やること
Titanicのデータを使い、データを視覚化する
今回は、PowerBIで可視化する
手順
- 下記のコードを実行する
df = spark.read.format("csv").option("header","true").load("Files/titanic/train.csv")
# df now is a Spark DataFrame containing CSV data from "Files/titanic/train.csv".
display(df)
- データを確認
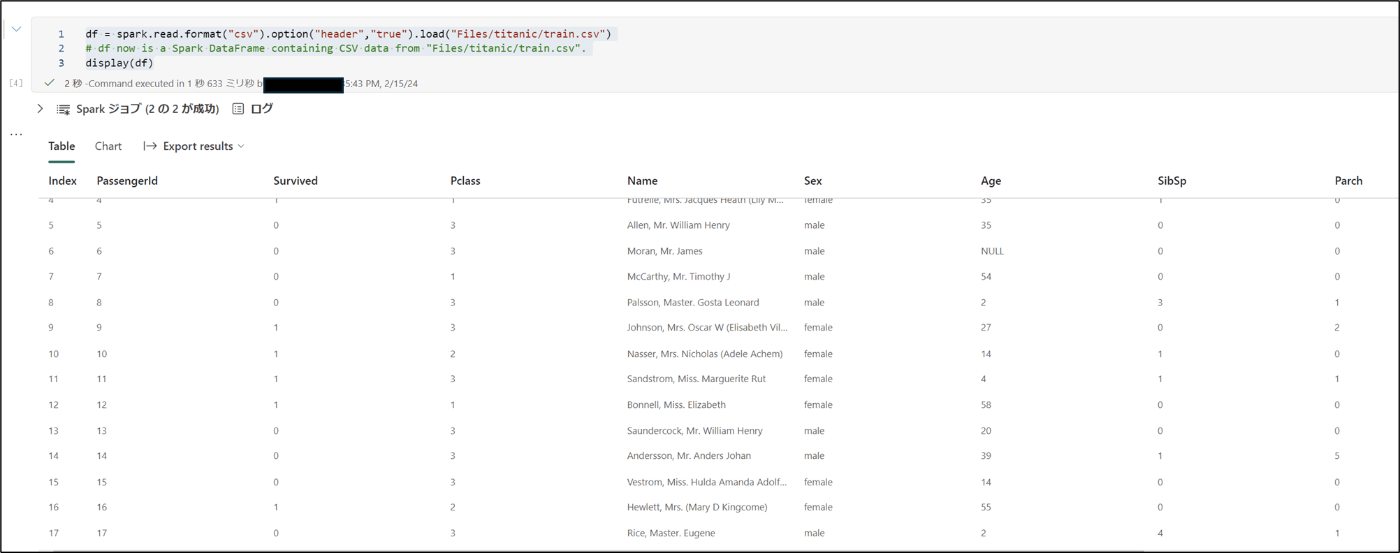
- 下記のコードを実行する
table_name = "titanic"
df.write.mode("overwrite").format("delta").save("Tables/"+table_name)
- table配下にテーブルが作成されたことを確認

- 下記のコードを実行する
# Create a spark dataframe from a Lakehouse parquet table
sdf = spark.sql("SELECT * FROM Titanic.titanic LIMIT 1000")
# Create a Power BI report object from spark data frame
from powerbiclient import QuickVisualize, get_dataset_config
