執筆日
2024/08/06
ちょっと追記: 2024/08/13
概要
社内の案件でGPT-4oで画像認識をさせたときに案件によって「OCRの精度がめちゃくちゃいい」という報告と「全然OCR上手くいかないじゃん」という報告があったため、画質によってどの程度精度に差が出るか調べてみました。
特に画数の多い漢字は、画質が低いとすぐにつぶれてしまいます。人間は文脈による推論でその漢字を予測することができますが、AIにとってはどうでしょうか。従来のCVによるOCRはつぶれた文字は確率が高い文字を出力するだけですが、VLMによるOCRはその言語処理能力によってある程度文脈に沿った文字抽出が期待できそうな気がします。またプロンプトで「誤字も読み取れるそのままを抽出してください」と言ってみたり、「読みづらい文字は文脈上正しい単語で抽出してください」と言ってみたりすることでも回答が変わるかもしれません。
そのため今回は、
- 文字認識精度が下がるまで画質を下げていく
- 精度が下がった状態でプロンプトを変更することで精度が変わるか調べる
という流れで検証してみました。
結果として、スクリーンショットそのままの画像であればかなりの精度で文字抽出できましたが、画質を下げると目視で文字がつぶれてないかなと思えるレベルでも欲しい粒度の情報が取得できませんでした。
前提
対象画像
Wikipediaを最初使おうと思いましたが学習に使われている内容はただのリーク調査になって意味がないため、Edgeの新しいタブで表示される最近のWebニュース記事のサムネイルを使いました。新規ニュースなので既知の情報は少ないはずです。切り取った元の画像は1873x1227ピクセルでした。
依存ライブラリインストール
pip install openai python-dotenv
スクリプト
スクリプトを使う場合、グローバル変数は各環境やそのときのAzure OpenAIのAPIに合わせて変更してください。
処理スクリプト
from dotenv import load_dotenv
from openai import AzureOpenAI
YEN_PER_DOLLAR = 144.55
INPUT_TOKEN_COST = 0.005 / 1000 * YEN_PER_DOLLAR
OUTPUT_TOKEN_COST = 0.015 / 1000 * YEN_PER_DOLLAR
load_dotenv("./.env")
OPENAI_ENDPOINT = os.getenv("OPENAI_ENDPOINT")
OPENAI_KEY = os.getenv("OPENAI_KEY")
OPENAI_API_VERSION = os.getenv("OPENAI_API_VERSION")
OPENAI_DEPLOYMENT_NAME = os.getenv("OPENAI_DEPLOYMENT_NAME_4O")
# ローカル画像をデータURLに変換する関数
def local_image_to_data_url(image_path):
mime_type, _ = guess_type(image_path)
if mime_type is None:
mime_type = 'application/octet-stream'
# Read and encode the image file
try:
with open(image_path, "rb") as image_file:
base64_encoded_data = base64.b64encode(image_file.read()).decode('utf-8')
except Exception as e:
print(f"Error reading image file: {e}")
return None
# Construct the data URL
return f"data:{mime_type};base64,{base64_encoded_data}"
system_message = "あなたは画像の情報をmarkdown形式で出力するAIです 要約せず書いてあることを漏れなく教えてください"
user_message = "この画像の情報を教えてください"
assistant_message = "以下が画像内の情報です:\n___\n"
messages = []
# システムメッセージ
if system_message:
messages.append({
"role": "system",
"content": [{"type": "text", "text": system_message}]
})
