やること
Data Factoryの中でNotebookを実行してみる
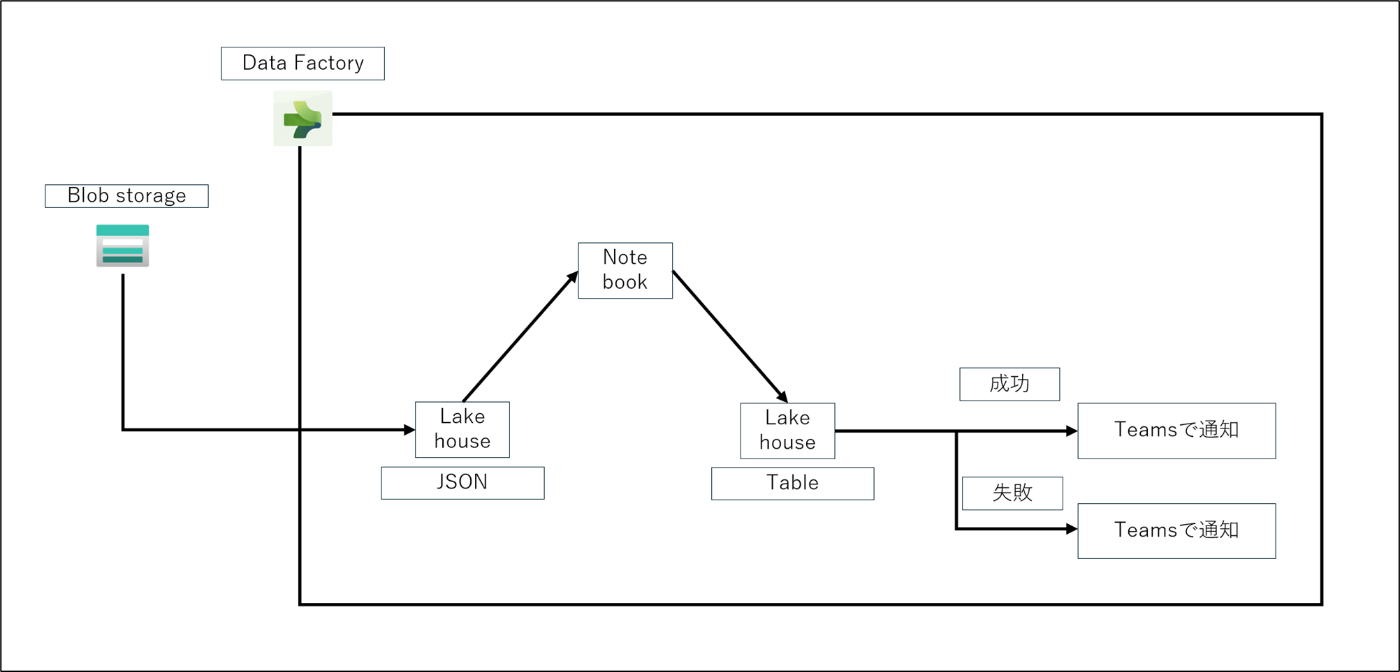
全体像
BlobからJsonファイルをLakehouseのFilesにコピーする
Notebookを起動しJsonファイルを読み込み、Tableに変換する
前提
・Azure上にAzure Blob storageを構築済みであること
・コンテナーを作成済みであること
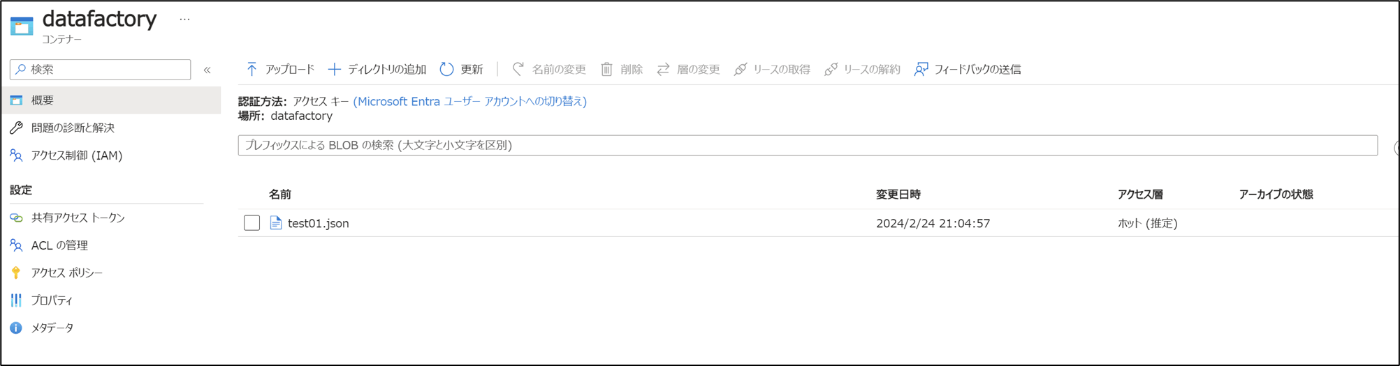
・コンテナー内に適当にjsonファイルをアップロード済みであること
↓Jsonファイルの中身
[
{"id": 1, "temperature": 23.5, "humidity": 40.1},
{"id": 2, "temperature": 24.2, "humidity": 42.3},
{"id": 3, "temperature": 22.8, "humidity": 45.6},
{"id": 4, "temperature": 24.1, "humidity": 43.8},
{"id": 5, "temperature": 25.6, "humidity": 41.2},
{"id": 6, "temperature": 23.9, "humidity": 44.5},
{"id": 7, "temperature": 24.5, "humidity": 40.6},
{"id": 8, "temperature": 22.4, "humidity": 43.9},
{"id": 9, "temperature": 23.2, "humidity": 42.8},
{"id": 10, "temperature": 24.8, "humidity": 45.7},
{"id": 11, "temperature": 25.3, "humidity": 41.1},
{"id": 12, "temperature": 23.7, "humidity": 44.4},
{"id": 13, "temperature": 24.4, "humidity": 40.5},
{"id": 14, "temperature": 22.9, "humidity": 43.7},
