


先に結論
llama.cppだと1bit量子化モデルなら動く、しかし自然言語な回答は生成はできない
mlx-swiftだと4bit量子化モデルまで動く、自然言語な回答は生成できるが質問に対する回答にはなっていない
上記の結果から、「現時点ではPhi-3.5-miniの8bitを使うのが良い」です。
背景
Microsoftの最新SLMモデルであるPhi-4が1月の中旬に商用利用可能となりました。
「AGX Orinで動いた」や「Macbook Proで動いた」の記事を見かけたので、M4 iPad Proでもいけるんじゃねー?と社内で話題になり検証してみました。
社内メンバーの検証記事(AGX Orign メモリ64GB)
前提
検証にあたって。
使用端末...iPad Pro M4チップ(CPU10コア・メモリ16GB・GPU10コア) 11インチ 1TB
開発言語...Swift6
ライブラリ...llama.cpp / MLX-swift
SLMモデル...Phi-4
ファイル形式...GGUF / MLX
iPad Proの性能
現時点で最高スペックのタブレットになります。
僕が業務で使用しているMacbook(M1 Max メモリ64GB)と比較してみます。
GPUはMacbookの方が良さそうです。
| GPU | iPad Pro(M4) | Macbook Pro(M1 Max) |
|---|---|---|
| OpenCL | - | 59,779 |
| Metal | 53,594 | 99,774 |

CPUはiPad Proの方が優勢ですね。
でも注意として、Macbook(PC)に比べて使用できるCPUやメモリに制限があるので、実際にはMacbookの方がパフォーマンスはいいかも。
| CPU | iPad Pro(M4) | Macbook Pro(M1 Max) |
|---|---|---|
| シングルコア | 3707 | 2456 |
| マルチコア | 14,418 | 12,959 |
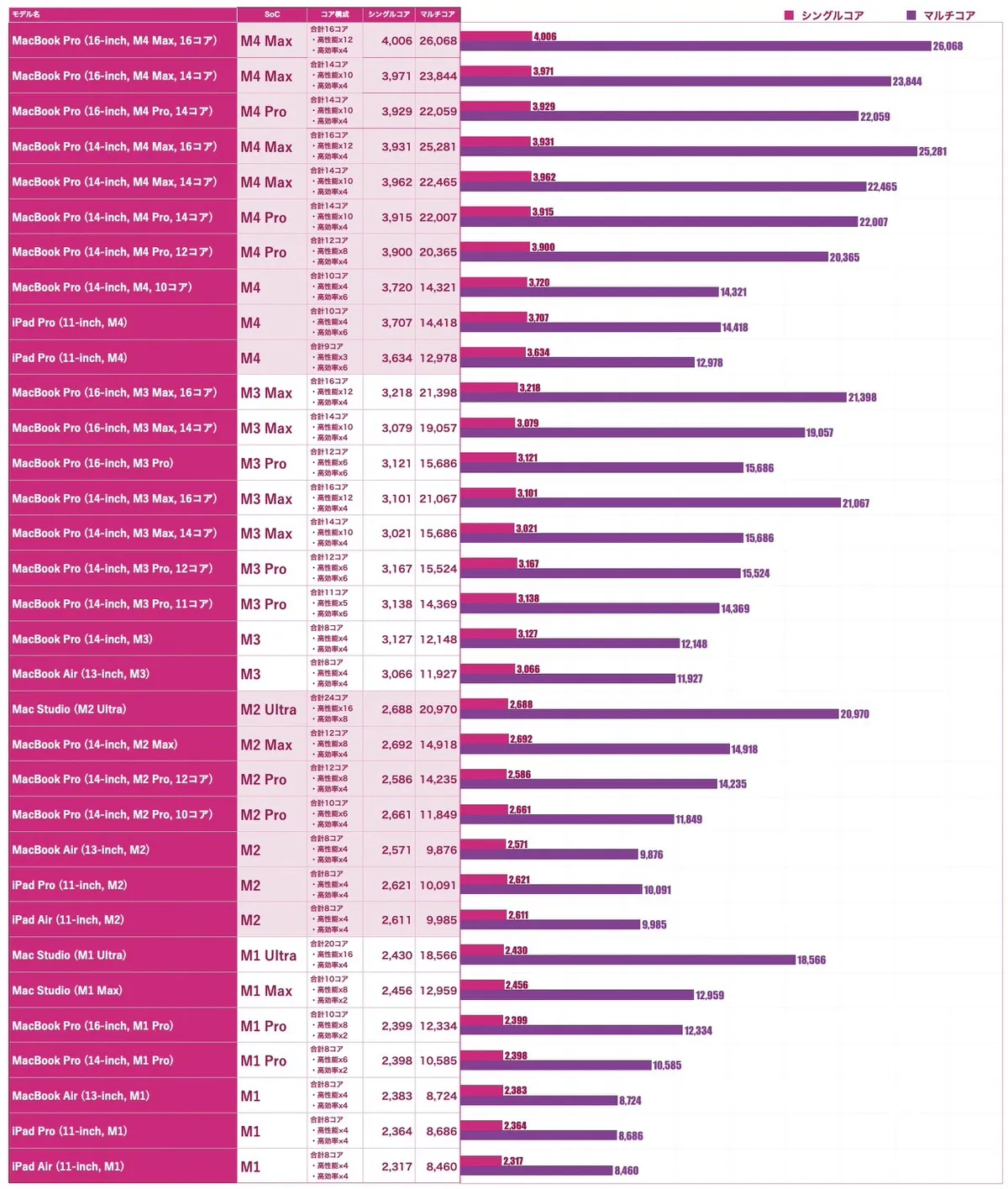
3年前に購入した最高スペックのMacbook Proと引けを取らないスペックをiPad Proを持っているようです。
なんてったって値段は26万円ですから..
検証1. llama.cppで試す
iOS(Swift)アプリでローカルLLMを動かしたい!となった時に最有力候補になるのが、llama.cppです。
ライブラリ自体はC++で実装されており、Swiftでも使えるように提供がされています。
GitHub上もかなりアクティブで最新のAIモデルは結構早くサポートされている印象です。
※形式はGGUF形式である必要があります。
昨年5月に僕も試してました。
1. 4bit量子化モデル(Microsoft公式)
まずはこちら。サイズは9.05GB。
まー載らんだろと思いつつもやってみます。
ダメでした。メモリが足らないようです。
llama_load_model_from_file: using device Metal (Apple M4 GPU) - 10922 MiB free
llama_model_loader: loaded meta data with 33 key-value pairs and 243 tensors from /var/mobile/Containers/Data/Application/8D6F4F18-5E0F-4B56-AED3-1F533A97CC68/Documents/Phi-4-q4.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = phi3
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = Phi 4
llama_model_loader: - kv 3: general.version str = 4
...
llm_load_print_meta: EOG token = 100265 '<|im_end|>'
llm_load_print_meta: max token length = 256
llama_model_load: error loading model: mmap failed: Cannot allocate memory
llama_load_model_from_file: failed to load model
Could not load model at /var/mobile/Containers/Data/Application/8D6F4F18-5E0F-4B56-AED3-1F533A97CC68/Documents/Phi-4-q4.gguf
Error: The operation couldn’t be completed. (JalSimAiApp.LlamaError error 0.)
モデルのuse_mmapをfalseにしたり、n_gpu_layersを0にしてCPUに頼るといったことも試しましたがダメでした。
2. 2bit量子化モデル
2bitに落としました。サイズは5.63GB。
精度はかなり落ちますが、果たして。
こちらもダメでした。
M1 Macbook Proのシミュレーター上では動いたので、「いけるんじゃね」と思ったのですがダメでしたね...
おそらく一つのアプリに使えるメモリの最大量?が決まってるのでしょう。
3. 1bit量子化モデル
1bitまで落としました。サイズは4.94GB。
ここまでくると言語モデルと呼べるのかはさておいて、1bitの量子化モデルで試してみます。
動きました!
しかしただテキストを生成しているだけで、自然言語とは到底言えないです。

