挑戦の背景と今回の目的
-
背景
機械学習・AIエンジニアになりたい! -
目的
- 機械学習の一連の流れをハンズオン形式で学ぶ
- とにかく1回提出してみる
今回利用したデータセット
タイタニック事故の乗客データと事故での生死がcsv形式で与えられている。訓練データとテストデータが最初から与えられているため、データを分割する必要はない。
実際に分析
全体の流れを整理する。
-
特徴量作成
- データの読み込みと構造把握
- データの前処理
- EDA
- 新たな特徴量作成・変更
-
モデルの作成
- ハイパーパラメータ(ハイパラ)の調整
- モデルの種類の決定・変更
- 特徴量の追加・変更
-
モデルの学習・評価
-
テストデータの予測・提出
※バリデーションの枠組み作成
バリデーションでハイパラの決定、モデルの評価をする。通常はクロスバリデーションで行うことが多い。
特徴量作成
- csvファイルからデータセットを読み込み
import numpy as np
import pandas as pd
train = pd.read_csv('input/train.csv')
test = pd.read_csv('input/test.csv')
gender_submission = pd.read_csv('input/gender_submission.csv')
train.head()

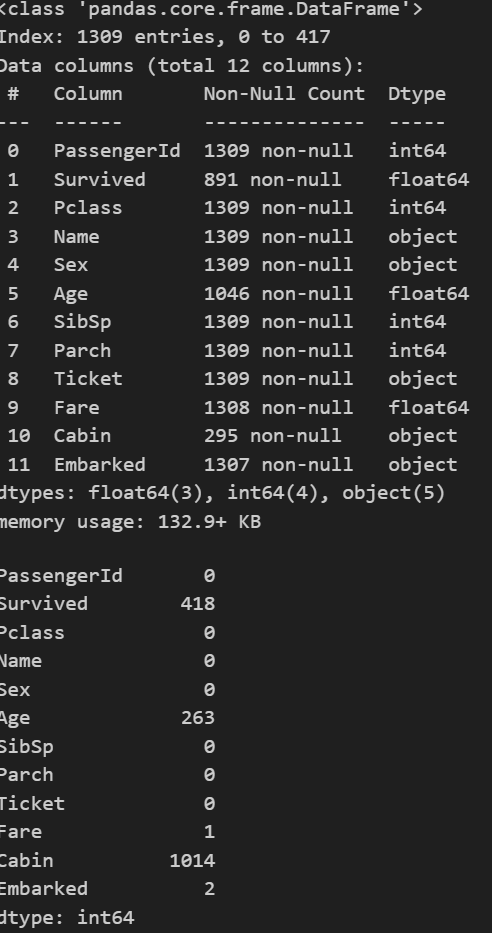
- データ構造の把握
#処理を一括でするためにデータを縦に結合
data = pd.concat([train, test], sort=False)
#構造把握
data.info()
data.describe()
#欠損値の個数
data.isnull().sum()
-
前処理
目的:欠損値処理や数値データでないもの数値データに変換することで、モデルがデータを理解できるようにする。
data['Sex'] = data['Sex'].replace({"male" : 0,"female" : 1}).astype(int)
data['Embarked'] = data['Embarked'].fillna('S')
data['Embarked'] = data['Embarked'].replace({"S" : 0,"Q" : 1, "C" : 2}).astype(int)
data['Age'] = data['Age'].fillna(np.mean(data['Age']))
data["Fare"] = data['Fare'].fillna(np.mean(data['Fare']))
delete_columns =["PassengerId", "Name", "Ticket", "Cabin"]
data = data.drop(delete_columns, axis=1)
print(data.isnull().sum())
data.head()

