


やってみること
Microsoft FabricのReal Time Analyticsを使ってみる
今回は、Eventhub(イベント ハブ互換エンドポイント)を使ってみる
構成
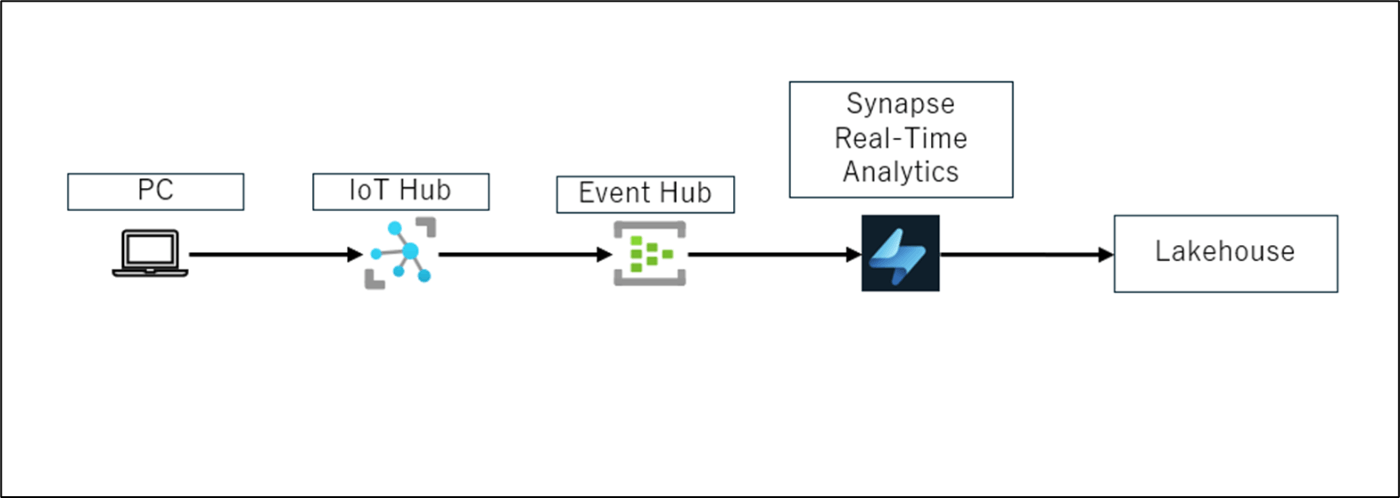
手順
- Microsoft Fabric(https://app.fabric.microsoft.com/home)にアクセス

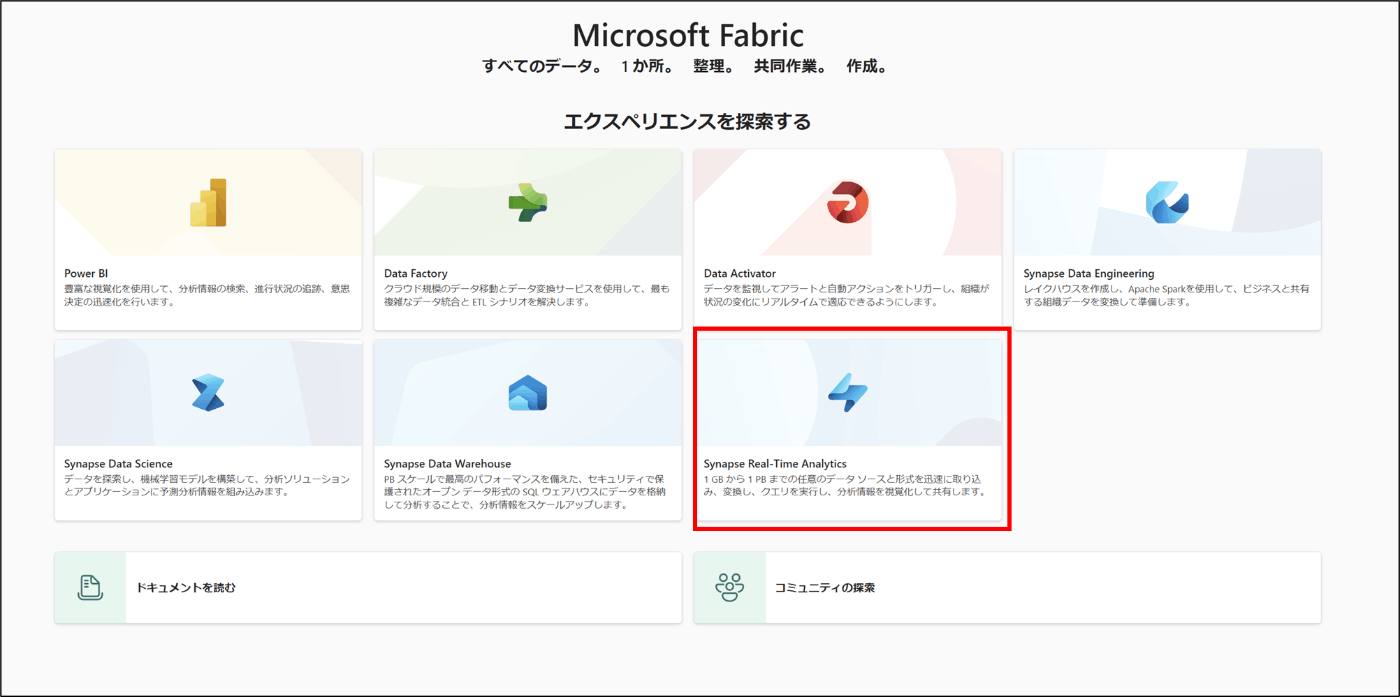
- 「Synapse Real-Time Analytics」をクリック
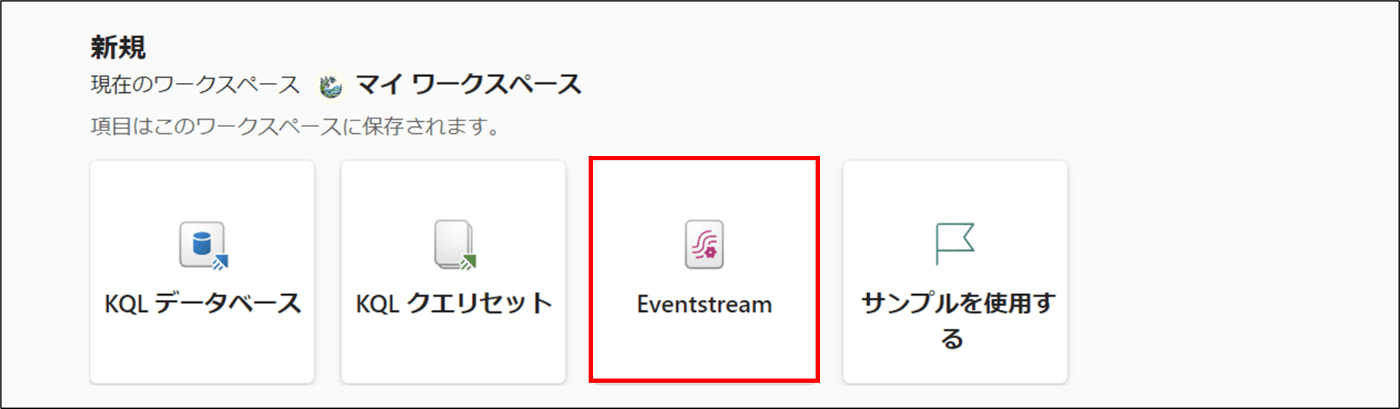
- 「Eventstream」をクリック
