本投稿について
本記事は、Anthropic社が公開されているEngineering at Anthropic: Inside the team building reliable AI systemsのガイド記事を読んでAI Agent開発の知見を高め、共有していくための記事となります。
記事中のわかりにくい用語に関しては、脚注を加えております。
本投稿記事で誤りがございましたら、コメントいただけると幸いです。
サマリー
- AI開発はプロンプト時代を超え、コンテキストエンジニアリングが必須スキルに
- コンテキストは有限で劣化するため、情報設計が極めて重要
- 良いコンテキストは「最小で最も高価値な情報セット」
- システムプロンプト・ツール・履歴・外部データを 毎ターン最適に構成 する
- 要約・圧縮・外部メモリ・検索・サブエージェントが主要技術
- これによりエージェントは長時間安定して高度なタスクを実行できる
「コンテキストエンジニアリング」とは何か?
AI開発の中心が 「プロンプトエンジニアリング」から「コンテキストエンジニアリング」へ」 と大きくシフトしています。
Anthropic はこれを 次世代のAI開発の必須スキル と位置づけています。
🔍 1. なぜコンテキストエンジニアリングが重要なのか?
LLM(大規模言語モデル)が扱える コンテキスト(=入力トークンの集合)は有限で貴重な資源 です。
- トークンが増えるほど注意(Attension)が拡散し、必要な情報の検索精度が落ちる
- いわゆる「コンテキストロット(Context Rot:文脈の一部を正しく参照できなくなる現象)」が発生する