{"id": 15, "temperature": 23.6, "humidity": 42.9},
{"id": 16, "temperature": 24.3, "humidity": 45.8},
{"id": 17, "temperature": 25.7, "humidity": 41.4},
{"id": 18, "temperature": 23.1, "humidity": 44.3},
{"id": 19, "temperature": 24.6, "humidity": 40.7},
{"id": 20, "temperature": 22.5, "humidity": 43.6},
{"id": 21, "temperature": 23.8, "humidity": 42.5},
{"id": 22, "temperature": 24.7, "humidity": 45.9},
{"id": 23, "temperature": 25.2, "humidity": 41.3},
{"id": 24, "temperature": 23.3, "humidity": 44.2},
{"id": 25, "temperature": 24.9, "humidity": 40.8},
{"id": 26, "temperature": 22.6, "humidity": 43.5},
{"id": 27, "temperature": 23.4, "humidity": 42.4},
{"id": 28, "temperature": 24.0, "humidity": 45.3},
{"id": 29, "temperature": 25.5, "humidity": 41.0},
{"id": 30, "temperature": 23.0, "humidity": 44.1}
]
全体の手順
- Lakehouseとデータ変換用のNotebookを用意する
- Data Factoryのパイプラインを用意し、実行する
- 確認
1.Lakehouseとデータ変換用のNotebookを用意する
- Microsoft Fabric(https://app.fabric.microsoft.com/home)にアクセス