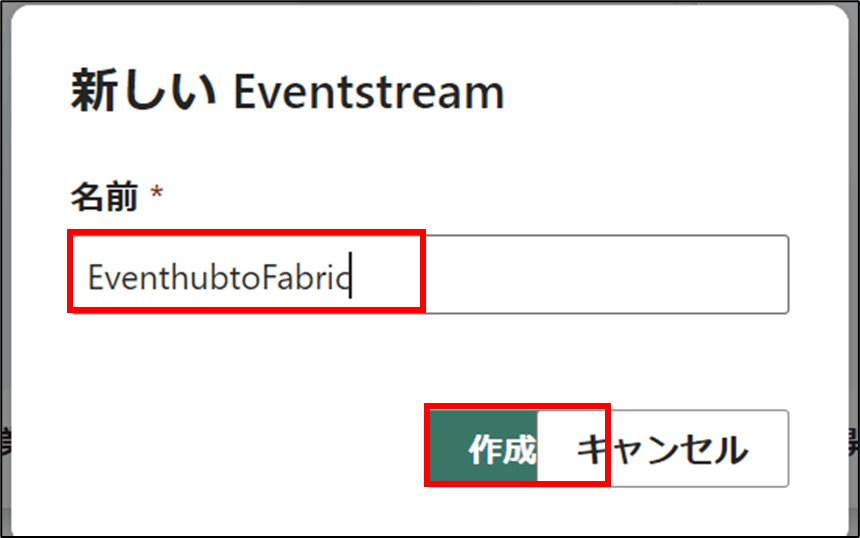
- 名前を入力し、「作成」をクリック
- 開いたことを確認
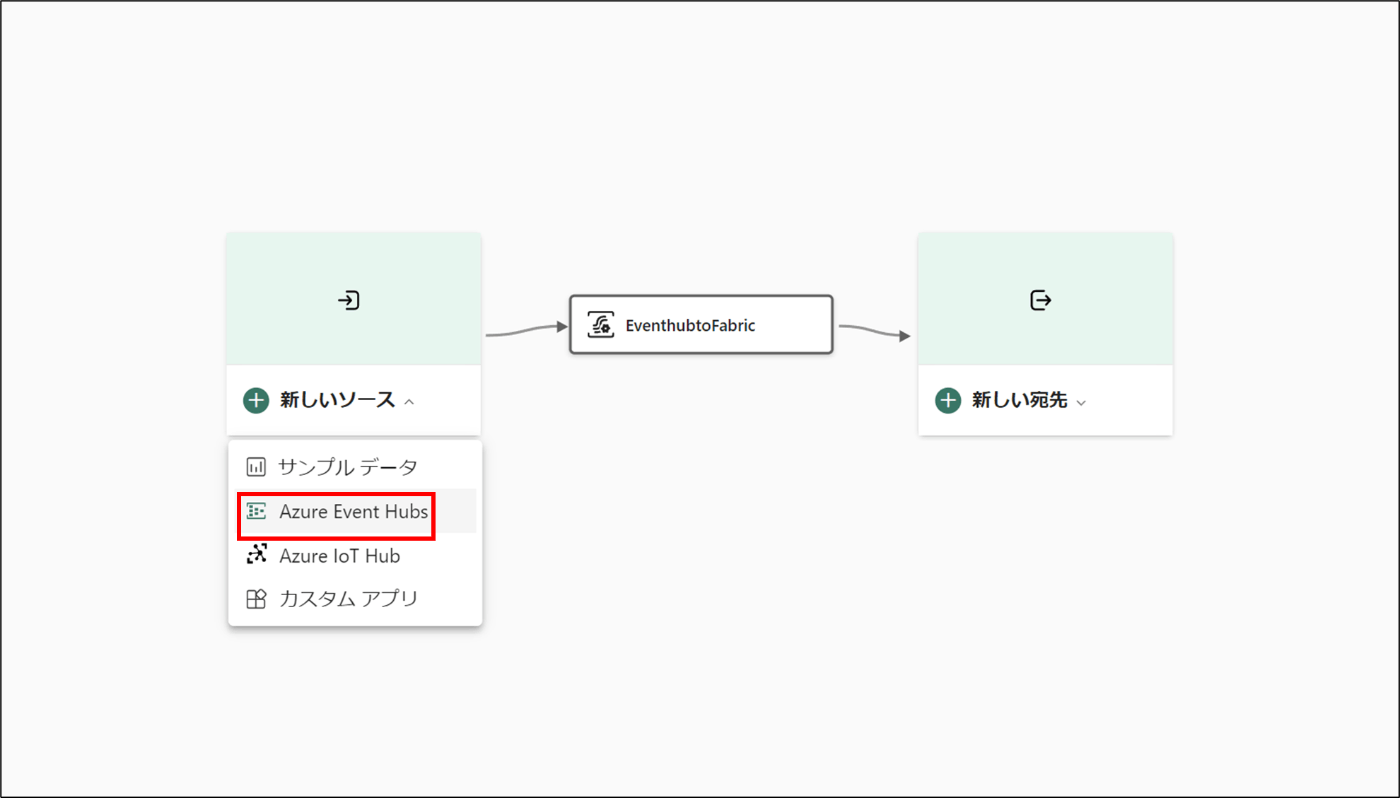
- 「新しいリソース」を選択し、「Azure Event Hubs」をクリック
- 名前を入力し、「Create new」をクリック

- iothubのイベント ハブ互換エンドポイントを取得する
Endpoint=sb://<Event Hub 名前空間>.servicebus.windows.net/;SharedAccessKeyName=iothubowner;SharedAccessKey=<SAS キー>=;EntityPath=<Event Hub 名前>
- 下記のパラメータを入力後、「作成」をクリック
