

Apache Sparkとは
Apache Sparkは、大規模なデータ処理と分析のためのオープンソースの並列処理フレームワークです。 Sparkは、"ビッグ データ" 処理のシナリオで人気が高まっており、Azure HDInsight、Azure Databricks、Azure Synapse Analytics、Microsoft Fabricなど、複数のプラットフォーム実装で利用できます。
Sparkでは、Java、Scala (Java ベースのスクリプト言語)、Spark R、Spark SQL、PySpark (Python の Spark 固有のバリアント) など、さまざまな言語で記述されたコードを実行できます。 ほとんどのデータ エンジニアリングと分析ワークロードは、PySpark と Spark SQL の組み合わせを使用して実現されます。
Sparkを使用する上で知っておいた方がいい用語
- ノード ファミリ: Spark クラスター ノードに使用される仮想マシンの種類。 ほとんどの場合、メモリ最適化ノードで最適なパフォーマンスが提供されます。
- ランタイム バージョン: クラスターで実行される Spark (および依存サブコンポーネント) のバージョン。
- Spark プロパティ: クラスターで有効またはオーバーライドするSpark固有の設定。 プロパティのリストはApache Sparkのドキュメントで確認できます。
Spark コードを実行するには?
Microsoft FabricでSpark コードを編集して実行するには、"Notebook"を使用するか、"Sparkジョブ"を定義します。
Notebook
Sparkを使用してデータを対話的に探索および分析したい場合は、Notebookを使用します。 Notebookを使うと、複数の言語で記述されたテキスト、画像、コードを組み合わせることで、他のユーザーとの共有および共同作業が可能な対話型の項目を作成できます。
Notebookは 1 つまたは複数の "セル" で構成され、各セルにはマークダウン形式のコンテンツまたは実行可能コードを含めることができます。 Notebook内で対話形式でコードを実行し、その結果をすぐに確認できます。
Spark ジョブ定義
Sparkを使用して、データを自動プロセスの一部として取り込んで変換する場合は、オンデマンドでまたはスケジュールに基づいてスクリプトを実行する Spark ジョブを定義できます。Sparkジョブを構成するには、ワークスペース内にSparkジョブ定義を作成し、実行するスクリプトを指定します。 また、参照ファイル (スクリプトで使用される関数の定義を含むPython コード ファイルなど) や、スクリプトで処理されるデータを含む特定のレイクハウスへの参照を指定することもできます。
- スキーマの推論。Pythonの書き方(参考例)
%%pyspark
df = spark.read.load('CSVファイル名',
format='csv',
header=True
)
display(df.limit(10))
先頭の"%%pyspark"行は"マジック"と呼ばれ、このセルで使用される言語がPySparkであることをSparkに伝えます。 ノートブック インターフェイスのツール バーで既定として使用する言語を選択し、マジックを使用して特定のセルの選択をオーバーライドできます。
- Scalaの書き方(参考例)
%%spark
val df = spark.read.format("csv").option("header", "true").load("CSVファイル名")
display(df.limit(10))
マジック"%%spark"はScalaを指定するために使用されます。
Apache Spark を使用してデータを分析する
ワークスペースの作成
※ワークスペースを作成している場合はスキップ。
-
Microsoft Fabricに入る。
https://app.fabric.microsoft.com/home -
[Synapse Data Engineering]をクリックする。

-
左側のメニューバーで、[ワークスペース] をクリックする。

-
[新しいワークスペース]をクリックする。

-
名前を入力し、連絡先一覧を割り当てる。連絡先は基本的には自分のアカウントを割り当てることになると思います。(説明、ドメインはなくても大丈夫です)

-
ライセンスモードを選択する。(今回はPower BI Proを使うことはないので「ファブリック容量」を選択しました。将来的にPower BIの記事を公開予定です)

-
「規定のストレージ形式」を選択する。「大きなセマンティック モデルのストレージ形式」はPower BI Proで使用されることが多いので、今回は 「小さなセマンティック モデルのストレージ形式」を選択します。

-
キャパシティを選択する。(2024年2月現在だと"East US"しか選べないです)