- 「Synapse Data Engineering」をクリック

- 「ワークスペース」をクリック

4.作業を行うワークスペースをクリック

5.「+新規」をクリック

6.「ノートブック」をクリック

7.ノートブックが開くことを確認

8.「Add」をクリック

9.「新しいレイクハウス」をクリックし、「追加」をクリック

- 名前を入力し、「作成」をクリック

- Notebookに下記のことを入力する
df = spark.read.option("multiline", "true").json("Files/test01.json")
table_name = "test"
df.write.mode("overwrite").format("delta").save("Tables/"+table_name)
- Notebookを保存する
2.Data Factoryのパイプラインを用意する
- Microsoft Fabric(https://app.fabric.microsoft.com/home)にアクセス
- 「Data Factory」をクリック

- 「データパイプライン」をクリック
- 名前を入力し、「作成」をクリック
- 「パイプライン アクティビティの追加」をクリック

- 「データのコピー」をクリック

- Blobに接続をし、コピーをするファイルを選択する

- コピーしたいレイクハウスを選択する

- Notebookをクリック

- 先程作成したNotebookを選択する
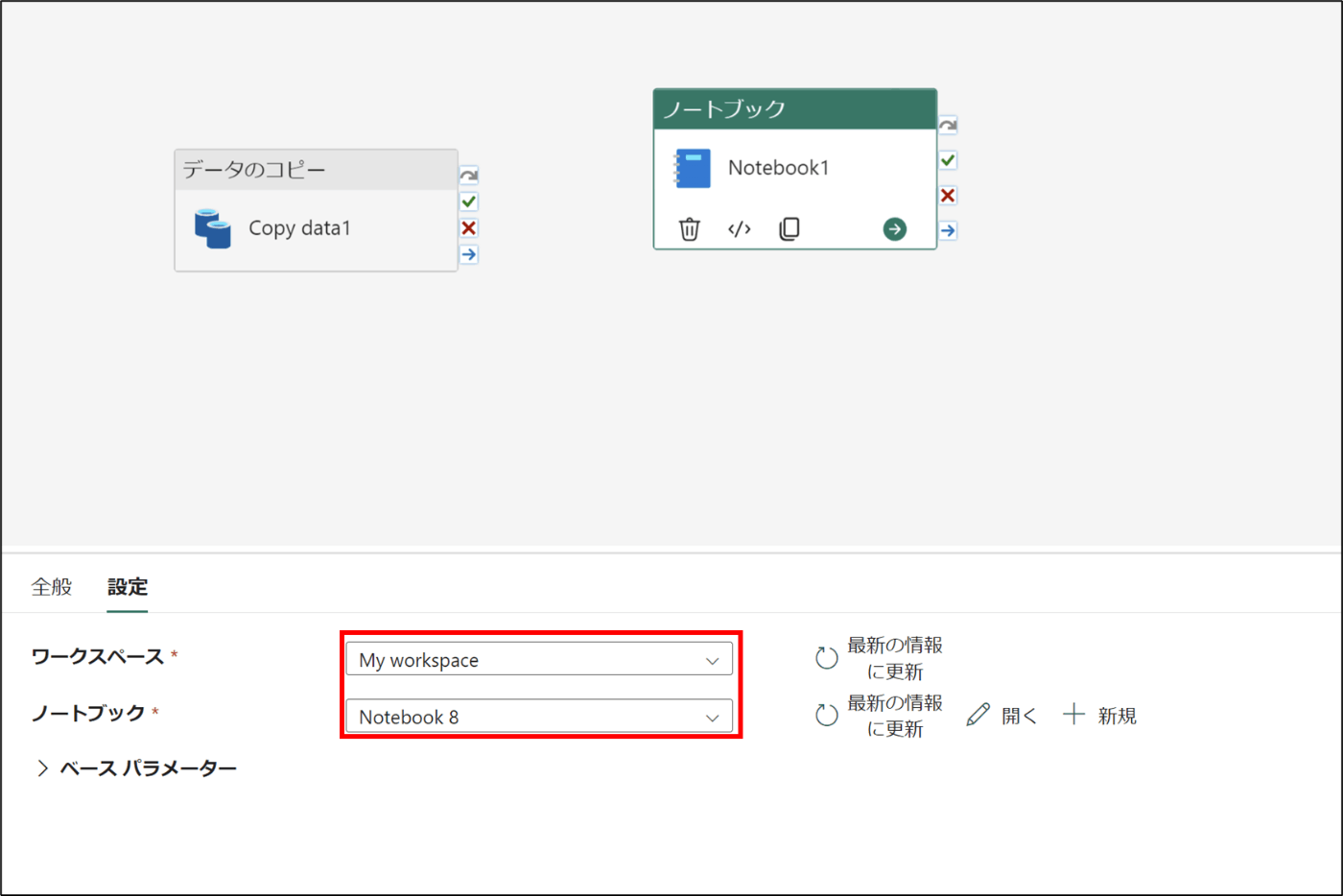
- データのコピーとノートブックを→で繋ぐ