Event Hub namespace:8で取得したEvent Hub 名前空間
Event Hub:8で取得したEvent Hub名前
Connnection,Connection name,Authentication Kindは、自動的に作成されます
Shared Access Key Nameは、iothubownerを入力
shared Access Keyは、下記の手順で取得する
9-1. Azure portalでIoT Hubを開く
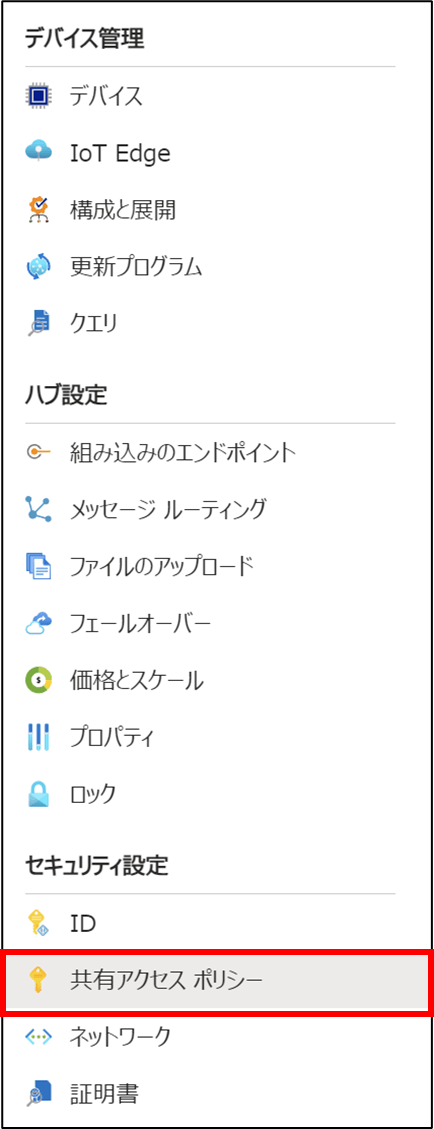
9-2. 共有アクセスポリシーをクリック
9-3. 「iothubowner」をクリック
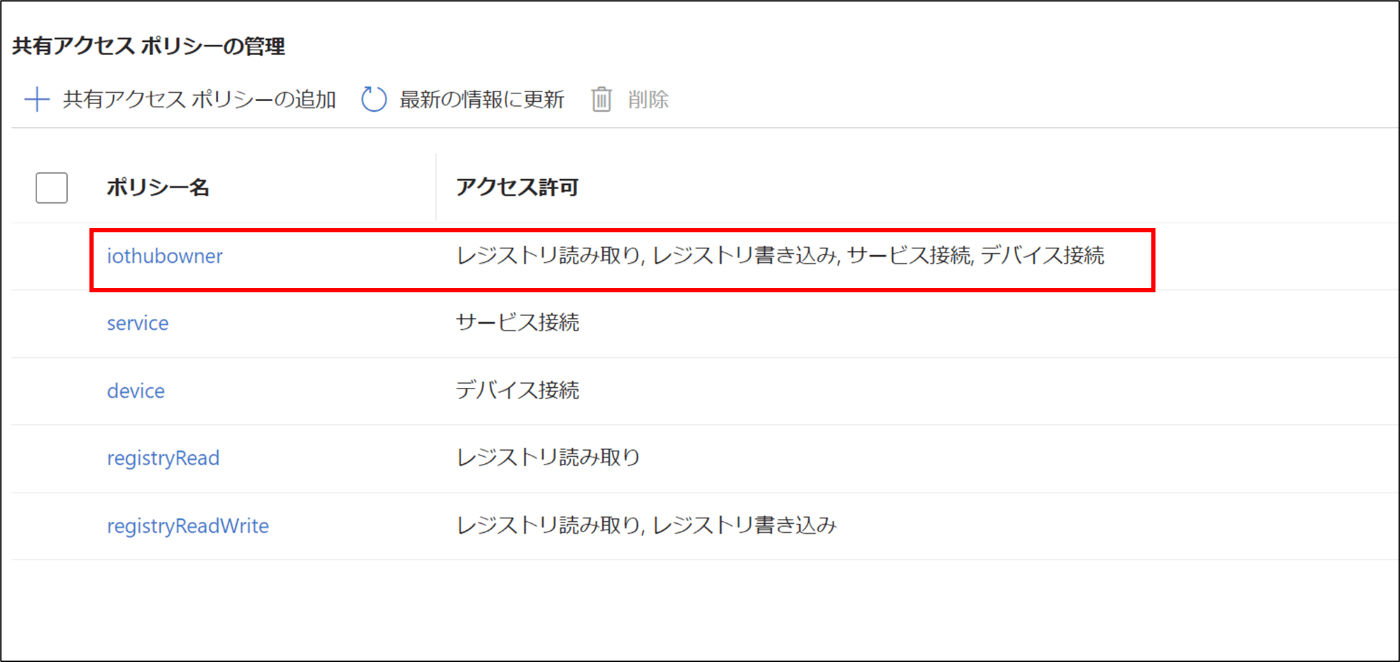
