やりたいこと
自社の1つのグループ内でAzure Databricksが触れる環境を作って、機能検証したい。
背景
DatabricksとMicrosoft Fabricってデータレイクハウスという思想をFabricが受け継いでいるので、リアルタイムなデータ処理くらいしかDatabricksの優位性がないかと個人的に思っていたが、
DatabricksはAIで分析機能を強化する方針っぽいし、何よりクラシックだと思うので応用(Fabric)の考え方や機能はDatabricksを学ぶことで理解が深まる気がする。
やること
Azure Databricksのリソースを作成し、ノートブックで緯度経度から渋谷の避難所で近いところを検索してみる。
SHIBUYA OPEN DATAというデータがあって、職員さんがADEの場所とか頑張って更新しているみたいなので、活用したいと個人的に思っています。
Azureでの環境構築
まずはリソース作成
リージョンは下記とあるので、全部使えそうな西日本にしてみる
価格レベルをStandardかPremiumか選ぶ
料金
多分、検証はAll-Purpose Computeを使うから、Standardで良いかなと。。
実務的には値段的にStandardでJobs ComputeでNotebookを自動実行かなーと思うのですが、
Premiumに「JDBC/ODBC エンドポイント認証」と記載があり、これないとDB接続できない・・?と微妙な気持ちになりましたが、そんなことないよなと思い、いつか試そうかと。
ノートブックで渋谷区の避難情報を取得して、緯度経度から一番近い避難所を検索
ノートブックを実行する準備
まずはAzure Portalからワークスペースの起動

ワークスペースに自分のディレクトリがあるので、そこでノートブックを作成

VMを選択する

90円/時間を選択してみる

作成したクラスターを選択

※Databricksアシスタントという機能があり、GitHub CopilotやGoogle ColabのColab AIみたいなやつがあり、嬉しいのですが、使っているとすぐ4Kのリミットに引っかかって、そこだけリフレッシュする必要があります。
Shibuya Open Dataからデータの取得
下記のコードは大体Databricksアシスタントに作ってもらいました。
import os
import requests
import shutil
# CSVファイルのURL
## 有効期限があるので、下記のCSVダウンロードのリンクをコピー
## https://city-shibuya-data.opendata.arcgis.com/datasets/95b3c58f32524641a5998fe41992467e_0/explore?location=35.666227%2C139.692054%2C14.52
## 本当は、下記からURLでjsonを取るのが正解っぽい
## https://services3.arcgis.com/UtdeFTavkHfI94t2/arcgis/rest/services/131130_evacuation_space/FeatureServer/0/query?outFields=*&where=1%3D1
url = "https://stg-arcgisazurecdataprod3.az.arcgis.com/exportfiles-85523-398/131130_evacuation_space_157492892331025488.csv?sv=2018-03-28&sr=b&sig=PRLG1k7ixMico%2FPAqFLQzY1rDr5zv0mqSDvX5uHtADE%3D&se=2024-03-25T08%3A20%3A49Z&sp=r"
# ローカルの一時フォルダパス
local_folder_path = "/tmp/samples/shibuya"
# ローカルの一時フォルダを作成
os.makedirs(local_folder_path, exist_ok=True)
# ローカルの一時ファイルパス
local_file_path = os.path.join(local_folder_path, "hinan_place.csv")
# HTTPリクエストでCSVファイルをダウンロード
response = requests.get(url, stream=True)
# レスポンスの内容を一時ファイルに保存
with open(local_file_path, 'wb') as file:
response.raw.decode_content = True
shutil.copyfileobj(response.raw, file)
sdf = (spark.read
.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load("file:///tmp/samples/shibuya/hinan_place.csv")
)
sdf.show()
## pandasの方が慣れているので・・
df = sdf.toPandas()
df.head()
Databricksアシスタントにやりたいことを聞いてみる

import numpy as np
# 引数の緯度経度
target_lat = 35.6895
target_lon = 139.6917
# 緯度経度の差を計算
df["lat_diff"] = np.abs(df["緯度"] - target_lat)
df["lon_diff"] = np.abs(df["経度"] - target_lon)
# 最小の差を持つ避難所を抽出
nearest_shelter = df.loc[df["lat_diff"].idxmin()]
# 最も近い避難所を出力
print("Nearest Shelter:")
print(f"名称: {nearest_shelter['名称']}")
print(f"緯度: {nearest_shelter['緯度']}")
print(f"経度: {nearest_shelter['経度']}")
Nearest Shelter:
名称: 新宿中央公園・高層ビル群一帯
緯度: 35.689549
経度: 139.692214
なんで新宿?と思って、作られた緯度経度を見たら都庁でした。
で、一応、新宿中央公園・高層ビル群一帯のデータもあったし、処理もぱっと見、緯度経度の差が小さいところだから良さそうかなーと。
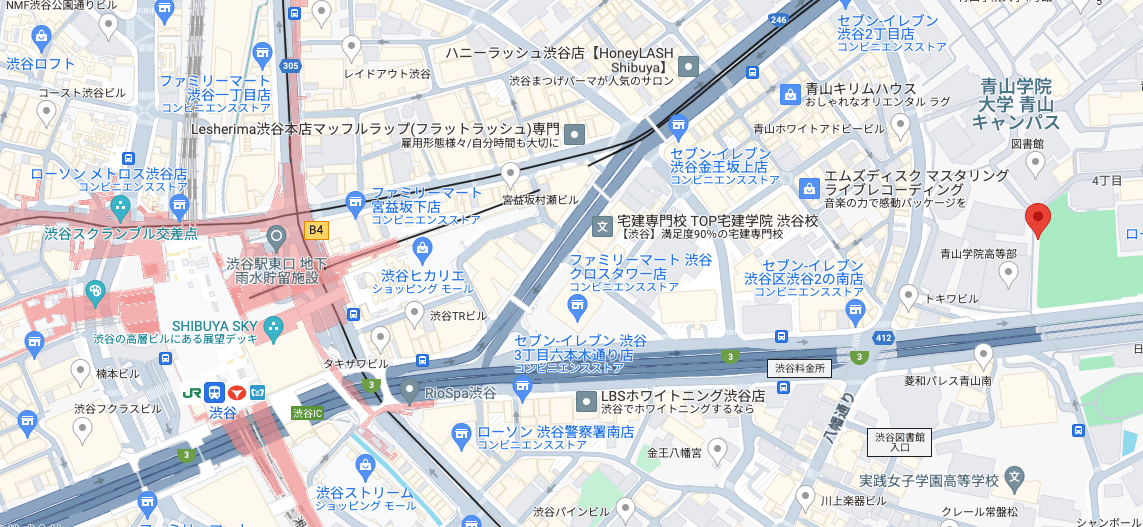
渋谷駅っぽい緯度経度で実行すると
target_lat, target_lon = 35.6598003, 139.7023894
下記で、まーまー近い気がしました。ただ、地図で出さないとよくわからないですね。
Nearest Shelter:
名称: 青山学院・実践女子学園一帯
緯度: 35.659357
経度: 139.710198
まとめ
Azure Databricksでのリソース作成からノートブックの実行までやりました。
Databricksの検証して、めちゃくちゃこのシチュエーションで使える!!を見つけていきたいと。

Discussion