
離脱予測分析について2回目です。今回は最近の研究動向を紹介します。
離脱分析については以前から多くの研究があります。
最近はPOSなどで購買情報のデータ化やサブスクリプションによるビジネスモデルの影響で、ニーズが増えています。
特に、これまではWEB経由であったものがスマートフォンのアプリを経由してサービス提供を行うものが増え、顧客の維持継続が重要性を増しています。
実務に使える機械学習ということです。
離脱解析では離脱率を特徴量から識別学習を適用するものや、
Coxハザードモデルによる生存解析をするものなどいくつかあります。
さらに最近LLMを利用した研究もいくつか発表されていて注目しています。いままで特徴量として数値情報に落とし込んでいたものの中に言語情報を入れることができたり、言語で調整できる可能性があることを示しています。
今回は下の論文を順に紹介していきます。
- CHAJIA, Meryem; NFAOUI, El Habib. Customer Churn Prediction Approach Based on LLM Embeddings and Logistic Regression. Future Internet, 2024, 16.12: 453. web
- 山岡 光太, 上田 雅夫, BERTを用いた複数時系列データによる顧客離脱予測と要因分析, 人工知能学会, 2M1-GS-10-01, 2025, web jstage
- 新美潤一郎; 星野崇宏. RFMC 分析における Clumpiness 指標の拡張と自社顧客の行動予測への応用 Clumpiness を 活用した離脱時期と競合利用の予測手法の提案. 行動計量学, 2020, 47.1: 27-40.
論文紹介
CHAJIA and NFAOUI 2024
- CHAJIA, Meryem; NFAOUI, El Habib. Customer Churn Prediction Approach Based on LLM Embeddings and Logistic Regression. Future Internet, 2024, 16.12: 453. web
LLMの埋め込みベクトルを使って識別器を通して離脱の有無を判別します。
識別器(Classifier)は下の手法を試しています。
勾配ブースティング法が無いですが、主な手法をそろえています。
- ロジスティック回帰(Logistic Regression=LR)
- サポートベクターマシン(Support Vector Machine=SVM)
- ランダムフォレスト(Random Forest=RF)
- 多層パーセプトロン(Multi layer Perceptron=MLP)
- ナイーブベイズ(Naive Bayesian=NB)
- k近傍(k Nearest Neibor=kNN)
- 決定木(Decision Tree=DT)
- ゼロショット(zero-shot)
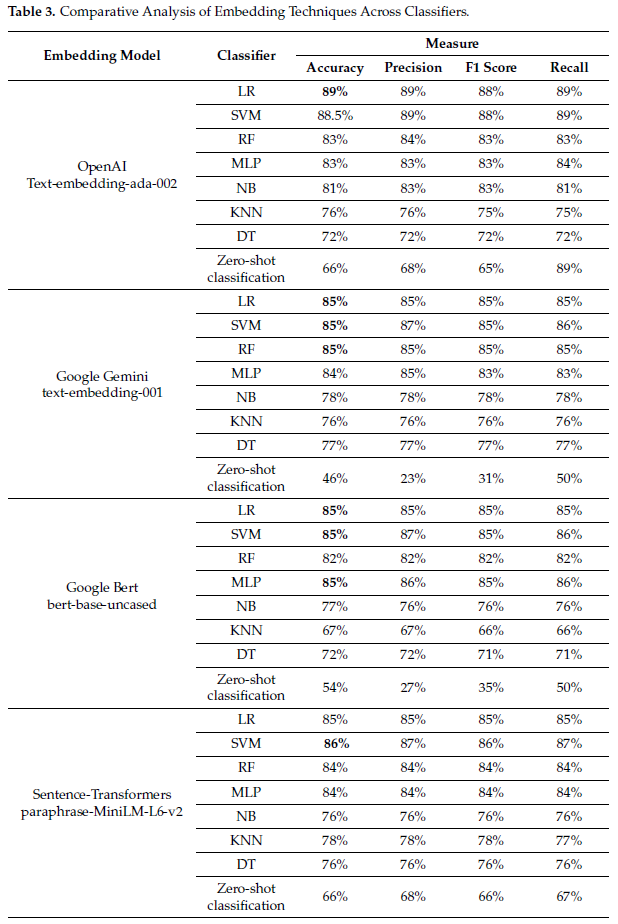
結果:
結果はOpenAI Text-embedding-ada-002+LRが一致率89%,F1=88%と高い結果となっています。
結果を見た私の所感ですがSVMもほぼ同じくらいなので、ベクトル空間ではスパースな配置になっていて明確に分割できる問題なので一番パラメータの少ない単純なLRがよい結果となったのだ思います。
埋め込みモデルを比較しているのは面白いですが、差は識別器の違いほどない印象です。
結果(Chajia & Nfaoui 2024)

山岡,上田2025人工知能学会
先日開催された日本人工知能学会全国大会で発表された研究を紹介します。
[2M1-GS-10-01] BERTを用いた複数時系列データによる顧客離脱予測と要因分析
〇山岡 光太1、上田 雅夫1 (1. 横浜市立大学) https://confit.atlas.jp/guide/event/jsai2025/subject/2M1-GS-10-01/advanced
顧客の購買情報を言語化・トークン化し、離脱をBERTでファインチューニング学習しています。
BERTモデル(Devlin et al. 2018)というのはGPTでも使われているTransformerモデルを利用しており、簡単に言うと文章を入力して、数値(今回は離脱か否かの1,0の2値)を出力するものと考えてOKです。ここでは東北大学の"bert-base-japanese-v3"モデルを使用しています。
データとしてはショッピングセンターの顧客データを使って分析をしています。
顧客別に、一週間単位で各店舗分類利用回数、利用合計金額、アプリ起動回数、スタンプ取得回数を集計して文章化しています。
新美潤一郎; 星野崇宏 2020 行動計量学
- 新美潤一郎; 星野崇宏. RFMC 分析における Clumpiness 指標の拡張と自社顧客の行動予測への応用 Clumpiness を 活用した離脱時期と競合利用の予測手法の提案. 行動計量学, 2020, 47.1: 27-40.
この論文ではCox生存解析という手法を使って分析してます。
生存解析というのは 例えば医薬分野で投薬後の生存期間のデータ分析などに用いられます。
生存時間分析に用いられる統計モデルで、ある事象(例:顧客の離脱)が発生する「リスク(ハザード)」を評価します。
特徴量の影響を定量的に捉えつつ、時間依存のベースラインリスクを仮定せずに解析できるのが特徴です。
Churn解析では、「いつ離脱するか」を予測するための時系列的なアプローチとして活用されます。
この論文ではClumpiness(塊)という概念に注目しています。
つまり、ある期間集中して購買している場合などを指標化しています。
データとしては、2例示していて、
1例目はゲームのPokemon GOの離脱分析を実施しています。
2例目はスーパーマーケットのPOSデータ分析を実施しています。
まとめ
今回は最近の言語モデルの技術を応用した離脱予測に関する興味深い研究論文を取り上げて概要を紹介しました。
離脱予測では特徴量をどうやって作るかという点を言語モデルで改善されているように思います。
とはいえ、まだユーザの複雑な状況を理解できているとは言えないように思いますので、技術的にはまだ向上の余地はありそうで、今後発展していくかもしれません。

参考論文:
- Devlin J., Chang, M., Lee, K., and Toutanova, K. (2019), BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, arXiv:1810.04805.

Discussion