空間把握能力とは
VLM(Vision Language Model)と聞くと、画像が入力可能なLLMというのがシンプルな解釈ですが、個々のVLMのスペックは結構違います。
そのスペックの中でも「LLMにはなくVLM独自のもの」 & 「重要なもの」としては空間把握能力と思っています。空間把握能力とは、どれぐらい細かい粒度で画像中の物体を把握できるかということを定義とします。ピクセルや数ピクセルの単位で物体を認識できる場合にはかなり能力が高く、それができない場合には能力が低いというイメージです。
本記事では、「空間的Groudingタスクに対応したVLM」=「空間把握能力の高いVLM」としたいと思います。空間を精緻に把握しているが、把握した内容を上手く出力できないVLMもあるかもしれせんが、結局は把握能力を簡単には計測できないため、このように整理しておきます。
空間的Groudingタスクとは
空間的Groudingタスクとは、言語のクエリを用いて画像から領域の座標を出すタスクです。

空間的Groudingタスクが可能なVLM
DeepSeek-OCR

Qwen3-VL


DeepSeek-VL2


空間的Groundingタスクを可能にする技術要素
画像座標に対応するエンコーディング(M-RoPE)
文章のエンコーディングでよく使われるRoPE(Rotary Position Embedding)は、1次元のトークン列(テキスト)に対して位置情報を付与するものでした。しかし画像入力の場合、トークンは2次元座標(x, y)を持ちます。このとき、テキストと同様の1次元的RoPEを適用すると、空間的な関係(上下・左右などの構造情報)が失われてしまいます。
これを解決するために導入されたのが M-RoPE(Multimodal Rotary Position Embedding) です。
M-RoPEでは画像パッチの座標を(x, y)として回転行列的にエンコードし、Attention計算時に空間的な隣接関係を保持したまま埋め込み空間で演算できるようにします。これにより、モデルは「左上にある猫」や「テーブル上のコップ」といった位置依存の関係をより正確に扱えるようになります。