PBI_visualize = QuickVisualize(get_dataset_config(sdf))
# Render new report
PBI_visualize
- PowerBIのレポートが作成されたことを確認
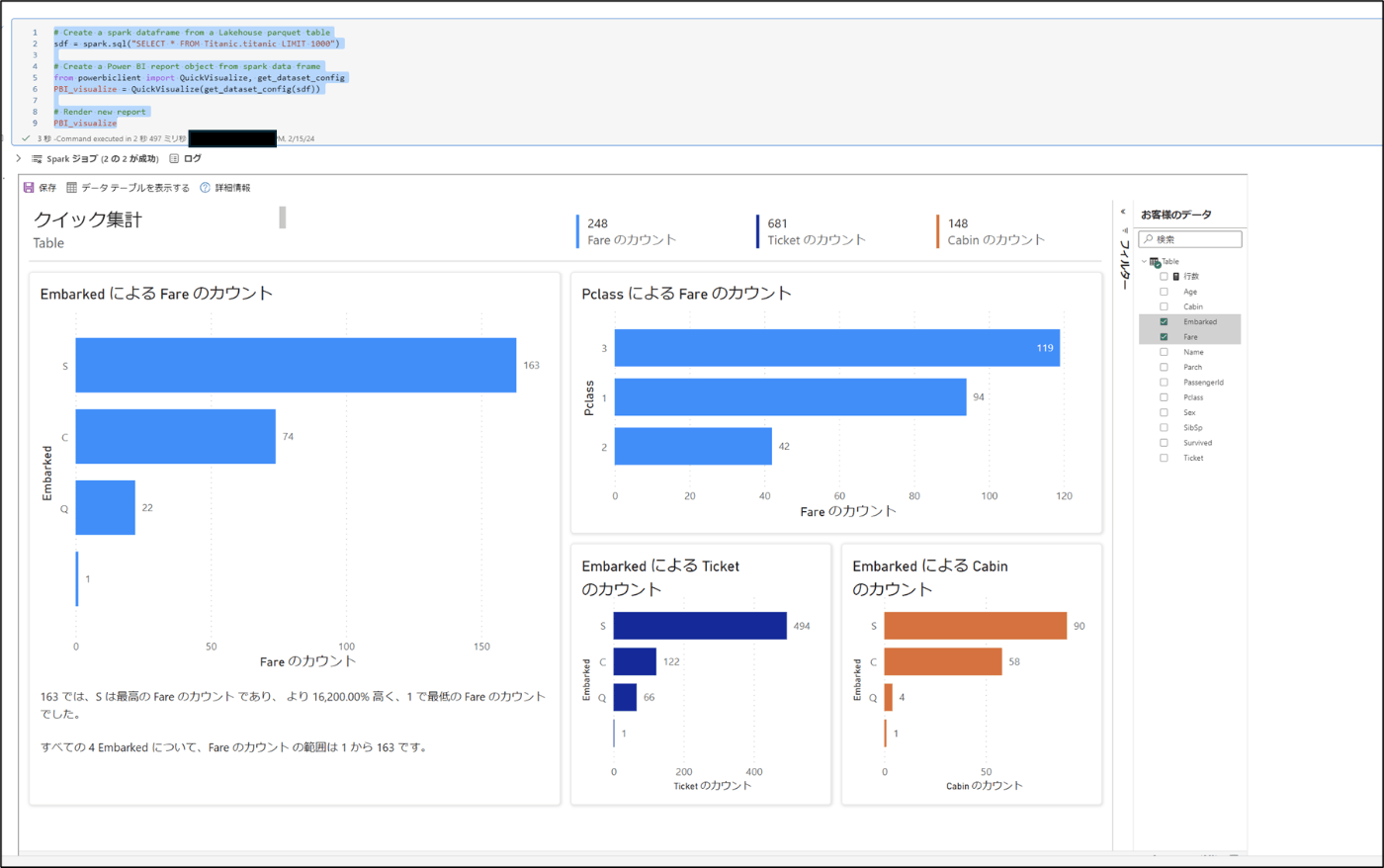
備考
csvファイルでもPowerBIのレポート作成ができる
- 下記のコードを実行する
df = spark.read.format("csv").option("header","true").load("Files/titanic/train.csv")
# df now is a Spark DataFrame containing CSV data from "Files/titanic/train.csv".
# Create a pandas dataframe from a Lakehouse csv file
from powerbiclient import QuickVisualize, get_dataset_config
# Create a Power BI report object from your data
PBI_visualize = QuickVisualize(get_dataset_config(df))
# Render new report
PBI_visualize
- PowerBIのレポートが作成されたことを確認


Discussion