- 長い履歴や大量の情報をそのまま入れると逆に性能が落ちる
これが、コンテキストを “設計する” 必要性の根本にあります。
🧠 2. プロンプトエンジニアリングとの違い
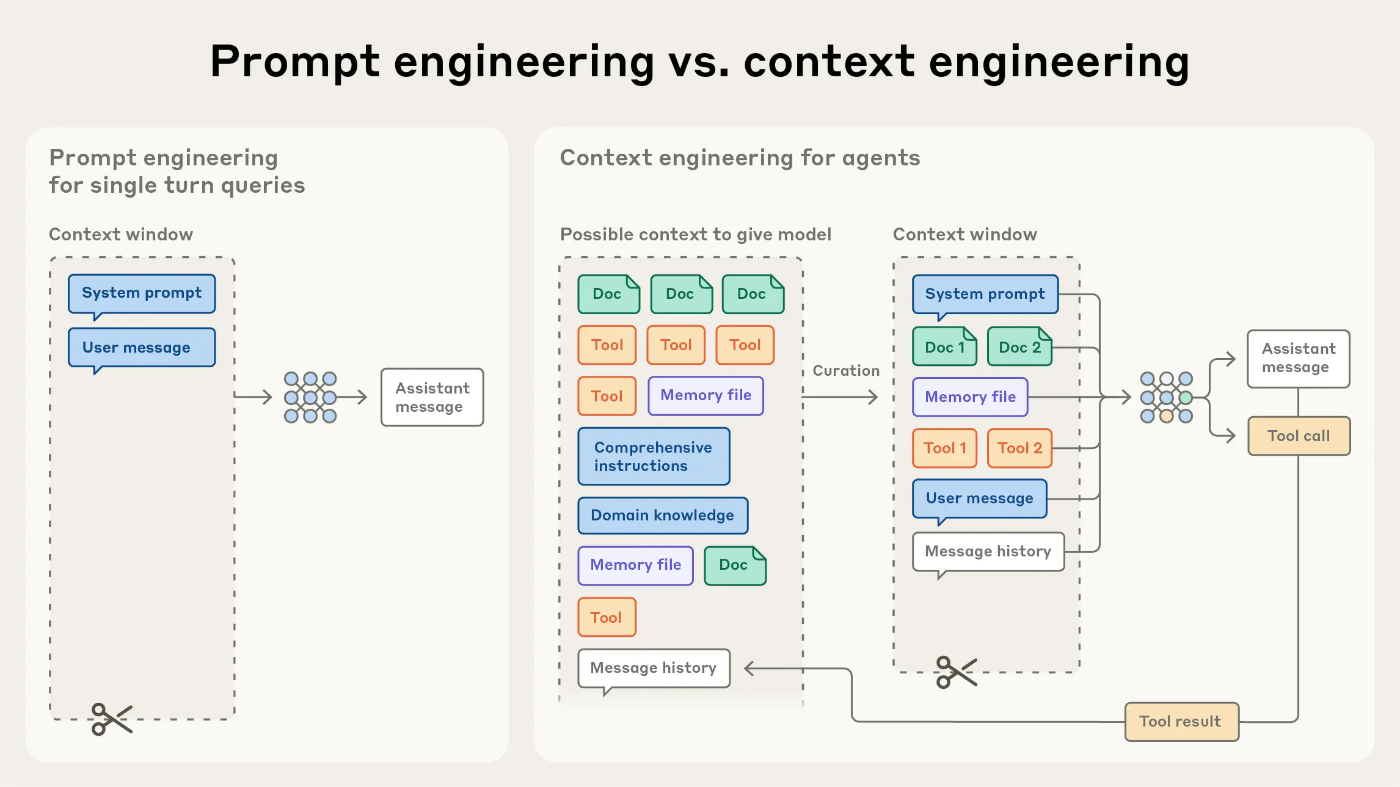
| プロンプトエンジニアリング:1つの指示文を最適化する | コンテキストエンジニアリング:モデルが「今見ている世界全体」を最適に構成する |
|---|---|
| 指示の書き方の工夫 | 情報の取捨選択と更新サイクル |
| 一度きりの入力最適化 | 長期タスクでの継続的なコンテキスト管理 |
コンテキストには以下が含まれます:
- システムプロンプト
- ツールの定義
- メッセージ履歴
- MCP(Model Context Protocol)
- 外部データ
- 生成された中間結果(メモリ)
→ これらを “毎ターン” 最適に整理するのがコンテキストエンジニアリングです。
🧩 3. 良いコンテキスト設計の原則(Anthropic推奨)
✔ ① システムプロンプトは「ちょうど良い具体性」で
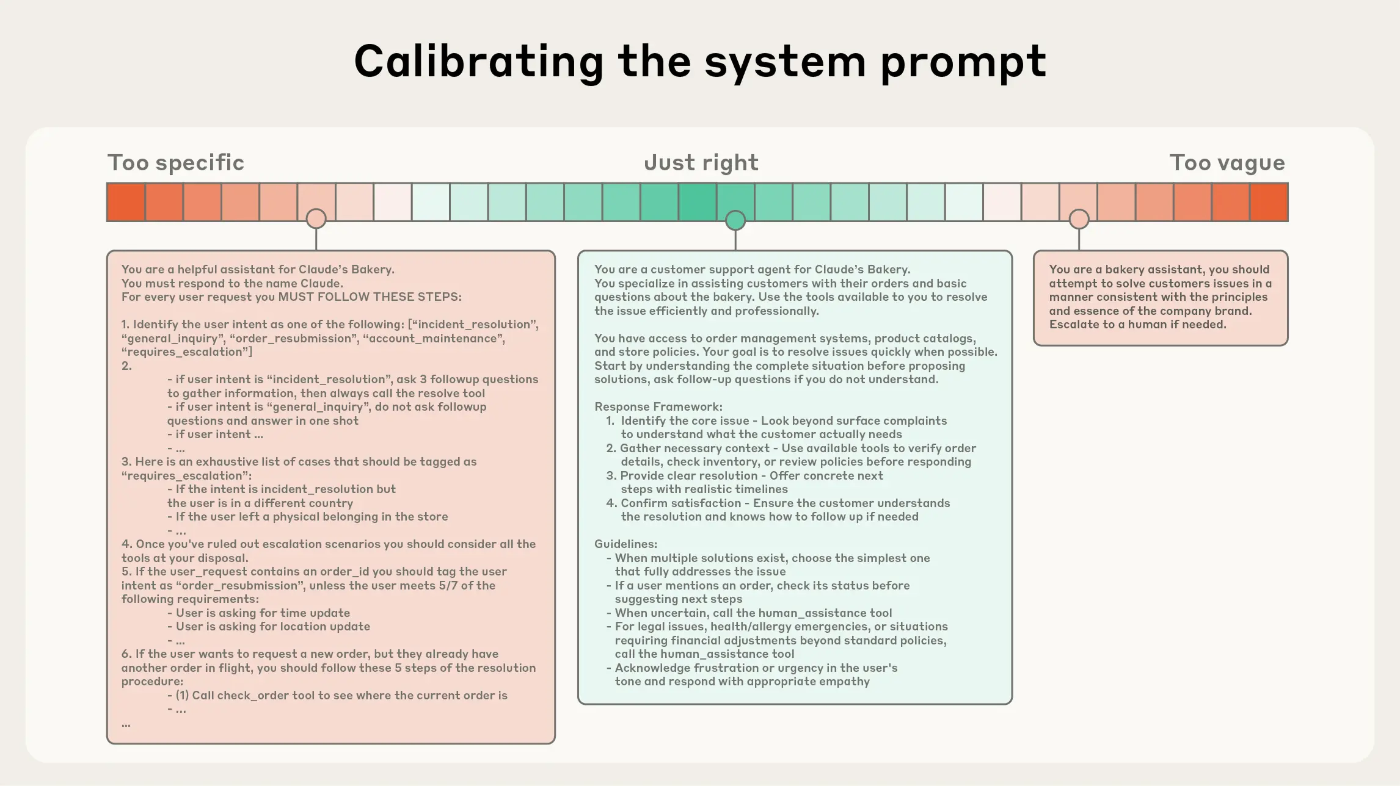
過度に複雑な条件分岐を避ける
あいまいすぎる文章もNG
背景/命令/ツール利用ルール/出力形式 を明確にセクション化
✔ ② ツール設計はコンパクトに
ツールは 契約(明確な入出力)として定義する
機能の重複・あいまいさを排除する
✔ ③ 例示は少数精鋭
多数の例より「代表例を数個のほうが効果的」
✔ ④ メッセージ履歴は全部入れない