- アクティビティを選択し、Teamsのアイコンをクリック

- 「サインイン」をクリックし、サインインをする

- 投稿したいチャネルの選択、メッセージを作成する
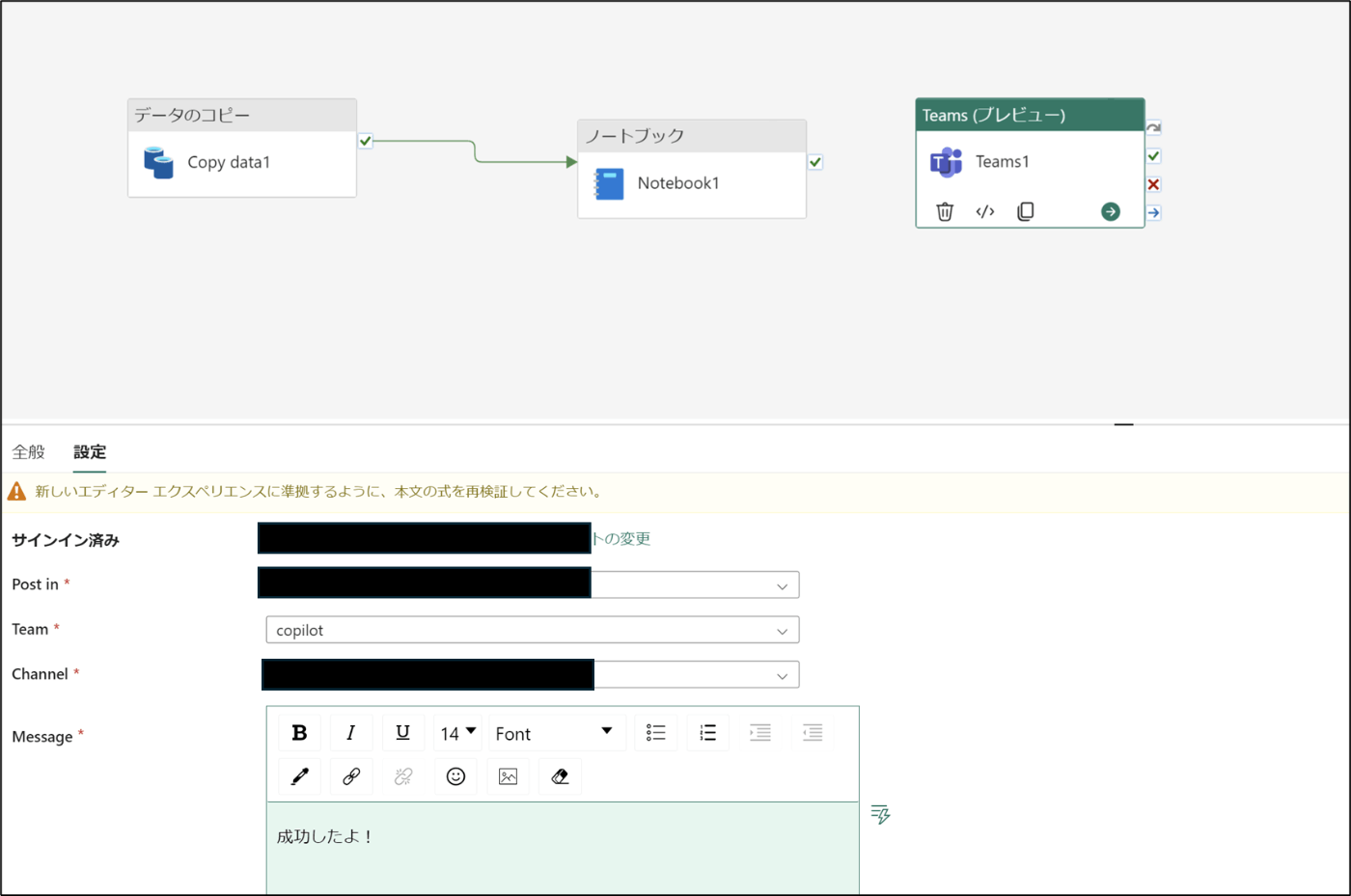
- 同様にもう一つ作成する
- 作成後、→で繋ぐ