2次元での説明をしましたが、M-RoPEの提案論文では時間軸のエンコーディングも考慮されており、ビデオモーダルへの適用も図られています。
エンコーディング付き局所情報のLLMへの直接伝達
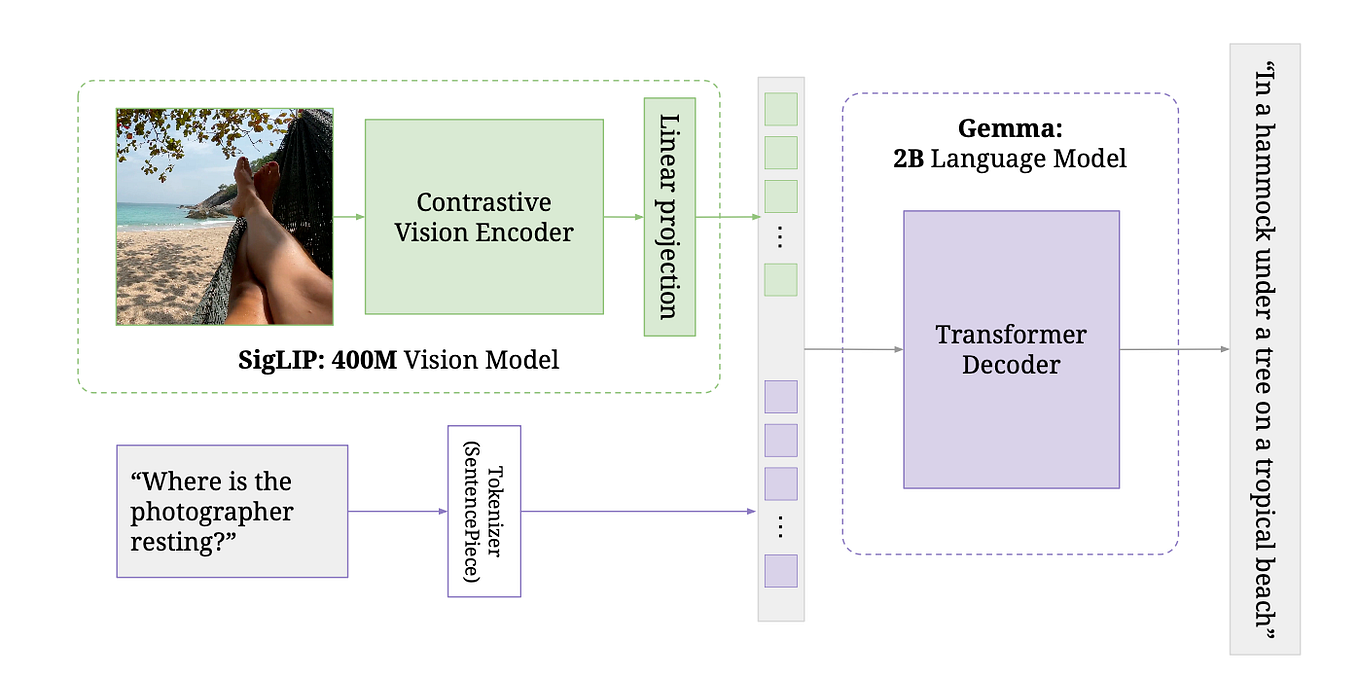
多くのVLM(例: Gemma-3, Phi4 Multimordal)は、画像エンコーダ(ViTなど)の出力を線形射影によって低次ベクトルに圧縮し、LLMに渡すという構造を取っていました。しかしこれでは、個々のパッチや物体の局所的特徴や空間的配置情報が失われてしまいます。
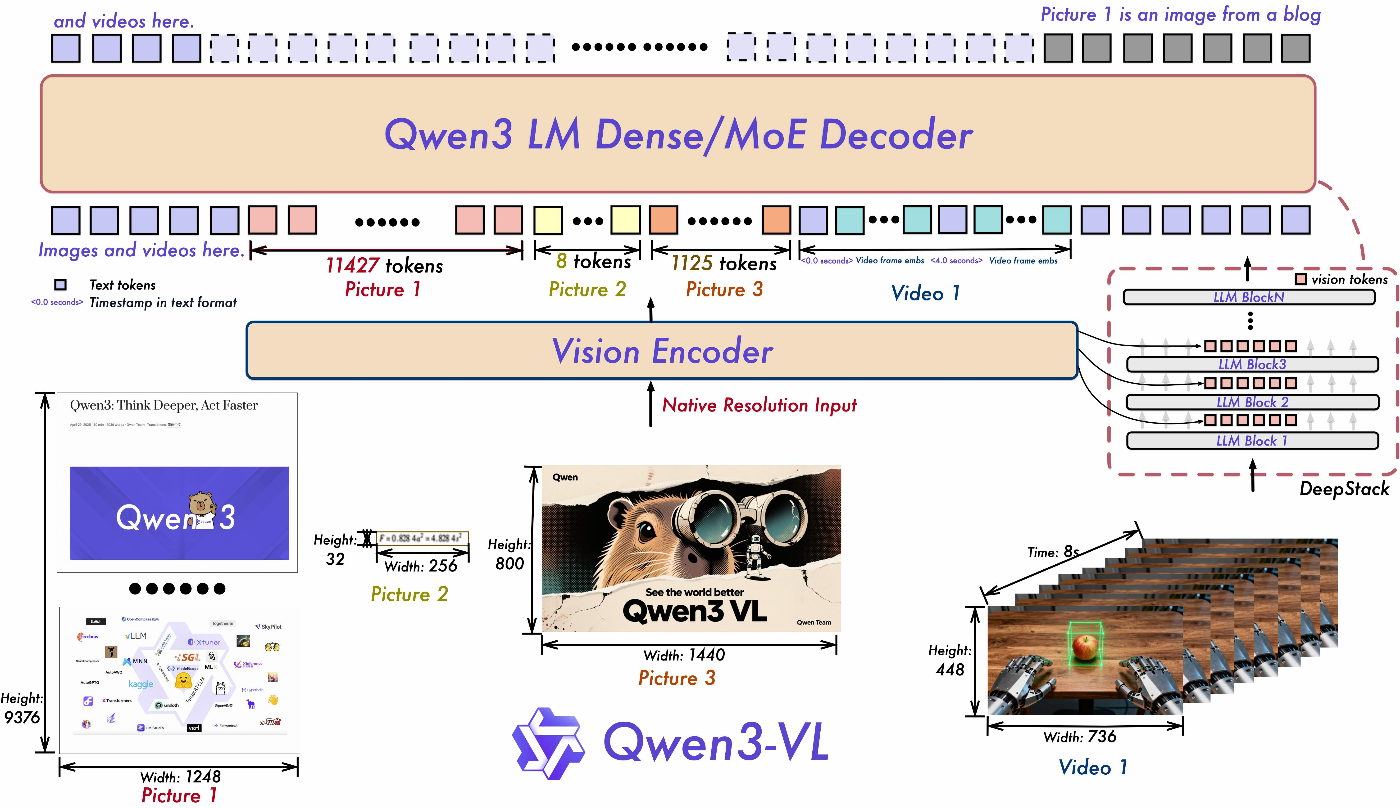
近年のモデル(例: Qwen2-VL, DeepSeek-VL2)は、局所トークンをそのままLLMに入力する設計を採用しています。これにより、LLM側のSelf-Attentionが各領域間の相対位置関係を直接学習でき、Grounding性能が大幅に向上します。
- Qwen2-VL: Scaling Open Vision-Language Models with Advanced Multimodal Alignment
- DeepSeek-VL2: Towards Spatially-Grounded Multimodal Reasoning
デコーダレイヤのファインチューニング(FT)
たとえM-RoPEなどで座標情報を埋め込んだとしても、そのままのモデルは埋込情報を領域座標として出力する設計にはなっていません。領域座標とは、[x_min, y_min, x_max, y_max] = [120, 80, 260, 220]のようなイメージです。
空間的Groundingを可能にするには、RefCOCOなどの位置アノテーション付きデータで学習し、デコーダ層に座標予測能力を獲得させるファインチューニングが必要です。

最後に
ここまで見てきたように、空間的Groundingタスクを可能にするための技術要素はいずれも「LLMへの空間情報伝達をどの程度透過的に行うか」という工夫にすぎません。
つまり、0/1の設計要素ではなく連続的な改良の積み重ねです。
というのも、CLIPやSigLIPのような画像全体エンコーディングでも、完全に空間情報を失っているわけではありません。こちらのSigLIP卵カウント実験でも、グローバル埋め込み内にも局所的な空間的手がかりが部分的に保存されていることが確認できます。
より前衛的な例としては、Gemma3でのObject Detection実験のように、本記事の内容と矛盾しているようにも見えますが、Gemma3で空間的タスクを限定的ながら実現している例も存在します。
したがって、モデルごとの「Grounding可能/不可能」を二値的に区別するのではなく、空間情報をどの程度保持・再構成できる設計になっているかという視点で捉えるのが実践的です。
そして、空間把握能力はVLMの性能を決定づける唯一の指標ではありません。
VLMはあくまで複数モーダルの統合知能を目指す枠組みであり、言語理解・推論力・世界知識・常識的推論といった他の能力も総合的に重要です。
空間的Groundingはその中の一つの軸にすぎないという点を忘れてはいけません。
補遺
- Qwen3-VLのDeepStackも関連技術と思うのですが、その特異性がよくわかりませんでした。

Discussion