9-4. 「プライマリキー」をコピー
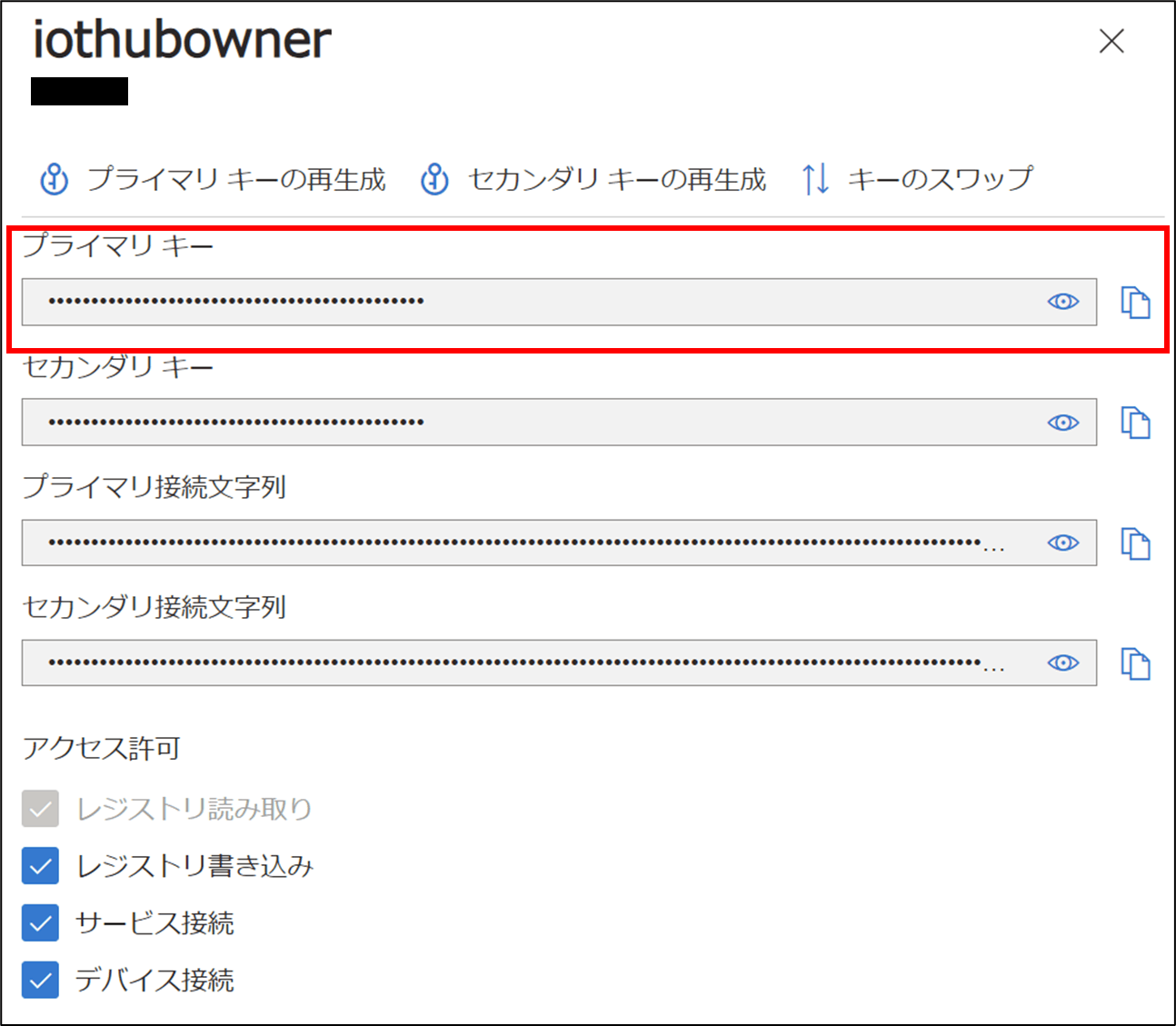
9-5. コピーしたプライマリキーをshared Access Keyに入力

- 「追加」をクリック
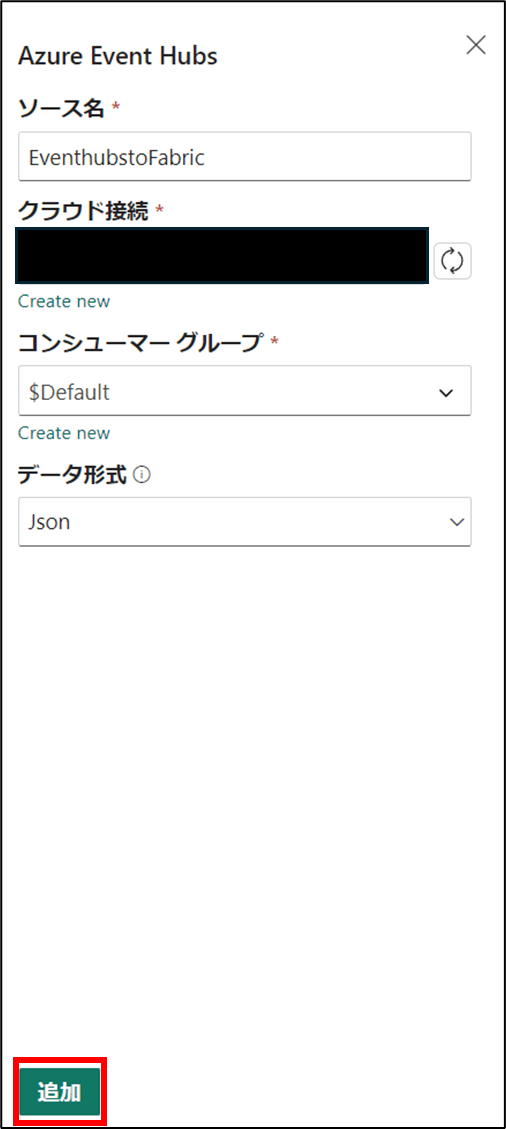
- 作成されたことを確認
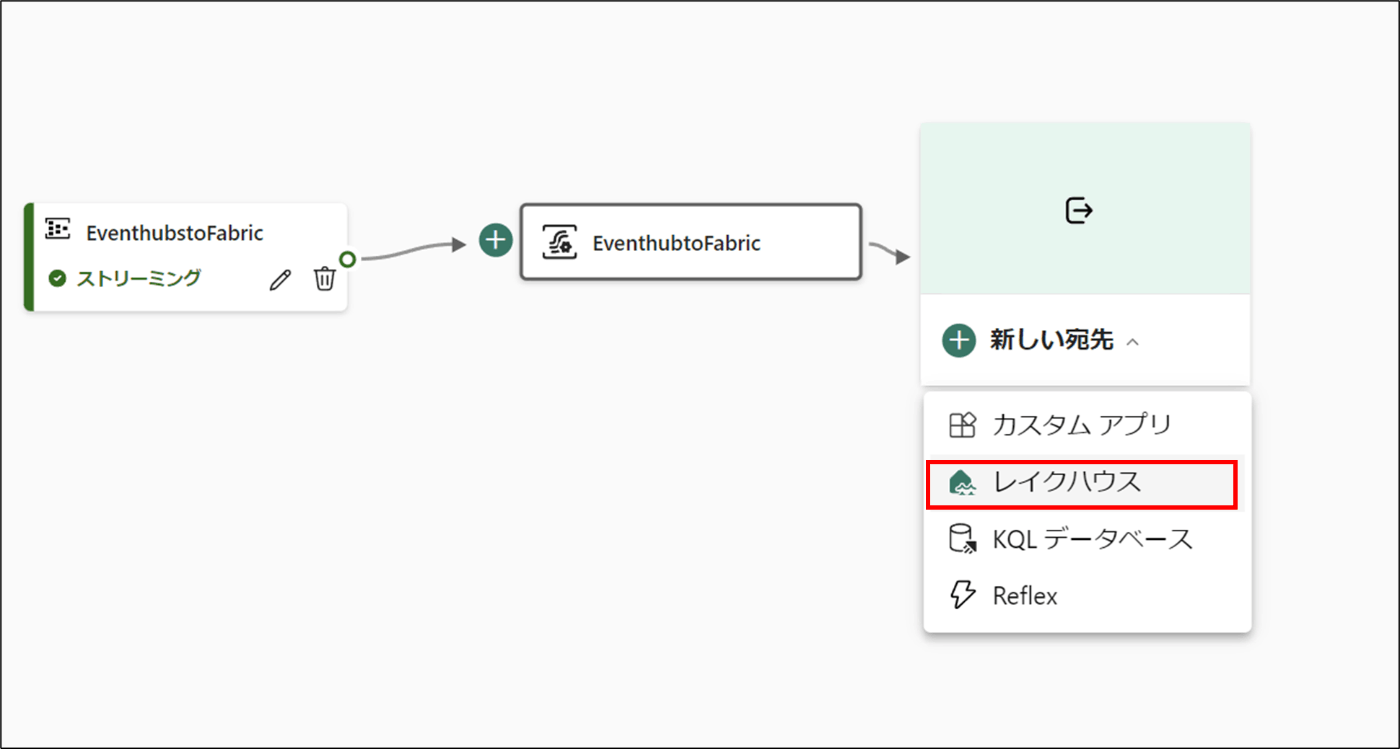
- 「新しい宛先」を選択し、「レイクハウス」をクリック
- 宛先名,ワークスペース,レイクハウスを選択後、「Create new」をクリック
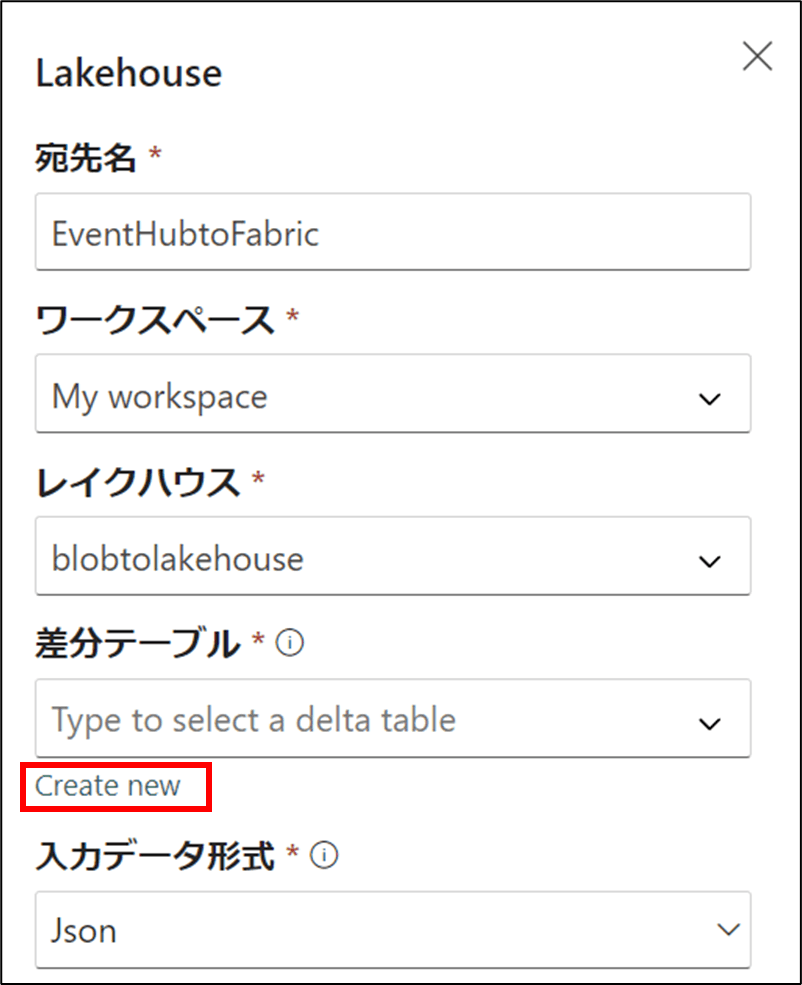
- 名前を入力後、「Done」をクリック
