出来ていそうです。

Tips
設定変更
後から各設定を変更することが出来ますが、埋め込みモデルを変更するとベクトル検索が成り立たなくなってしまうためその場合はナレッジの再作成をしましょう。
ファイルからのテキストカスタム抽出
自作した前処理方法を使って作成したテキストを後からDify APIで登録することもできます(一旦テキストファイルにしてからWeb UIで登録してもいいですが)
その場合以下のようにリクエストを送ります。埋め込みは自動で実行されますが、ソースファイルの登録は別途必要になります。
curl -X POST https://api.dify.ai/v1/datasets/{dataset_id}/document/create_by_text \
-H "Authorization: Bearer {API_KEY}" \
-H "Content-Type: application/json" \
-d '{
"text": "これはカスタム抽出されたテキストです。",
"metadata": {"source_file": "report.docx"},
"indexing_technique": "high_quality",
"process_rule": {
"mode": "custom",
"rules": {
"segmentation": {
"separator": "\n\n",
"max_tokens": 500
}
}
}
}'
その他APIからのナレッジ編集に関するドキュメントは以下
感想
ナレッジ作成もポチポチ簡単。
次回はこのナレッジを使ってチャットフロー作成をします。
参考

Discussion