はじめに
AOAIプロジェクトを進める中で、チーム内でPTUに関する議論が行われました。
「PTUってなんだろう?」と思って調べたので、記事にまとめてみました。
以下はMicrosoftの公式ドキュメントです。
PTUとは何か
PTUは、デプロイに必要なスループット(データが処理される速さ)を指定できる機能であり、
モデル処理の容量の単位です。
PTUは必要なモデル処理容量を割り当て、準備ができていることを保証します。
処理容量はモデルの種類やバージョンによって異なります。
一言でいうと「あなたのAOAIリソースだけで、これくらいのトークン数や通信幅を予約しておくよ」という仕組みがPTUです。
スループットを事前に割り当てるメリット
1.予測可能なパフォーマンス
一定のワークロードやシナリオに対して安定した最大遅延時間とスループットを提供します。
既存のプロビジョニングよりもスループットの増分が小さいことが保証されているため安定した遅延時間を提供できるようです。
処理容量を事前に把握できるため、スループットを超えたときの処理の遅延具合をある程度予測することが可能です。
2.予約済みの処理容量
デプロイ時にスループットの量を設定します。一度デプロイされると、使用されていなくても処理の容量は確保されています。
3.コスト節約
高スループットのワークロードは、トークンベースの消費と比べてコスト節約が可能です。
Azure OpenAI Deploymentは、特定のOpenAIモデルの管理単位です。デプロイメントは、顧客が推論のためのモデルにアクセスし、Content Moderation(コンテンツの適正化)などの機能を統合します。
モデル処理容量の使用率適用の仕組み
Provisioned-Managed Utilizationメトリックは、特定のデプロイされたモデルの使用率を1分単位で測定します。
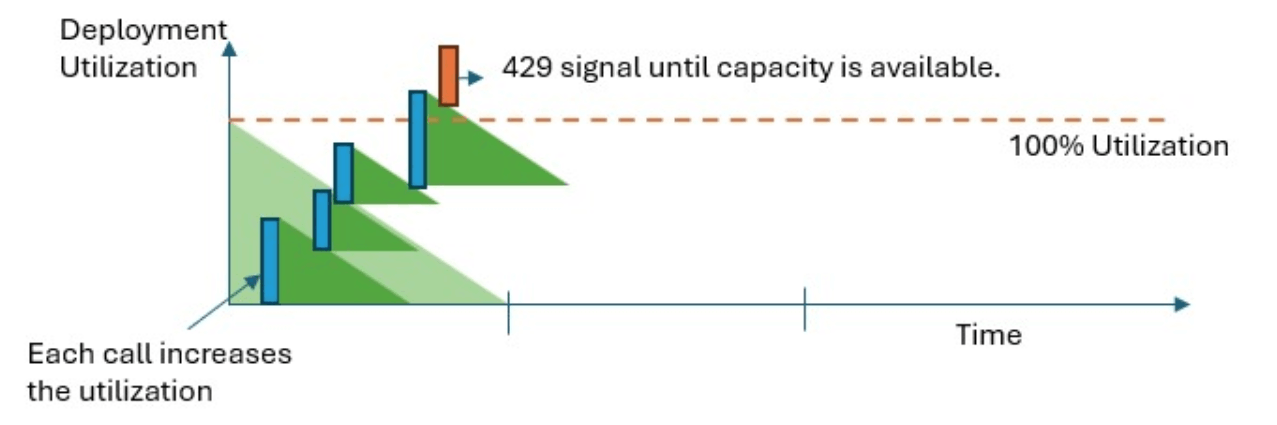
1分間でPTUの容量を超えてしまうと、用量の使用率が100%を下回るまで429 HTTPステータスコードを返し続けます。
例えば、PTUは30万トークン/分という要件のAOAIモデルを使ったアプリケーションで、ユーザーが1万人いる想定で考えてみます。
全ユーザーが一斉にアプリでGPTのAPIをコールした時に、1分間に30万トークンを超える処理になってしまうはずです。その場合、一部のユーザーはPTUが超えてしまったため429エラーが返ってきます。設計にもよりますが、数秒待機してリトライ処理が実行され、その時にPTU容量が100%以下なら実行され、100%以上だったらまた待機するという流れになります。
下図は、PTUのしきい値を超えたときの処理のイメージを図式化したものです。
429レスポンスを受け取ったときには何をすべきか
429レスポンスはエラーではなく、デプロイされたモデルがある時点で完全に利用されていることをユーザーに通知するための仕組みの一部です。この応答のハンドリングはアプリケーションの要件に応じて自由に決定できます。
それ以上の話はアプリの設計や要件定義のときに議論すべきですが、PTUをこえる処理が実行される可能性がある場合は、この記事の内容を踏まえて設計や要件定義を進める必要があります。
最後に
Githubに色々書いているっぽいので興味ある方は御覧ください。

Discussion
凄い勉強になる!
助かる!
今更読みましたが、わかりやすいです!!