# ユーザーメッセージ
user_message = { "role": "user", "content": [{"type": "text", "text": user_message}] }
if image:
image_data_url = local_image_to_data_url(image)
user_message["content"].append({ "type": "image_url", "image_url": { "url": image_data_url } })
messages.append(user_message)
# アシスタントメッセージ
if assistant_message:
messages.append({
"role": "assistant",
"content": [{"type": "text", "text": assistant_message
}]
})
try:
response = client.chat.completions.create(
model = OPENAI_DEPLOYMENT_NAME,
messages = messages,
)
except Exception as e:
return str(e), None
res_message = response.choices[0].message.content
tokens = {"input": response.usage.prompt_tokens, "output": response.usage.completion_tokens}
print(f"input: {tokens["input"]:5} tokens, {tokens["input"] * INPUT_TOKEN_COST:.3f} 円")
print(f"output: {tokens["output"]:5} tokens, {tokens["output"] * OUTPUT_TOKEN_COST:.3f} 円")
結果
回答生成のパラメータはデフォルトのままのため、temperatureやtop_pなどを変更することでレスポンスが変わる可能性もありますが、おそらく劇的な変化はないため今回は割愛します。
また結果に処理時間を併記していますが、クライアント生成して最初の推論は必ずレスポンスが遅くなるため参考になりませんので注意してください。
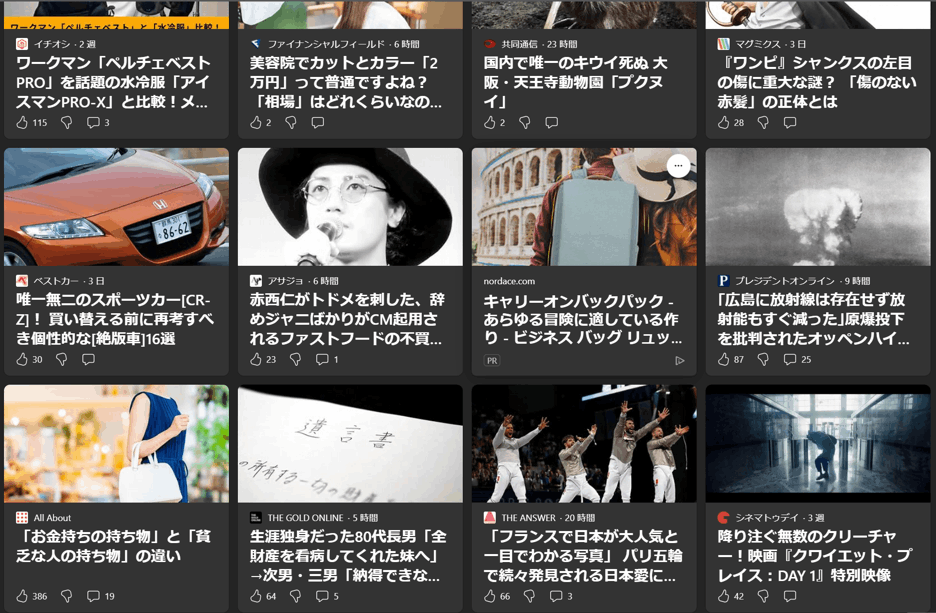
元のサイズ
確認した限り小さい文字で書かれた出版社を含むすべての文字が問題なく取得できています。それぞれの記事のタイトルを勝手に付けたり、たまに推測で途切れた文字の続きを付けたりしてくれています。
元のサイズ
-
ワークマン (イチオシ - 2週)
- 「ペルチェベストPRO」を話題の氷冷服「アイスマンPRO-X」と比較!メ…
- リアクション: 115件いいね、3件コメント
-
美容院 (ファイナンシャルフィールド - 6時間)
- カットとカラー「2万円」って普通ですよね?「相場」はどれくらいなの…
- リアクション: 2件いいね
-
国内唯一のキウイ (共同通信 - 23時間)
- 国内で唯一のキウイ死ぬ 大阪・天王寺動物園「ブクタ」
- リアクション: なし
-
ワンピース (マジックス - 3日)
- シャンクスの左目の傷に重大な謎?「傷のない赤髪」の正体とは
- リアクション: 28件いいね
-
車 (ベストカー - 3日)
- 唯一無二のスポーツカー[CR-Z]!買い替える前に再考すべき個性的な[絶版車]16選
- リアクション: 30件いいね
-
赤西仁 (アサジョ - 6時間)
- がドドメを刺した、辞めジャニばかりがCM起用されるファストフードの不買...
- リアクション: 23件いいね、1件コメント
-
バックパック (nordace.com)
- キャリーオンバックパック - あらゆる冒険に適している作り - ビジネス バッグ リュック
- リアクション: PR (広告)
-
広島に放射能 (プレジデントオンライン - 9時間)
- は存在せず放射能もすぐ減った」原爆投下を批判されたオッペンハイ...
- リアクション: 87件いいね、25件コメント
-
お金持ちの持ち物 (All About - )
- と「貧乏な人の持ち物」の違い
- リアクション: 386件いいね、19件コメント
-
遺言書 (THE GOLD ONLINE - 5時間)
- 生涯独身だった80代長男「全財産を看病してくれた妹へ」→次男・三男「納得できな...
- リアクション: 64件いいね、5件コメント
-
フランスで日本が (THE ANSWER - 20時間)
- 大人気と一目でわかる写真 パリ五輪で続々発見される日本愛に...