-
EDA
目的:生存データと各数値データのカラムの関係性を1対1で図示する。これをもとに有効な新たな特徴量を作成したりなど、モデルが生存・死亡を予測する際に役立ちそうな仮説を立てる。
方法は以下のとおりである。-
関数
- arrange_stack_bar(ax)
役割:グラフ(棒グラフなど)のX軸ラベルを30度傾けて見やすくし、Y軸に点線グリッドを表示 - output_bars(df, column, index={})
役割:指定したカラム(column)ごとに、生存者(Survived=1)と非生存者(Survived=0)の分布を4つのグラフで表示
- arrange_stack_bar(ax)
-
詳細な処理の流れ
-
4つのグラフ領域を用意
2行2列のグラフ(合計4つ)を作成
index(ラベル辞書)が空かどうかで処理を分岐indexが空の場合:カラムの値そのまま使う
indexがある場合:カラムの値をindex辞書で日本語などに変換 -
グラフの種類
左上(axes[0, 0]):指定カラムの値の割合を円グラフで表示
左下(axes[1, 0]):生存者・非生存者の人数を棒グラフで表示(数値ラベル付き)
右上(axes[0, 1]):生存者・非生存者の人数を積み上げ棒グラフで表示(合計値ラベル付き)
右下(axes[1, 1]):生存者・非生存者の割合(正規化)を積み上げ棒グラフで表示 -
ラベルやグリッドの調整
X軸ラベルを見やすく傾け、グリッドを追加
-
データラベルの追加
棒グラフや積み上げ棒グラフに合計値や個数を表示
-
グラフを表示
plt.show()で全てのグラフをまとめて表示
-
-
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
# 生存/非生存のラベル辞書
DICT_SURVIVED = {0: "dead", 1: "survived"}
def arrange_stack_bar(ax):
ax.set_xticklabels(labels=ax.get_xticklabels(), rotation=30, horizontalalignment="center")
ax.grid(axis='y', linestyle='dotted')
def output_bars(df, column, index={}):
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(12, 8))
fig.subplots_adjust(wspace=0.5, hspace=0.5)
# Key-Valueラベルなしの場合
if len(index) == 0:
df_vc = df.groupby([column])["Survived"].value_counts(
sort=False).unstack().rename(columns=DICT_SURVIVED)
df[column].value_counts().plot.pie(ax=axes[0, 0], autopct="%1.1f%%")
df.groupby([column])["Survived"].value_counts(
sort=False, normalize=True).unstack().rename(columns=DICT_SURVIVED).plot.bar(ax=axes[1, 1], stacked=True)
# Key-Valueラベルありの場合
else:
df_vc = df.groupby([column])["Survived"].value_counts(
sort=False).unstack().rename(index=index, columns=DICT_SURVIVED)
df[column].value_counts().rename(index).plot.pie(ax=axes[0, 0], autopct="%1.1f%%")
df.groupby([column])["Survived"].value_counts(
sort=False, normalize=True).unstack().rename(index=index, columns=DICT_SURVIVED).plot.bar(ax=axes[1, 1], stacked=True)
df_vc.plot.bar(ax=axes[1, 0])
for rect in axes[1, 0].patches:
height = rect.get_height()
axes[1, 0].annotate('{:.0f}'.format(height),
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom')
df_vc.plot.bar(ax=axes[0, 1], stacked=True)
arrange_stack_bar(axes[0, 1])
arrange_stack_bar(axes[1, 0])
arrange_stack_bar(axes[1, 1])
# データラベル追加
[axes[0, 1].text(i, item.sum(), item.sum(), horizontalalignment='center')
for i, (_, item) in enumerate(df_vc.iterrows())]
plt.show()
- Age
plt.hist(train.loc[train['Survived'] == 0, 'Age'].dropna(), bins=30, alpha=0.5, label='0')
plt.hist(train.loc[train['Survived'] == 1, 'Age'].dropna(), bins=30, alpha=0.5, label='1')
plt.xlabel('Age')
plt.ylabel('count')
plt.legend(title='Survived')
plt.show()

