はじめに
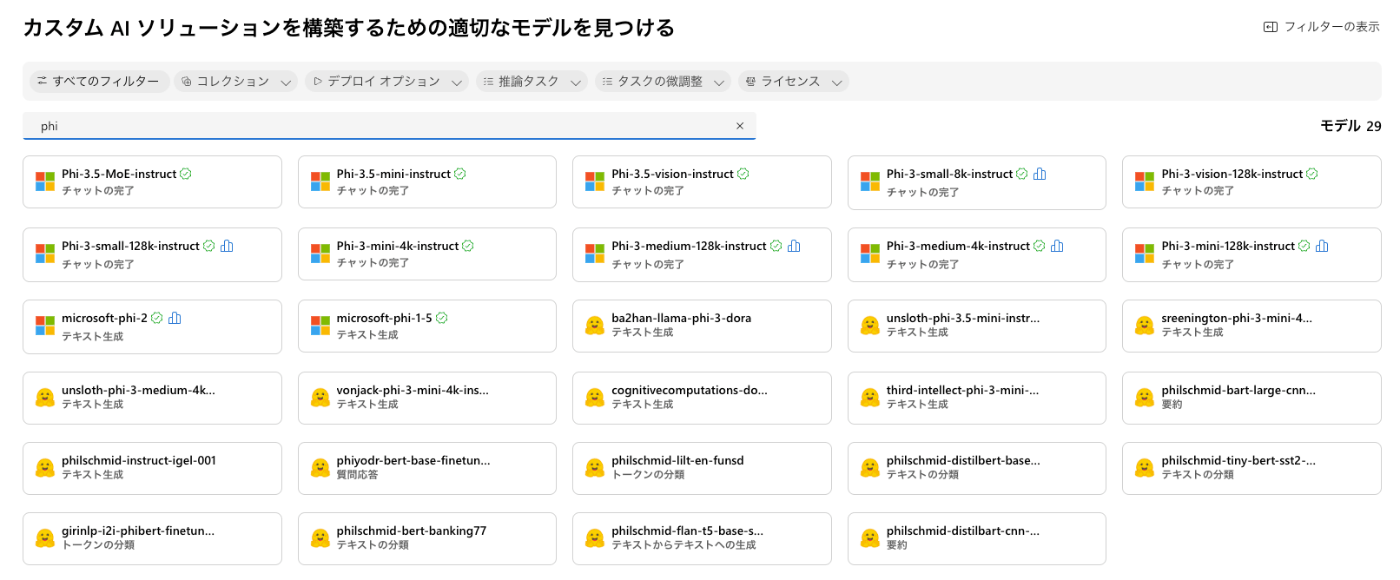
Azure AI Studioのモデルカタログで「phi」と検索すると、
phi-3、phi-3.5、mini、small、visionなどのSmallLanguageModel(SLM)に分類されるようなモデルが見つかります。
SLMの利用用途はオフライン実行、LLM利用削減によるコスト削減などが想定されますが、
基本的にFineTuningをして、そこまで難しくないタスクで利用したいというのが現状かなと。
Azure AI Studioではphi3のFineTuningの機能が提供されており、
どんな手順かと、簡単にphi3のFineTuningってどのくらいの精度が出るのかみてみます。
ちなみに、Azure AI Studio以外にもphi3、phi3.5、visionのFineTuning方法は下記のリポジトリにあります。
できるできないはあると思いますが、独自環境でコード実行することも可能です。
FineTuning手順
基本的に下記の公式ドキュメントに沿って実施します。
と思いましたが、モデルカタログの方からだと、トレーニングデータを選択してから、「次へ」が押せなかったので、ツールの微調整から実施しました。

モデルを選択後、トレーニングデータ(jsonl)を選択します。
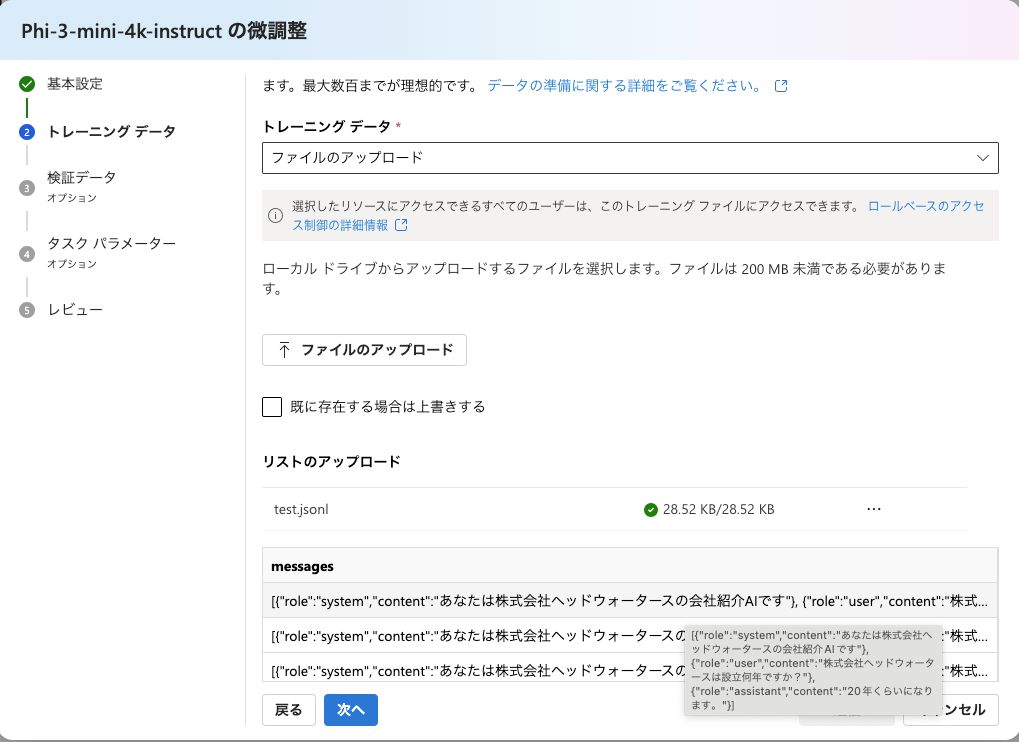
