こんにちは。株式会社ヘッドウォータースの新卒1年目の戸嶋隆太と申します。
今回は、AIとは何かという部分を重点に、どのようにして動いているかの解説記事を作成しました。
AIを使ったことはあるけど、仕組みがいまいちわからないという方の理解の助けになればと思います。
本記事の目的
- AIの簡単な理論について理解できるようになる
- (自身が教える際のメモ書きとして)
AIとは
私は、「既存データのパターンを学習した数理モデル」 と捉えています。
これでは抽象的すぎるので分解して解説します。
-
既存データのパターンとは?
1つのデータを表すときにはそのデータらしい数値の傾向が存在します。これらの数値の大小や並びのことをデータのパターンと呼びます。時系列データ(文字列・音声など)では、文法や発話の順番などもパターンに含みます。このように、分類やデータの種類により、人間に見えやすい・見えにくいに問わず、パターンは無数に存在します。下記は、データから得られるパターンの例です。
-
例1)イチゴとみかんの数値的なパターン
赤み・丸みの2軸を設定しそれぞれの最大値を100とするとき、
イチゴは、赤みが80~95、丸みは30~60
みかんは、赤みは50~70、丸みが70~80 -
例2)数字の画像のパターン
下記の画像内の左の数字の画像は右の一列になった白黒のパターンで表現される。

-
例3)文字列のパターン
「私は今日、焼き鳥を食べました。」
意味的なパターン例
「焼き鳥」という単語があるから「食べました」という動詞が来る。
文法的なパターン例
「私」、「焼き鳥」の名詞の後ろに助詞がある。文末に「。」がある。
-
-
学習とは?
入力されたデータが適切な分類や予測値になるように、数理モデルの中のパラメータ(係数)の値を適切なものに変更することを指します。
学習の際は、恣意的に作成した関数(損失関数)を用いて、元のデータと同じ数値が出力されるよう調整を行います。 -
数理モデルとは?
私の解釈ですが「実世界上の現象を数学的な理論に基づいてモデリングしたもの」と捉えています。
AIでは、多くの多項式や微分、時にはグラフ理論、生体化学(人の脳の構造)などを用いてモデリングします。
AIの分類
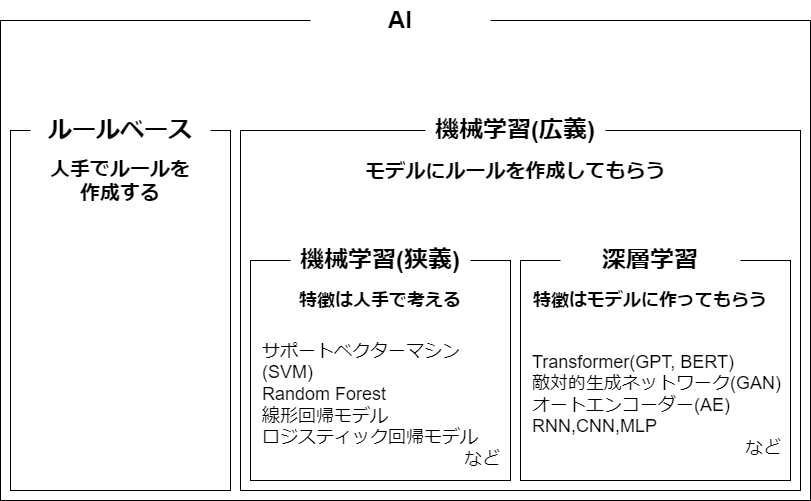
上記の画像は、AIの大まかな分類を表したものです。
昨今は、特に深層学習系のモデルが広く使用されています。
各分類の違いはルールを誰が作るか・特徴を誰が作るかの2点です。
ルールは、モデルが特徴から学習したパターンであり、特徴は、データから特徴抽出を行い取得するパターンのことです。
これらがうまく合致するとモデルの性能が高くなります。
(※特徴抽出:パターンが見えやすいように特徴を変化させること。)
AIモデルの原理
ではここからが本題となる、AIの原理についての内容です。
そもそもAIとはどのようにして予測値を決定し、分類しているのでしょうか?
(※以下説明用に数式が出てきます。ご了承ください。)
タスク設定
今回は線形回帰モデルの分類タスクを例に見ていこうと思います。
タスク設定は以下の通りです。
- モデル
- 線形回帰モデル
- タスク
- みかんとイチゴの2値分類タスク
- 特徴は「赤み」と「丸み」
データセット関連の変数名
図解にすると以下の通りです。

モデルの予測値
線形回帰モデルでの予測値
この式の中の
今回は簡単なモデルであるため、重要度が直接的な特徴の重要性につながります。
また、
-
学習時
予測値\tilde y_{i} y
この作業をデータセット内のデータ数×数回~数十回繰り返す。 -
推論時(学習後に行う、データの分類を確認する作業)
学習時と同様にデータをモデルに入力し、予測値\tilde y_{i}
この\tilde y_{i}
そのため、分類する際には、人が設定した閾値(任意の値)より大きいかどうかで判別を行います。(サンプリング)
まとめ
- AIは「既存データのパターンを学習した数理モデル」
- データのパターンはその特性や種類により様々である。
- AIの学習は、モデル内のパラメータの調整を指す。
- AIはルールを誰が作るか・特徴を誰が作るかで分類される。
- AIの出力値の計算には、モデル内のパラメータが深く関連する。
最後に
今回は直線の境界でしたが、複雑化したモデルでは、複数の境界線や非線形な境界線を駆使して、分類や予測を行っています。
- 機械学習(狭義)
- 線形の多項式の計算方法を変更することで非線形なものにすることが多い。
- 木構造を用いた分類方法も存在する。
- 深層学習
- 線形な層を重ね、層の間に非線形な演算を加えることで非線形な境界を実現していることが多い。
また、生成AIは分類タスクの延長線上にあり、次に出る単語が何かを分類し、確率が高いものを採用するサンプリング手法などにより実現しています。
今回は説明だけでしたが、以降はPythonによる実際の挙動もお見せできたらと思います。

Discussion