- リアクション: 66件いいね、3件コメント
-
降り注ぐ無数のクリーチャー (シネマトゥデイ - 3週)
- 映画「クワイエット・プレイス:DAY 1」特別映像
- リアクション: 42件いいね
Time: 12.138 s
input: 1002 tokens, 0.724 円
output: 757 tokens, 1.641 円
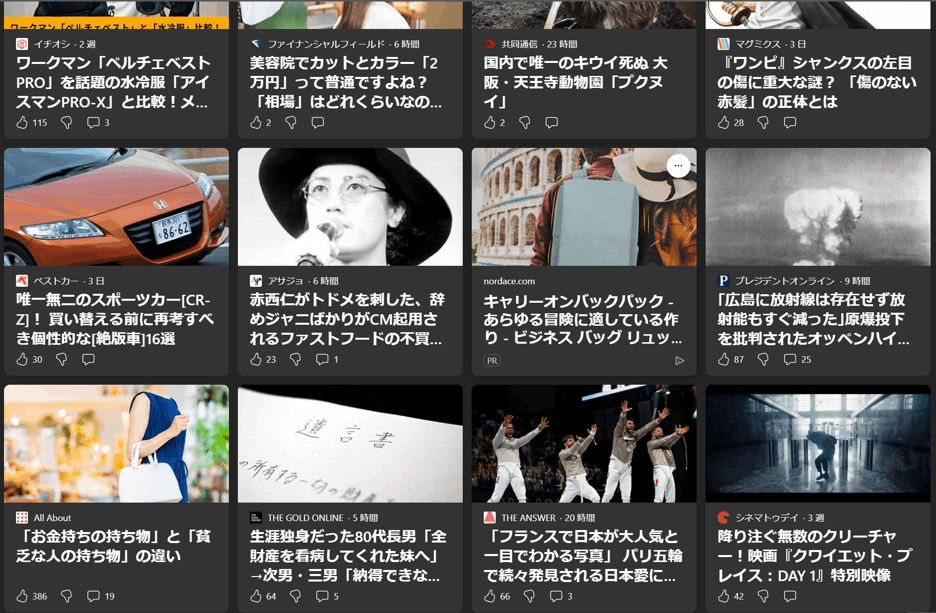
1/2サイズ
まだほぼ文字がつぶれず読めるレベルなので問題ないかと思いましたがすでにかなり認識精度が悪くなりました。(詳細に画像も貼っています)
また画数が多く文字がつぶれやすい漢字よりも、比較的単純でつぶれにくいカタカナの認識精度がかなり悪くなったのが意外な結果です。漢字の方が熟語として学習されやすく推論精度が上がるのでしょうか。
1/2サイズ
- ワークマン「ベルチエベストPRO」を話題の水冷服「アイスマンPRO-X」と比較!メリット・デメリットは?
- 115 likes, 3 comments
- 美容院でのカットとカラー「2万円」って普通ですよね?「相場」はどれくらいなの?
- ファイナンシャルフィールド, 6時間
- 2 comments
- 国内で唯一の中ウイ死ぬ大阪・天王寺動物園「ブタオ」
- 共同通信, 23時間
- 1 like
- 「ワンピ」シャンクスの左目の傷に重大な謎?「傷のない赤髪」の正体とは
- マジシャン, 3日
- 28 likes
- 唯一無二のスポーツカー「CR-Z」! 買い替える前に再考すべき個性的な絶滅車16選
- ベストカー, 3日
- 30 likes, 9 comments
- 赤西仁がドヤんを刻した、辞めジャニにばかりCM起用されるファストフードの不買記 事
- アサジョ, 6時間
- 23 likes, 1 comment
- キャリーオンバックパック - あらゆる冒険に適している作り・ビジネスバッグ リュック
- Norace, PR
- 「ワンピ」シャンクスの左目の傷に重大な謎?「傷のない赤髪」の正体とは
- マジシャン, 3日
- 28 likes
- 広島に放射線は存在せず放射能もすぐ減った∥原爆投下を批判されたオッペンハイマー
- プレジデントオンライン, 9時間
- 87 likes, 25 comments
- 「お金持ちの持ち物」と「貧乏な人の持ち物」の違い
- All About
- 336 likes, 19 comments
- 生涯独身だった80代民号「全財産を有償してくれた旅人へ」と次・三男「相続できた喜 び
- THE GOLD ONLINE, 5時間
- 64 likes, 17 comments
- 「フランスで日本が大人気と一目でわかる写真」パリ五輪を発表される日本愛に溢れる感 動
- THE ANSWER, 20時間
- 66 likes, 3 comments
- 降り注ぐ無数のクリーチャー!映画「クワイエット・プレイス:DAY1」特別映像
- シネマカフェ, 1日
Time: 17.468 s
input: 721 tokens, 0.521 円
output: 643 tokens, 1.394 円
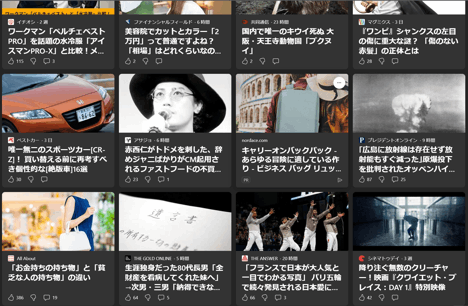
1/4サイズ
ここまでくるとコメント不要のひどい結果になりました。アップすれば人間が全然読めるレベルなのでこれくらいならいけると思っていたので、さらに画質を落としたものも用意していましたが不要でした。
1/4サイズ
-
記事1
- カテゴリ: Auto
- タイトル: 欧州市場で「マルチエストレマPRO」を追加の次世代「アイスマンPRO-X」も上陸!メルセデスのEV改良案
-
記事2
- カテゴリ: ファイナンス/投資
- タイトル: 賃貸でカットされた「2万円」とさよなら形ですか?「マイホーム組」ほど喜んないもの
-
記事3
- カテゴリ: 国内ニュース
- タイトル: 国内学者の中のディス島大阪・天王寺動物「ブラス合戦」
-
記事4
- カテゴリ: PC/スマートフォン