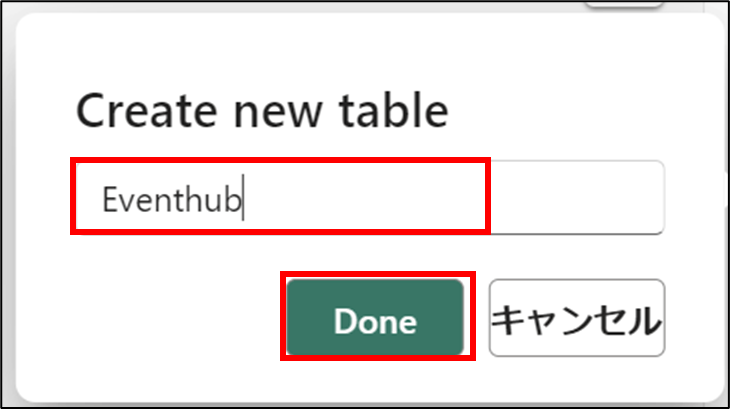
- 「追加」をクリック

- 作成されたことを確認

- 下記のスクリプトをPCで実行する
from azure.iot.device import IoTHubDeviceClient, Message
import random
import time
import json
from datetime import datetime
CONNECTION_STRING = "Your-Device-Connection-String"
# 接続文字列を使用してデバイスクライアントのインスタンスを生成
client = IoTHubDeviceClient.create_from_connection_string(CONNECTION_STRING)