-
[適用]をクリックする。(テンプレートアプリを使用することはないので、スキップで大丈夫です)

レイクハウスの作成
※レイクハウスを作成している場合はスキップ。
-
Microsoft Fabricに入る。
https://app.fabric.microsoft.com/home -
"Synapse Data Engineering"をクリックする。
-
「作成」をクリックする。
-
「レイクハウス」をクリックする。
-
「名前」を入力し、「作成」をクリックする。
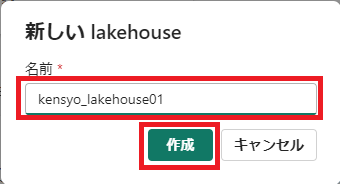
-
レイクハウスが作成されることを確認する。作成には15秒ほどかかります。
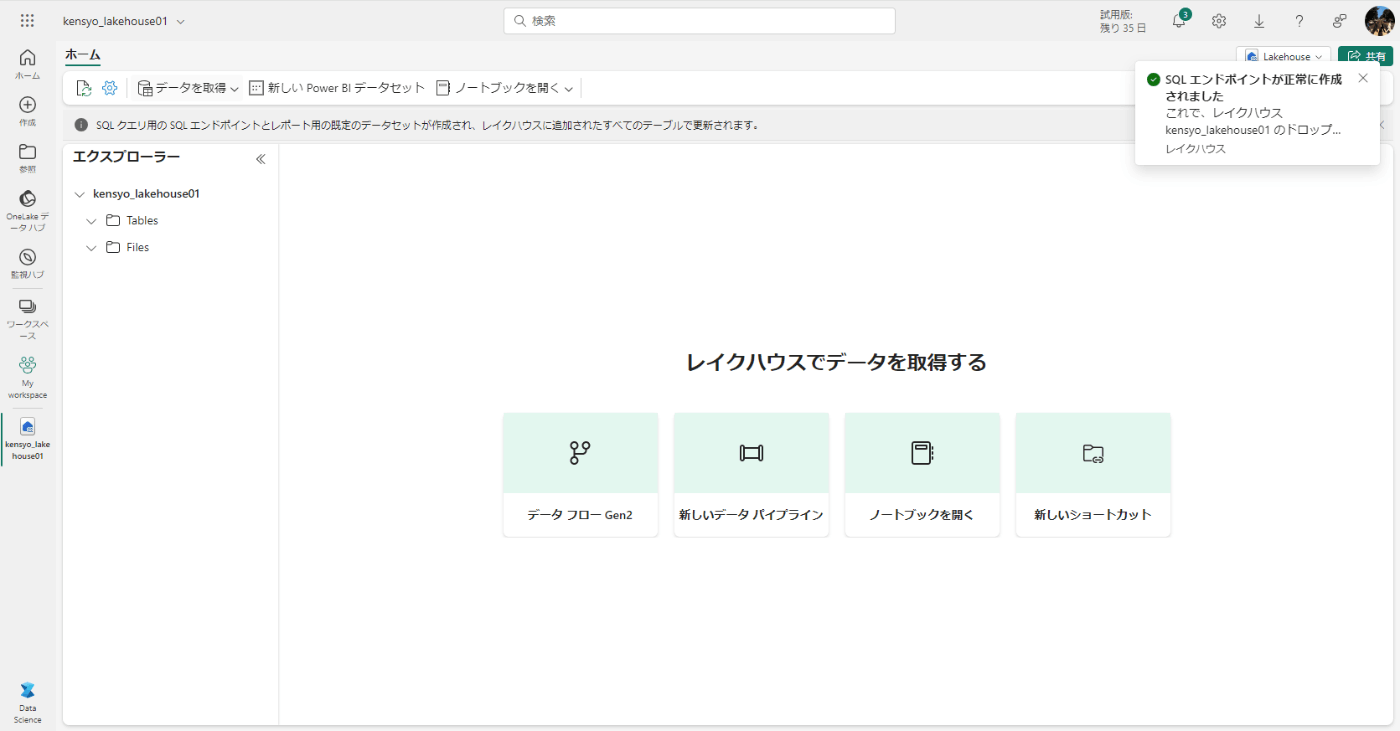
ファイルアップロード
-
新しいデータ フォルダーの [...] メニューで、 [アップロード] と [フォルダのアップロード] を選択する。(今回は複数ファイルを取り扱うので、フォルダにしました。今回は2017年から2019年までの東京都のガン罹患者のデータを引用します。ファイルが1つしかない場合はファイルで大丈夫です)
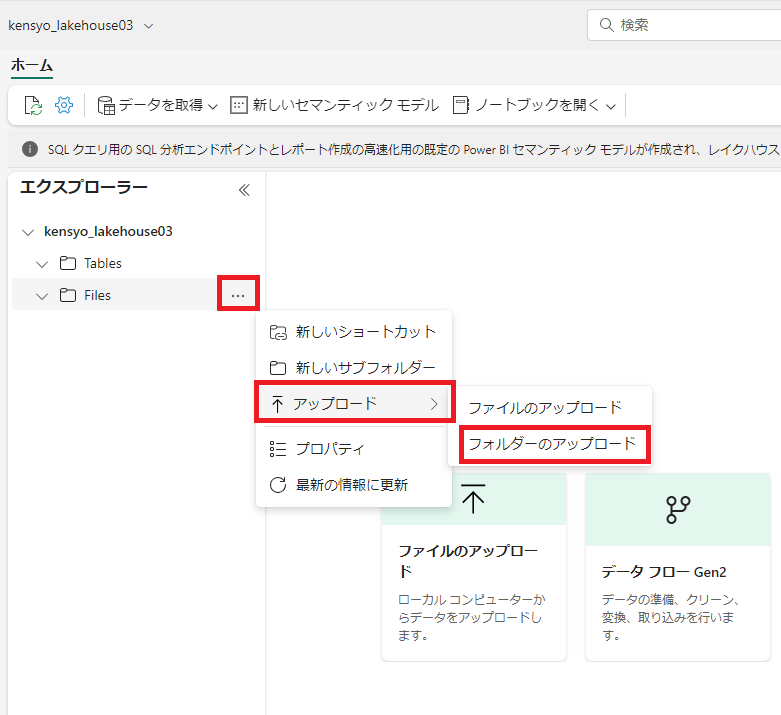
-
[Files/]の入力欄の箇所をクリックする。