- タイトル: ゲノム ジャンクスの女目の前に左遷させ半「縛のない体言」の正反法を
-
記事5
- カテゴリ: バズ(車/食べ物)
- タイトル: ホンダの大将スポールーCR-Z11月企画刷新 乗り心地考え「スポーツカープレイの限界を教わった」モデル名
-
記事6
- カテゴリ: その他ニュース
- タイトル: 赤池トドが炎に沈みした。静かにサカしたあとCM起用局もカラフルスウトートの恐怖文
-
記事7
- カテゴリ: 経済
- タイトル: キャリーオンバクパック、ありそうな影響試しているツド・ビジ女子バグリョウフリ
-
記事8
- カテゴリ: ファンタジー文学
- タイトル: 伝説的な船員が復活する空間「完璧なセイターのへんフィ」
-
記事9
- カテゴリ: メディア
- タイトル: 「お産のお勧め」と「責任つ次のも持ち」白い
-
記事10
- カテゴリ: 英語
- タイトル: 四季合計成れお勧め「全を正に応える試練」所で思しず「何者できぬ読書」
-
記事11
- カテゴリ: 日常生活
- タイトル: 「フランス屈指のお笑い先を選び出応援する」リーダーを特国内日本と散策活動も皆絶賛
-
記事12
- カテゴリ: スポーツ/フィットネス
- タイトル: 成田悩嘆のフィーダチ解き!ワンダートップ・アドバイズDAY11映画検証
Time: 10.922 s
input: 304 tokens, 0.220 円
output: 664 tokens, 1.440 円
システムプロンプト変更
1/2サイズの画像を元にシステムプロンプトを変更して効果があるか調べてみました。
# system_message = "あなたは画像の情報をmarkdown形式で出力するAIです 要約せず書いてあることを漏れなく教えてください"
system_message = "あなたは画像の情報をmarkdown形式で出力するAIです 要約せず書いてあることを漏れなく教えてください 読みにくい情報は前後関係から推測してください"
改めて詳しく結果は出しませんが、いくつかプロンプトを試してみてもOCRにおいてGPTに推測を挟ませると精度を悪化させる結果となりました。(GPTが知っている知識であれば改善するかもしれません)
背景色の影響確認
ダークモードのグレー背景に白文字は学習データに少なかったりしないかなと思い、通常モードで白背景黒文字のデータを試しましたが特に精度に影響はなさそうでした。
感想
今までPDFやパワーポイントの画像化である程度きれいな文字しか読ませたことがなかったため、スクリーンショットで取得した画像で思った以上にOCR精度が落ちるのが早いことに驚きました。また、プロンプトによる推論を含んだOCRはGPTが未知の情報に対しては全く効果がないどころか結果を悪化させることがわかりました。精度を求めるのであればそれなりの画質の画像を用意する、安定して認識できないレベルの画像しか用意できないのであれば、他の方法を試すか超解像度モデルの利用など検討するのが良いと思います。
追記
2024/08/13
文章の密度が高いデータ例として法令をまとめたサイト(法令リード)から労働基準法の文章をPDF出力して分析してみました。
文字認識自体の精度は問題なかったのですが、段落番号に漢数字とアラビア数字が混ざっていると混乱してしまい番号振りがめちゃくちゃになる傾向がありました。Transformerが意味を理解する過程で漢数字かアラビア数字かという情報が落ちるのかもしれません。プロンプトである程度制約を付けることで解決できるかもしれませんが、プロンプティングは確実な制御にならないのでその精度が必要にならない使い方が良いと思います。
また、このサイトや厚生労働省でダウンロードすると読みやすいフォント(おそらくMeiryo系)で出力してくれるのですが、案件で遊ゴシック系でかつさらに文字密度が高い文書を処理したところ認識精度が下がりました。文字密度の問題か、遊ゴシック系の細い線が読み取りづらかったのかわかりませんがそのような文書を扱う場合も注意が必要そうです。

Discussion
いい勉強になりました!
やはり数字と文字を混ぜ合わせるところは画質がある程度良くないと駄目ですね。