while True:
# 現在の日時を取得
current_time = str(datetime.now())
# ランダムな温度と湿度の値を生成
temperature = 20 + (random.random() * 10)
humidity = 60 + (random.random() * 20)
# データを辞書形式で作成
data = {"temperature": temperature, "humidity": humidity, "time": current_time}
# データをJSON形式の文字列に変換
message = Message(json.dumps(data))
# メッセージを送信
client.send_message(message)
print(f"Message sent: {message}")
# 1秒待機
time.sleep(1)
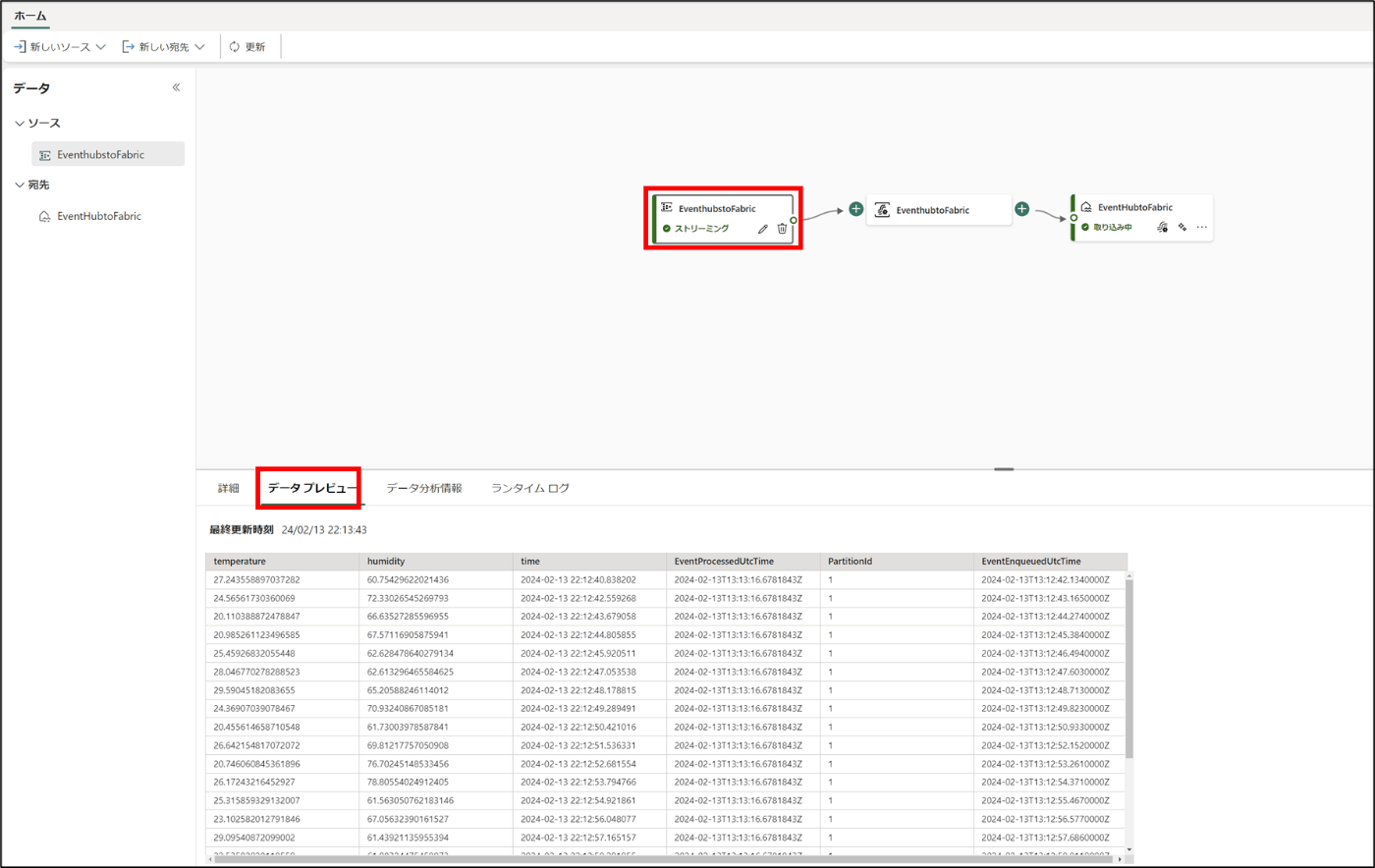
- 「EventhubstoFabric」を選択し、「データプレビュー」をクリック
- データが入ってることを確認
- 「EventhubtoFabric」を選択し、「データ分析」をクリック
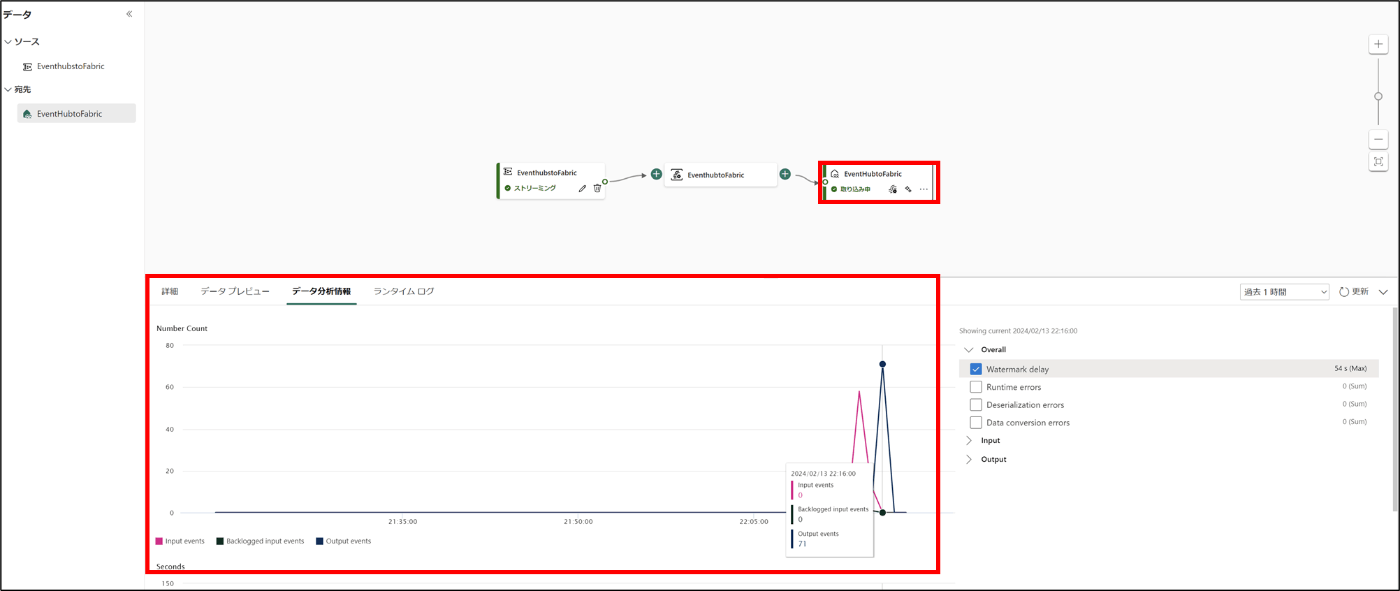
- データが入ってることを確認
まとめ
IotHubのイベント ハブ互換エンドポイントでもReal Time Analyticsは使用可能。
余談
F2で検証しているのですが、Real Time Analyticsを使用するとSparkjobが起動しなくなってしまう。
InvalidHttpRequestToLivy: [TooManyRequestsForCapacity] This spark job can't be run because you have hit a spark compute or API rate limit. To run this spark job, cancel an active Spark job through the Monitoring hub, choose a larger capacity SKU, or try again later. HTTP status code: 430 {Learn more} HTTP status code: 430.

Discussion