-
対象のフォルダ(ファイル)を選択し、[アップロード]をクリックする。

-
Google Chrome等を使用していると、「アップロードしますか?」と聞かれることがあるので、[アップロード]をクリックする。(表示されなければ、スキップで大丈夫です)

-
[アップロード]をクリックする。

-
アップロードされたことを確認する。

ノートブックを作成
Apache Spark でデータを操作するには、”ノートブック” を作成する必要があるので、作成します。また、ノートブックはVSCodeで編集することもできます。
-
[ホーム] ページの [ノートブックを開く] メニューで、 [新しいノートブック] を選択します。

-
画面が切り替わることを確認する。

-
ノートブックのタイトルを用意しましょう。私は下記の記載をしました。
# Searching for the number of cancer cases in Tokyo
Use the code in this notebook to search for the number of cancer cases in Tokyo .

-
右上の動的ツール バーの [M↓] ボタンをクリックする。

-
表示が変わります。これで、後程説明するデータフレームにデータを読み込むコードを実行する準備ができました。Spark のデータフレームは Python の Pandas データフレームに似ており、行と列のデータを操作するための共通の構造が提供されます。

データフレームにデータを読み込む
-
[レイクハウス]をクリックする。

-
[ファイル] をクリックし、orders フォルダーを選んで、ノートブック エディターの横に CSV ファイルの一覧が表示されるようにします。

-
CSVファイルの […] メニューで、 [データの読み込み] > [Spark] を選びます。


-
次のコードを含む新しいコード セルがノートブックに追加されます。(これは自動的に作成されるので、毎回表示は変わるはずです)

df = spark.read.format("csv").option("header","true").load("CSVファイル名")
# df now is a Spark DataFrame containing CSV data from "CSVファイル名".
display(df)
-
セルの左側にある ▷ [セルの実行] ボタンを使って実行する。(ここは処理に時間がかかります。今回は3分弱かかりました。)