CPUも常時800%以上でした(笑)

「iPadにPhi4が載った」という事実だけは一応作ることに成功。
検証2. MLX-Swift
Appleが研究しているMLX。
上記のこともあってか親和性という意味ではllama.cppより優れていると期待しています。
しかしllama.cppに比べるとアクティブではないのと、ドキュメントが圧倒的に少ないです。
こっちを使うのがパフォーマンス的に最適解ではありそうですが、Swiftが得意ってわけではないので、バグ出た時に困るな..という印象。
Hugging Faceの「MLX-Community」にアップされてるモデルは基本的に全部動くっぽいです。
1. 2bit量子化モデル
llama.cppだと載らなかった2bitから行きます。
載りましたー
全く別の回答を返してはいるものの、自然言語な回答になりました。

2. 4bit量子化モデル
もうワンステップ上げてみる。
こちらも載りましたー
さっきと同様に的外れな回答にはなってしまっていますが、「4bit量子化のPhi-4でも載せることができる」という新たな発見がありました。

3. 8bit量子化
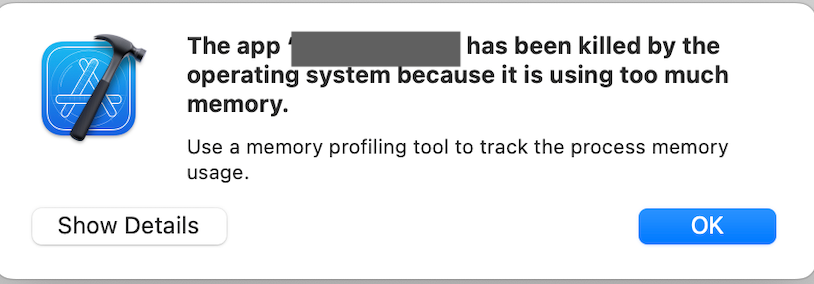
こちらは流石に載りませんでした。
アプリが強制Killされて、iPadが勝手に再起動までしちゃいました。
無理させすぎました、ここが限界のようです。
疑問
なぜMLX-Swiftだと重たいモデルも動いたの?
GitHubを見ていたら以下の記載がありました。
- メモリ制限の増加...どうやら設定でメモリ制限を取っ払うことができるらしい
- バッファキャッシュサイズの制限...キャッシュサイズを抑えることで不要なメモリ消費を減らしているとのこと

なぜMLX-Swiftだと的外れな回答が生成されるの?
正式にPhi4をサポートしてないからです。
現在サポートされているのはPhi-3のMoEまでです。
...しかしモデルは自分で作ることが可能の模様。
なので1からモデル定義から始めちゃえば使えるようになるっぽいですね。
今回はモデルを自分で定義してなかったので、共通モデルが使われたから自然言語の生成はできたものの的外れない回答になったのかと思われます。
最後に
Phi-4だとモデルを圧縮しすぎて今のところ厳しそうでしたが、「一応」載せることはできました。
ただ精度を考えると現時点ではPhi-3.5-miniの8bit量子化が良いかと思います。
文章のフォーマットに違和感はあるものの、質問に対する回答はしっかりしてくれます。


Discussion