- SibSp
sns.countplot(x='SibSp', hue='Survived', data=train)
plt.legend(loc='upper right', title='Survived')
plt.show()

- Parch
sns.countplot(x='Parch', hue='Survived', data=train)
plt.legend(loc='upper right', title='Survived')
plt.show()

- Fare
plt.hist(train.loc[train['Survived'] == 0, 'Fare'].dropna(),
range=(0, 250), bins=25, alpha=0.5, label='0')
plt.hist(train.loc[train['Survived'] == 1, 'Fare'].dropna(),
range=(0, 250), bins=25, alpha=0.5, label='1')
plt.xlabel('Fare')
plt.ylabel('count')
plt.legend(title='Survived')
plt.xlim(-5, 250)
plt.show()

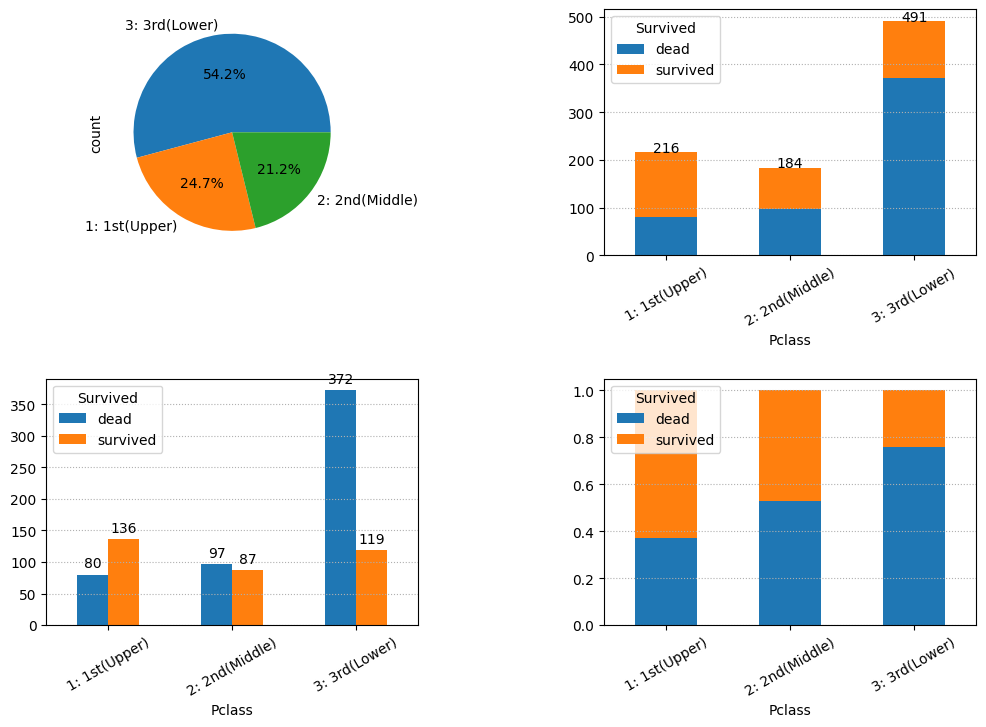
- Pclass
DICT_PCLASS = {1: '1: 1st(Upper)', 2: '2: 2nd(Middle)', 3: '3: 3rd(Lower)'}
output_bars(data, 'Pclass', DICT_PCLASS)
- Sex
output_bars(data, "Sex", {"male": "男性", "female": "女性"})

- Embarked
sns.countplot(x='Embarked', hue='Survived', data=train)
plt.show()

以上より、sibsp、parchなどの乗船時の帯同家族数が生死に関係がありそうである。よって新しい特徴量を以下とする。
-
FaamilySize: FamilySize = sibsp + parch +1
-
Isalone: もし FamilySize(家族の人数)が1であれば、その乗客は一人で乗船しているとみなし、ISalone を1とする。
data['FamilySize'] = data['SibSp'] + data['Parch'] + 1
# Create a new feature 'IsAlone' based on 'FamilySize'
data['IsAlone'] = 0
data.loc[data['FamilySize'] == 1, 'IsAlone'] = 1