-
テーブルが表示されることを確認する。

テーブルと SQL を操作する
-
メニューバーの[編集]をクリックする。

-
[+ コード セルの追加]をクリックする。

※セルの出力の左側にマウスを移動すると表示される [+ コード] をクリックすることで、セルを追加することができます。

-
セル内に下記を入力する。
from pyspark.sql import SparkSession
# SparkSessionの初期化(この例では既に "spark" と名付けられていることを想定)
spark = SparkSession.builder.appName("MyApp").getOrCreate()
# データソースからDataFrameを作成する
# たとえばCSVファイルからデータを読み込む場合は以下のようにします
df = spark.read.csv("CSVファイル名(フォルダ構成で記載)", header=True, inferSchema=True)
# DataFrameをデルタ形式で保存し、テーブルとして登録する
df.write.format("delta").saveAsTable("Tokyo_cancer_incidences")
# テーブルの説明を取得する
spark.sql("DESCRIBE EXTENDED Tokyo_cancer_incidences").show(truncate=False)

-
セルの左側にある ▷ [セルの実行] ボタンを使って実行する。(ここも30秒ほどかかります)

-
簡単なテーブルが表示されることを確認する。

-
テーブルフォルダーの […] メニューの[最新の情報に更新] をクリックする。

-
作成したテーブルが表示されることを確認する。

-
テーブルの […] メニューで、 [データの読み込み] > [Spark] をクリックする。

-
新しいコード セルがノートブックに追加される。

-
セルの左側にある ▷ [セルの実行] ボタンを使って実行する。(ここは3分半ほどほどかかりました。)

-
テーブルが表示されることを確認する。Spark SQL ライブラリを使って、テーブルに対する SQLクエリがPySparkコードに埋め込まれ、クエリの結果がデータフレームに読み込まれます。

Spark を使用してデータを視覚化する
-
メニューバーの[編集]をクリックする。
-
[+ コード セルの追加]をクリックする。
※セルの出力の左側にマウスを移動すると表示される [+ コード] をクリックすることで、セルを追加することができます。
-
下記のコードを入力する。
%%sql
SELECT * FROM "テーブル名"

-
セルの左側にある ▷ [セルの実行] ボタンを使って実行する。

-
テーブルが表示されることを確認する。

-
[Chart]をクリックする。

-
グラフが表示されることを確認する。

-
[グラフのカスタマイズ]をクリックする。

-
[Values]だけ変更して、[Apply]をクリックする。(今回は「0_4歳」から「70_74歳」に変更)
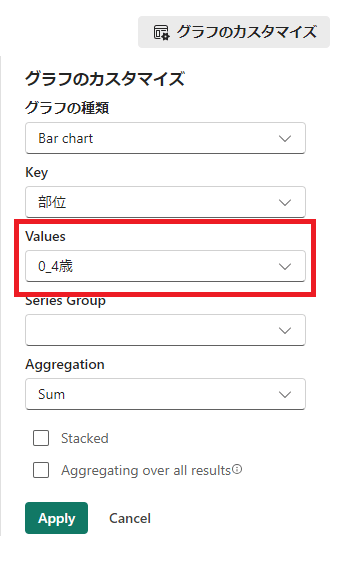


-
表示が変わることを確認する。

Apache Sparkを触ってみた感想
PythonやSQLの初心者には難しく感じるところはあると感じました。
データに関わる職種(データエンジニア、データサイエンティスト、データアナリストなど)の方は頭に入れた方が良い知見だとは思いました!
今後やりたいこと
- データフレームオブジェクトに含まれるさまざまな関数を使って、それに含まれるデータのフィルター処理、グループ化、その他の操作
- Sparkを使用してデータファイルを変換
- データをグラフとして視覚化するmatplotlib Python ライブラリ、seaborn ライブラリの使用

Discussion