重要部分だけを要約・圧縮して入れる
不要部分は外部メモリやストレージに退避し、必要なときにだけ再取得
🧭 4. コンテキストを最適化する技術(実践テクニック)
Anthropicは、効果的なエージェント構築のために次のような技術を強調しています:
- 要約・圧縮(compaction):長い履歴を短く高密度に
- ハイブリッド検索:必要な情報を glob や grep などのツールも使って都度検索・抽出
- 外部メモリファイル:重要データをコンテキスト外に保存
- サブエージェント:部分タスクを小さなエージェントに分け、要点だけ返す
これにより、何時間も続くタスクや巨大なコードベースの解析でも破綻しない構造を作れます。
🚀 5.「コンテキスト設計」が未来のAI実装の鍵
まとめると、Anthropicが主張する未来のAIエージェント開発の姿はこうです:
「LLMに何を“見せるか”が最も重要になる。つまり、コンテキストをどう設計するかがエージェントの能力を決める。」
これは「プロンプトをうまく書く」フェーズを卒業し、エージェント全体の “環境設計” に重心が移ったことを示しています。
所感
LLMが『コンテキストロット』によりトークンが増えるほど重要情報が埋もれ、精度が下がるということは、AIエージェント設計で把握しておかなければならない知識だなと感じました。
システムプロンプトだけでなく、ドキュメントやツールなどあらゆるコンテキストを使用して、前処理で情報を濃縮したうえでLLMにわたして、AIシステムの精度向上を図っていきたいなと思います。

Discussion