モデルの作成
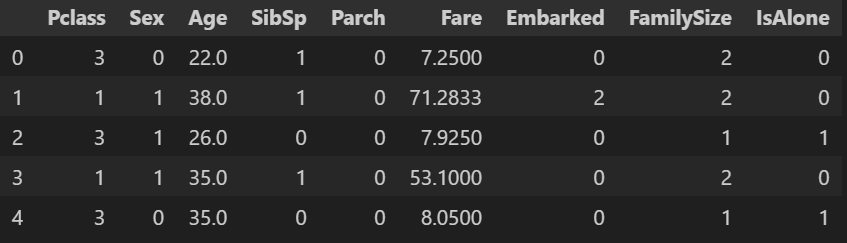
- データの切り離し
#訓練データとテストデータをくっつけていたので切り離し
train = data[:len(train)]
test = data[len(train):]
#目的変数(予測したい対象)の切り離し
y_train = train['Survived']
X_train = train.drop('Survived',axis=1)
X_test = test.drop('Survived',axis=1)
X_train.head()
-
モデルの選定
二値分類でよく使われるモデルは以下のとおりである。- ロジスティック回帰(Logistic Regression)
シンプルで解釈しやすく、2値分類に特化したモデル。特徴量と生存確率の関係が直感的にわかる。 - 決定木(Decision Tree)
特徴量の条件分岐で分類するため、どの特徴が重要か可視化しやすい。前処理も比較的少なくて済む。 - ランダムフォレスト(Random Forest)
複数の決定木を組み合わせて精度を高める。過学習しにくく、特徴量の重要度もわかる。 - 勾配ブースティング(Gradient Boosting, XGBoost, LightGBMなど)
高い精度が出やすく、Kaggleなどのコンペでよく使われる。パラメータ調整でさらに性能向上が可能。 - サポートベクターマシン(SVM)
特徴量が少ない場合や、線形分離が可能な場合に有効。カーネルを使えば非線形にも対応できる。
- ロジスティック回帰(Logistic Regression)
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = \
train_test_split(X_train, y_train, test_size=0.3,
random_state=0, stratify=y_train)
#lightGBMモデルはカテゴリ変数を指定でき、それを考慮した予測を行ってくれる
categorical_features = ['Embarked', 'Pclass', 'Sex']
import lightgbm as lgb
lgb_train = lgb.Dataset(X_train, y_train,
categorical_feature=categorical_features)
lgb_eval = lgb.Dataset(X_valid, y_valid, reference=lgb_train,
categorical_feature=categorical_features)
params = {
'objective': 'binary'
}
gbm_model = lgb.train(
params,
lgb_train,
valid_sets=[lgb_train, lgb_eval],
num_boost_round=1000,
callbacks=[lgb.early_stopping(10)]
)
モデルで予測・モデルの評価
- モデルで予測
y_pred_GBM = gbm_model.predict(X_test, num_iteration=gbm_model.best_iteration)
- 予測結果出力
y_pred_GBM = (y_pred_GBM > 0.5).astype(int)
y_pred_GBM[:10]
予測結果:array([0, 1, 0, 0, 0, 0, 1, 0, 1, 0])
提出スコア
-
提出方法
csvを公式サイトにアップロードすると自動でスコアを計測・記録してくれる。
sub['Survived'] = y_pred_GBM
sub.to_csv('submission_lightgbm.csv', index=False)
sub.head()
-
提出スコア
勾配ブースティング:

TODO
- 特徴量エンジニアリングの手法を学び、今回のタイタニックデータでスコア0.85↑を狙う
- 時系列データ、画像データ、自然言語処理なども学ぶ
- SIGNATEで現在進行形で開催中のデータ分析コンペに参加し、提出をする
参考書籍

Discussion