やりたいこと
GPTからのレスポンスをストリーミングで受け取れるようにしたいです。
前提
以下の記事でAPIを実装しているので、これをベースにやっていきます。
実装
先に全体
main.py
from fastapi.responses import StreamingResponse
...
@app.post("/chat")
async def chat_handler(chat_request: ChatRequest):
client = AzureOpenAI(
api_version="2024-02-01",
azure_endpoint=os.environ["AZURE_OPENAI_ENDPOINT"],
api_key=os.environ["AZURE_OPENAI_KEY"],
)
messages = [{"role": "system", "content": "あなたはありとありとあらゆる情報を知っていて、サービス精神にあふれた人工知能です。ユーザーからの質問にたくさん考えて丁寧な口調で答えます。"}] + chat_request.messages
model = os.environ["AZURE_OPENAI_CHATGPT_DEPLOYMENT"]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0,
stream=True,
max_tokens=800
)
def get_gpt_streaming(chat_coroutine):
collected_chunks = []
collected_messages = []
for chunk in chat_coroutine:
collected_chunks.append(chunk)
if len(chunk.choices) != 0 and chunk.choices[0].delta.content is not None:
print(f"Chunk received: {chunk.choices[0].delta.content}")
chunk_message = chunk.choices[0].delta.content
collected_messages.append(chunk_message)
print(f"Message received: {chunk_message}")
full_reply_content = ''.join(collected_messages)
print(f"Full conversation received: {full_reply_content}")