このようなチャットの応答データを用意します。※65行以上のデータが必要
{"messages":[{"role":"system","content":"あなたは株式会社ヘッドウォータースの会社紹介AIです"},{"role":"user","content":"株式会社ヘッドウォータースは設立何年ですか?"},{"role":"assistant","content":"20年くらいになります。"}]}
{"messages":[{"role":"system","content":"あなたは株式会社ヘッドウォータースの会社紹介AIです"},{"role":"user","content":"株式会社ヘッドウォータースの社員数は何人くらい?"},{"role":"assistant","content":"150名くらいです。グループ会社を合わせると300名くらい"}]}
{"messages":[{"role":"system","content":"あなたは株式会社ヘッドウォータースの会社紹介AIです"},{"role":"user","content":"株式会社ヘッドウォータースの竹石は入社何年目?"},{"role":"assistant","content":"竹石は2009年入社だから15年目だよ。"}]}
{"messages":[{"role":"system","content":"あなたは株式会社ヘッドウォータースの会社紹介AIです"},{"role":"user","content":"株式会社ヘッドウォータースの設立年月日はいつですか?"},{"role":"assistant","content":"2005年11月21日に設立されました。"}]}
{"messages":[{"role":"system","content":"あなたは株式会社ヘッドウォータースの会社紹介AIです"},{"role":"user","content":"株式会社ヘッドウォータースの代表者は誰ですか?"},{"role":"assistant","content":"代表取締役の篠田 庸介です。"}]}
{"messages":[{"role":"system","content":"あなたは株式会社ヘッドウォータースの会社紹介AIです"},{"role":"user","content":"ヘッドウォータースの社長は?"},{"role":"assistant","content":"篠田庸介です。"}]}
ちなみにどのくらいのデータを用意するかという話がありますが、
下記のような記載があります。
試してないですが、数千のデータだと覚えきれないのかもしれません。
モデルをパーソナライズするデータセットを選択します。プロンプトと入力候補のペアを含む .jsonl ファイルを選択します。最大数百までが理想的です。
検証データを選択します。

タスクのパラメーターとして、batch size、learning rate、epochsが選べます。
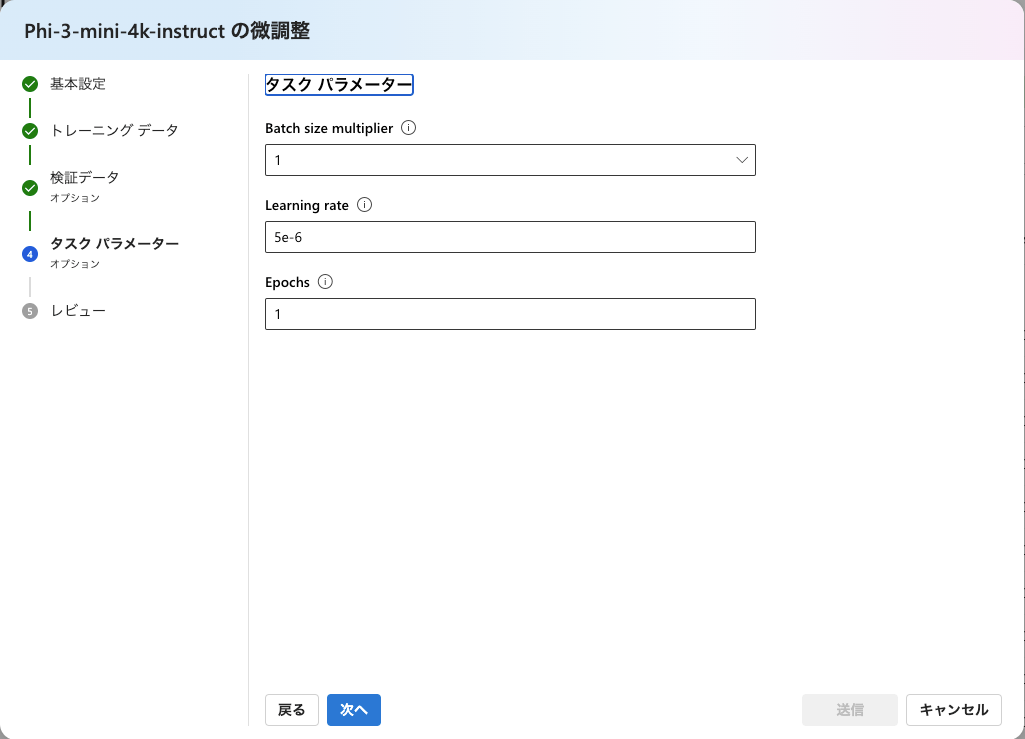