- 「実行」をクリック

- 成功したことを確認
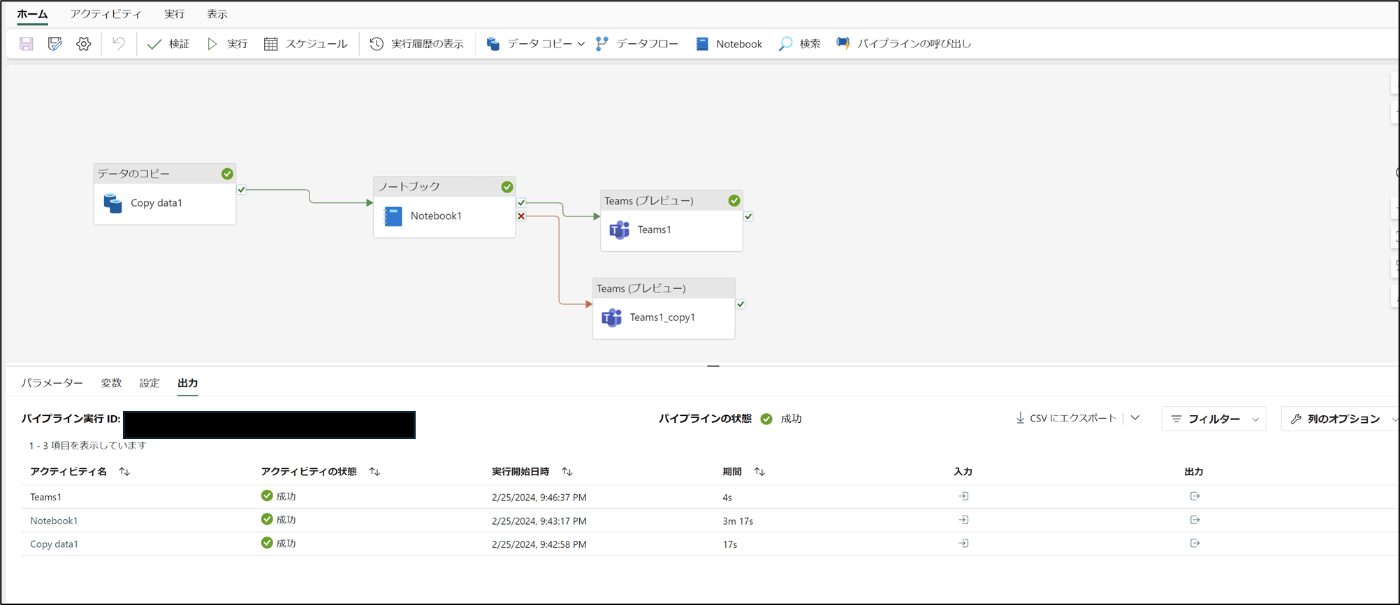
3.確認
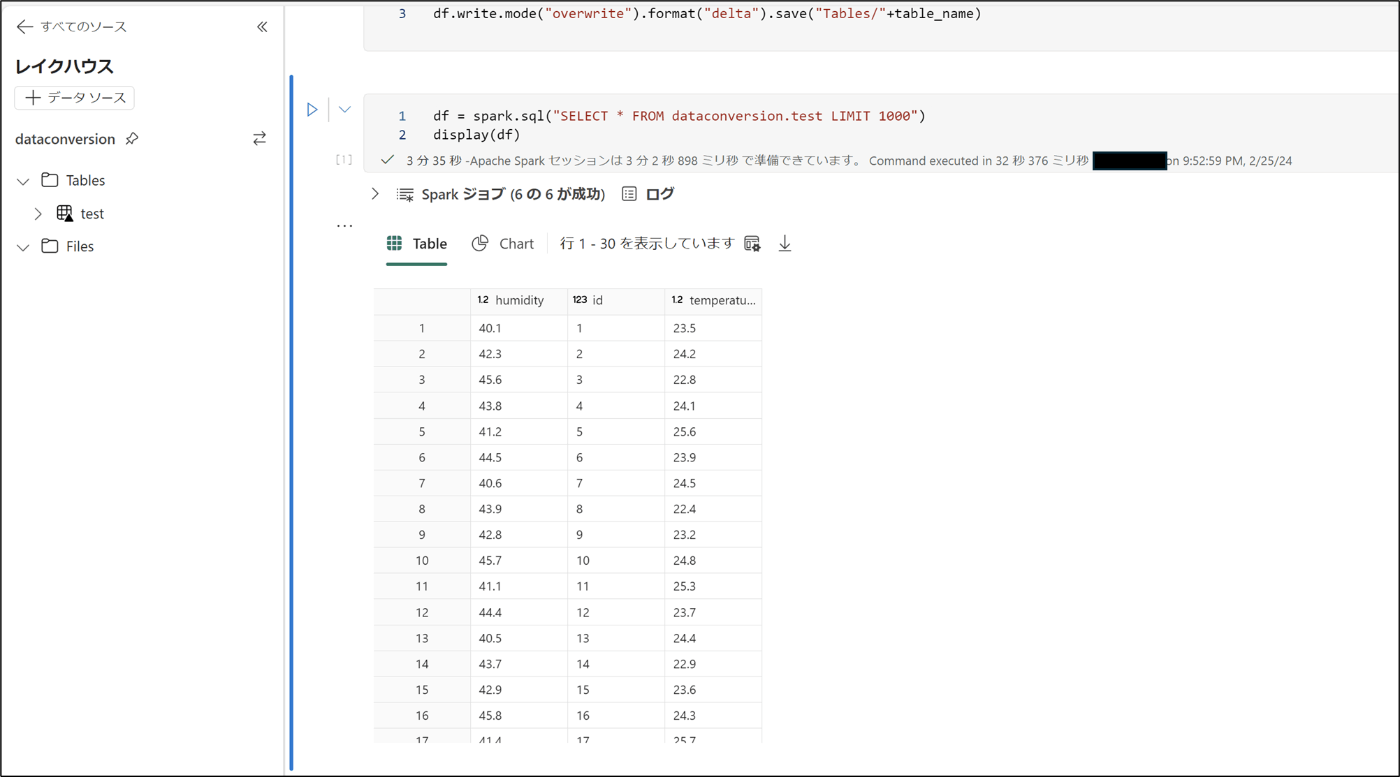
- 先程作成したNotebookを開く
- 下記のコードを実行する
df = spark.sql("SELECT * FROM dataconversion.test LIMIT 1000")
display(df)
- テーブがあることを確認
- Teamsにも成功通知が来ることを確認

まとめ
Data FactoryでNotebookを呼び出すことが出来た。
データの変換作業が楽になるなと感じました。

Discussion
非エンジニアの人でもある程度、データ周りの整備とか出来るか?という検証で、
Fabric copilot とか使って実験してみたいと思った!
あと、Notebooksも CopilotのようにAIアシスタントっている?