yield chunk_message
return StreamingResponse(get_gpt_streaming(response), media_type="text/event-stream")
1. リクエストの設定
streamをTrueに変更します。
main.py
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0,
stream=True,
max_tokens=800
)
2. 値の管理
GPTからレスポンスが返ってくるたびに関数を実行して、変数に格納していきます。
main.py
def get_gpt_streaming(chat_coroutine):
collected_chunks = []
collected_messages = []
for chunk in chat_coroutine:
collected_chunks.append(chunk)
if len(chunk.choices) != 0 and chunk.choices[0].delta.content is not None:
print(f"Chunk received: {chunk.choices[0].delta.content}")
chunk_message = chunk.choices[0].delta.content
collected_messages.append(chunk_message)
print(f"Message received: {chunk_message}")
full_reply_content = ''.join(collected_messages)
print(f"Full conversation received: {full_reply_content}")
yield chunk_message
3. 返すレスポンスの型定義
main.py
from fastapi.responses import StreamingResponse
...
return StreamingResponse(get_gpt_streaming(response), media_type="text/event-stream")
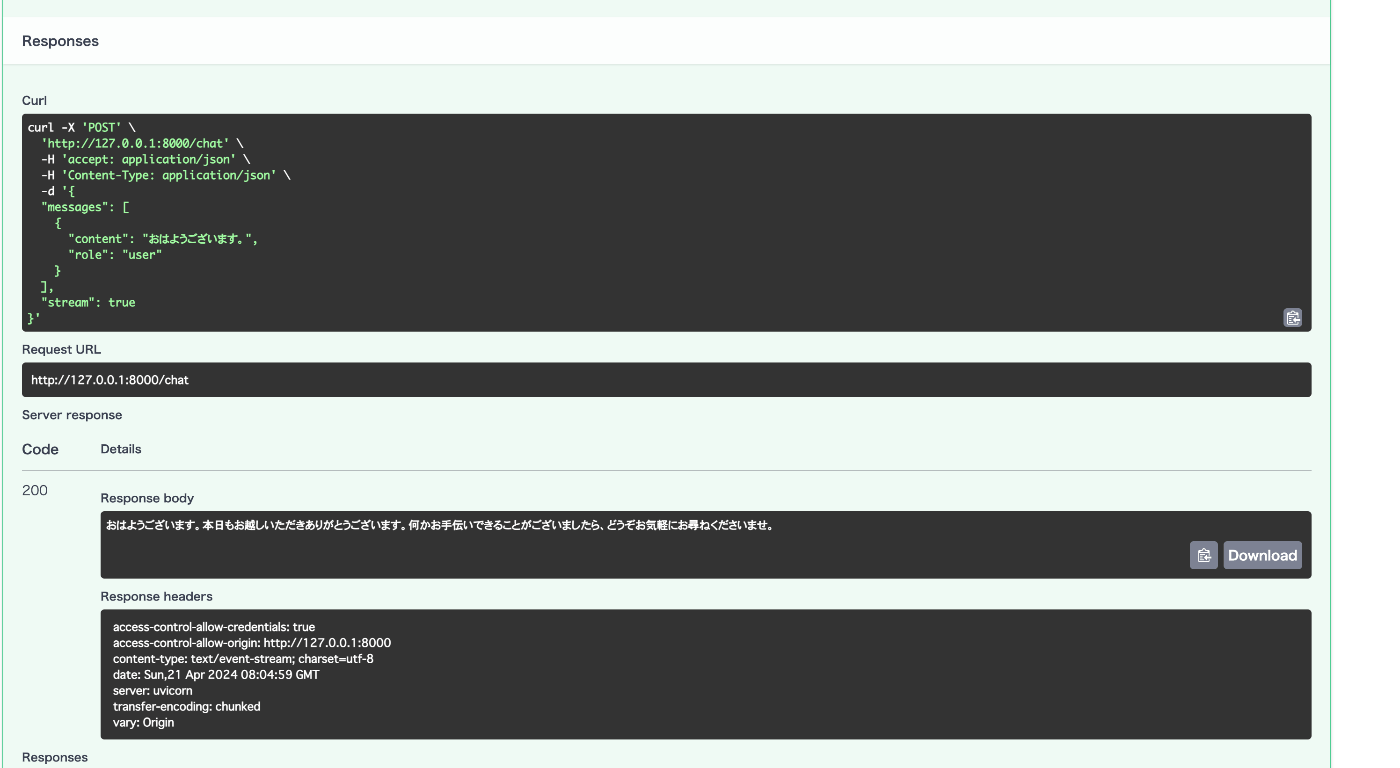
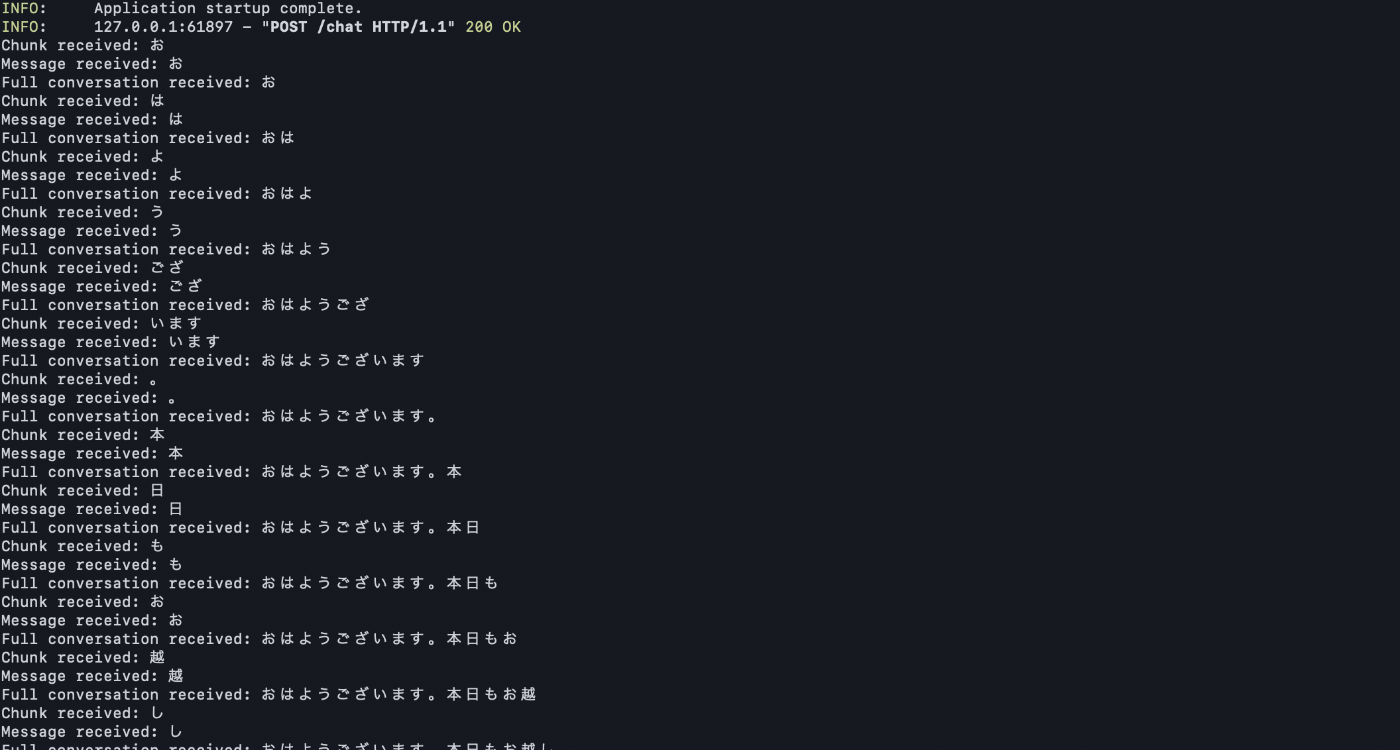
検証
上手くできました。
Swagger上だと変化が分からないですが、ログ出しするとストリーミングで返ってきてることがわかると思います。

Discussion