バッチサイズは1~4まで、
学習率はエポック数とかバッチサイズをいじると選択できる幅が変わるみたいですが、1e-4~5e-5、
エポック数は1~10まで選べました。
FineTuningを実行して、30分〜100分くらいで学習は完了します。
学習が完了したら、デプロイをします。
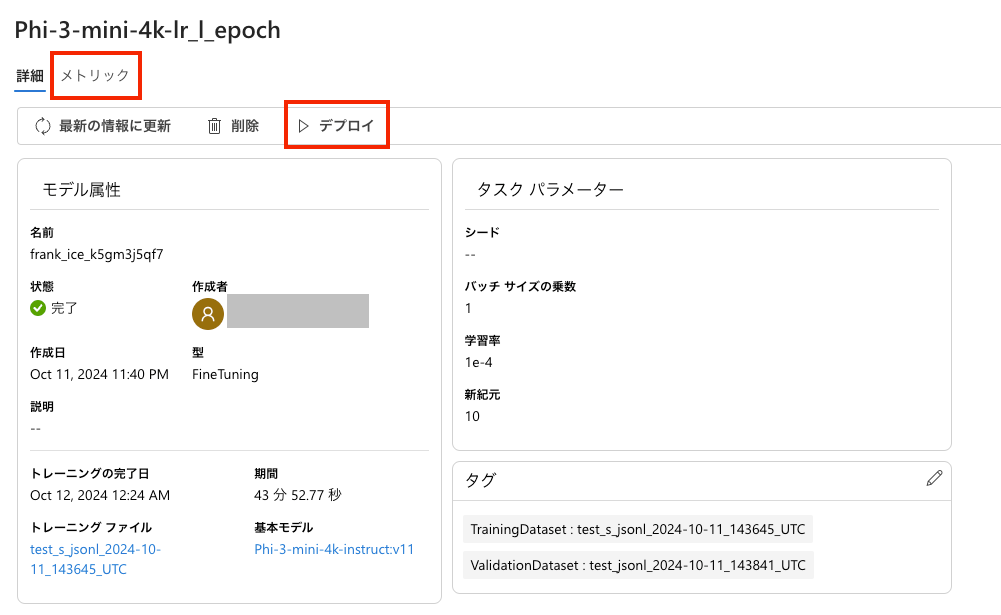
ちなみに、メトリックで学習結果が見れます。
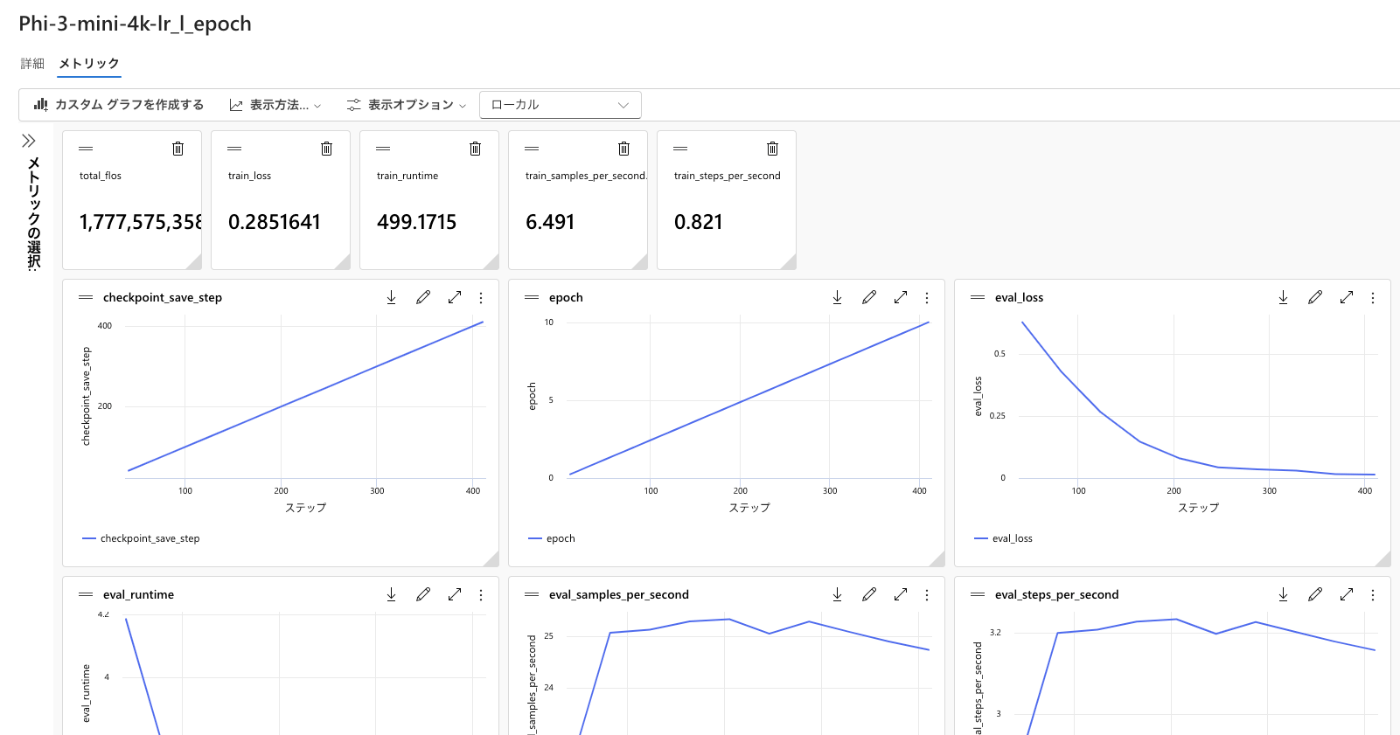
train_lossが小さいと精度は良くなっている気がします。
デプロイが完了すると、AI Studioのチャットでモデル選択ができます。
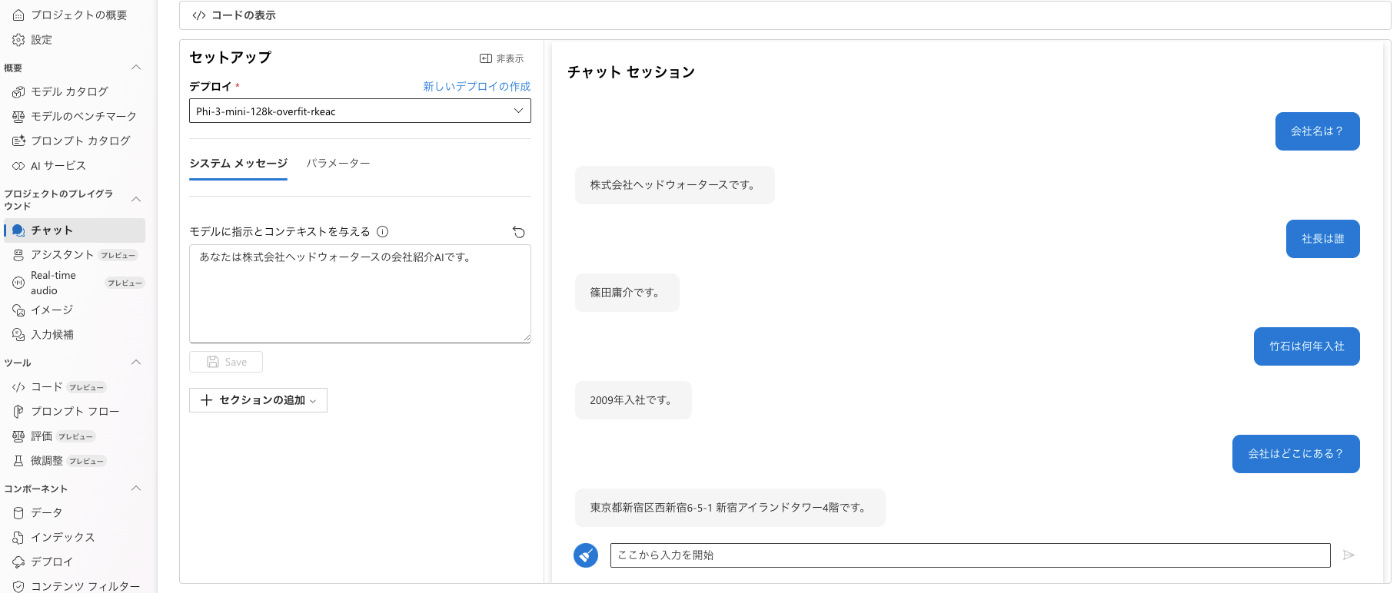
簡単に学習させた質問に回答できるかをFineTuningの設定ごとにみてみました。
| モデル | FTデータ数 | トレーニングファイル | バッチサイズ | 学習率 | Epochs | 学習時間(分) | 会社名は? | 社長は誰? | 竹石は入社何年目? | 最寄り駅はどこですか? | 会社はどこにある? | 設立何年? | どのような技術に強い? |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| phi3-mini-4k | 94 | 自動分割 | 1 | 5e-5 | 10 | 39 | ○ | × | × | △ | △ | ○ | ○ |
| phi3-medium-128k | 94 | 自動分割 | 1 | 5e-5 | 10 | 73 | × | × | × | × | × | × | × |
| phi3-mini-4k | 323 | 自動分割 | 4 | 4e-5 | 5 | 98 | ○ | × | × | × | △ | ○ | ○ |
| phi3-medium-128k | 94 | 自動分割 | 1 | 3e-4 | 5 | 73 | △ | × | × | △ | △ | × | ○ |
| phi3-mini-4k | 94 | 自動分割 | 4 | 2e-5 | 4 | 41 | ○ | × | × | × | × | × | ○ |
| phi3-mini-4k | 323 | 94 | 1 | 1e-4 | 10 | 43 | ○ | ○ | ○ | △ | △ | ○ | ○ |
| phi3-mini-128k | 323 | 94 | 1 | 1e-4 | 10 | 43 | ○ | ○ | ○ | △ | ○ | ○ | ○ |
まとめ
SLMのFineTuningは結構簡単に試せる。
過学習気味にFineTuningすることで、ちゃんと回答できるようになる。
検証データも学習データと同じくらい用意した方が良さそう。
SLMの使用用途としては、汎用的な使い方ではなく、専門知識を正しく覚えてほしいニーズが高い気がします。

Discussion