

やってみること
OpenAI Python SDKを使用して、Fabric の Azure OpenAI を使用してLanguage Detectorを行う
手順
- Microsoft Fabric(https://app.fabric.microsoft.com/home)にアクセス

- 「Synapse Data Engineering」をクリック

- 「ワークスペース」をクリック

- 作業を行うワークスペースをクリック

- 「+新規」をクリック

- 「ノートブック」をクリック

- ノートブックが開くことを確認

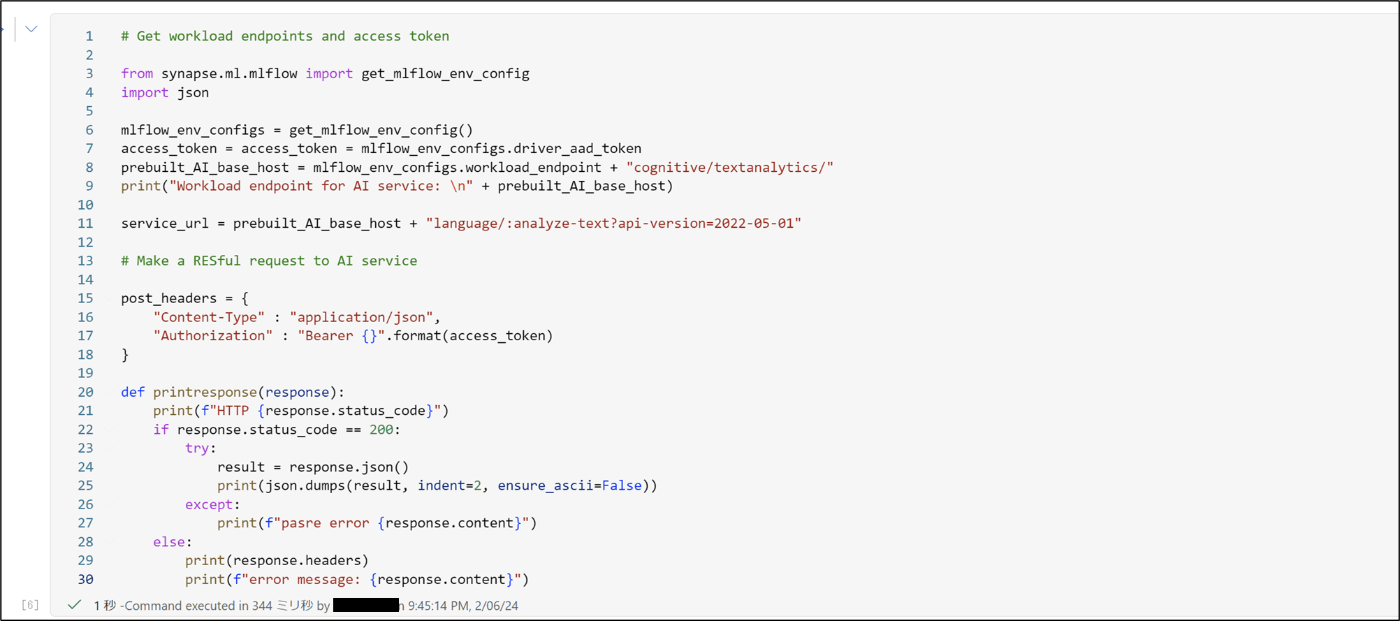
- 下記のコードを実行し、AIサービスに接続する
# Get workload endpoints and access token
from synapse.ml.mlflow import get_mlflow_env_config
import json
mlflow_env_configs = get_mlflow_env_config()
access_token = access_token = mlflow_env_configs.driver_aad_token
prebuilt_AI_base_host = mlflow_env_configs.workload_endpoint + "cognitive/textanalytics/"
print("Workload endpoint for AI service: \n" + prebuilt_AI_base_host)
service_url = prebuilt_AI_base_host + "language/:analyze-text?api-version=2022-05-01"
# Make a RESful request to AI service
post_headers = {
"Content-Type" : "application/json",
"Authorization" : "Bearer {}".format(access_token)
}
def printresponse(response):
print(f"HTTP {response.status_code}")
if response.status_code == 200:
try:
result = response.json()
print(json.dumps(result, indent=2, ensure_ascii=False))
except:
print(f"pasre error {response.content}")
else:
print(response.headers)
print(f"error message: {response.content}")
- 下記のコードを実行する
post_body = {
"kind": "LanguageDetection",
"parameters": {
"modelVersion": "latest"
},
"analysisInput":{
"documents":[
{
"id":"1",
"text": "これは日本語で書かれた文章です。"
}
]
}
}
post_headers["x-ms-workload-resource-moniker"] = str(uuid.uuid1())
response = requests.post(service_url, json=post_body, headers=post_headers)
# Output all information of the request process
printresponse(response)
- 出力結果を確認
HTTP 200
{
"kind": "LanguageDetectionResults",
"results": {
"documents": [
{
"id": "1",
"detectedLanguage": {
"name": "Japanese",
"iso6391Name": "ja",
"confidenceScore": 1.0
},
"warnings": []
}
],
"errors": [],
"modelVersion": "2023-12-01"
}
※出力結果の解説 by ChatGPT
HTTP 200: リクエストが正常に完了したことを示しています。
"kind": "LanguageDetectionResults": この結果が言語検出の結果であることを示しています。
"documents": テキストの集合に対する分析結果が含まれています。ここでは1つのテキスト("id": "1")の結果のみが含まれています。
"id": "1": テキストに対して指定した一意の識別子です。
"detectedLanguage": 検出された言語の詳細情報が含まれています。
"name": "Japanese": 検出された言語の名前です。ここでは日本語が検出されています。
"iso6391Name": "ja": 検出された言語のISO 639-1コードです。日本語のコードは"ja"です。
"confidenceScore": 1.0: 確信度スコアは、テキストがその言語で書かれていると言語検出モデルが判断する確率を示しています。1.0は最高スコアで、モデルがテキストが日本語であると100%確信していることを示しています。
"warnings": このリストには警告が含まれますが、今回は空です。これは分析中に問題が発生しなかったことを示しています。
"errors": このリストにはエラーが含まれますが、今回は空です。これは分析中にエラーが発生しなかったことを示しています。
"modelVersion": "2023-12-01": 使用されたモデルのバージョンを示しています。

Discussion