

執筆日
2024/1/28
やること
昨年の11月にAzure Document intelligenceのv4.0が発表されました。
query field extractionという機能が追加されたので、そちらの検証を行おうかなと。
Azure Document intelligenceとは?
query field extraction(クエリ フィールドの抽出)とは?
Docsより引用..
特定のfieldを抽出するために、事前構築済みモデルのスキーマを拡張可能なquery filed extraction機能をサポートしています。
つまり抽出する項目(Filed)を追加することが可能!
最大20の項目(Filed)を定義し、カスタムモデルのトレーニングを必要とせずモデルのカスタマイズができます。
制約
Layout/事前構築済みモデル(ただし UX.Tax モデルを除く)で使用可能
Layout/事前構築済みモデルとは?
検証手順
- Azure Document intelligenceのS0をデプロイする
-
Layoutをクリックする
-
Fetch from URLをクリックする
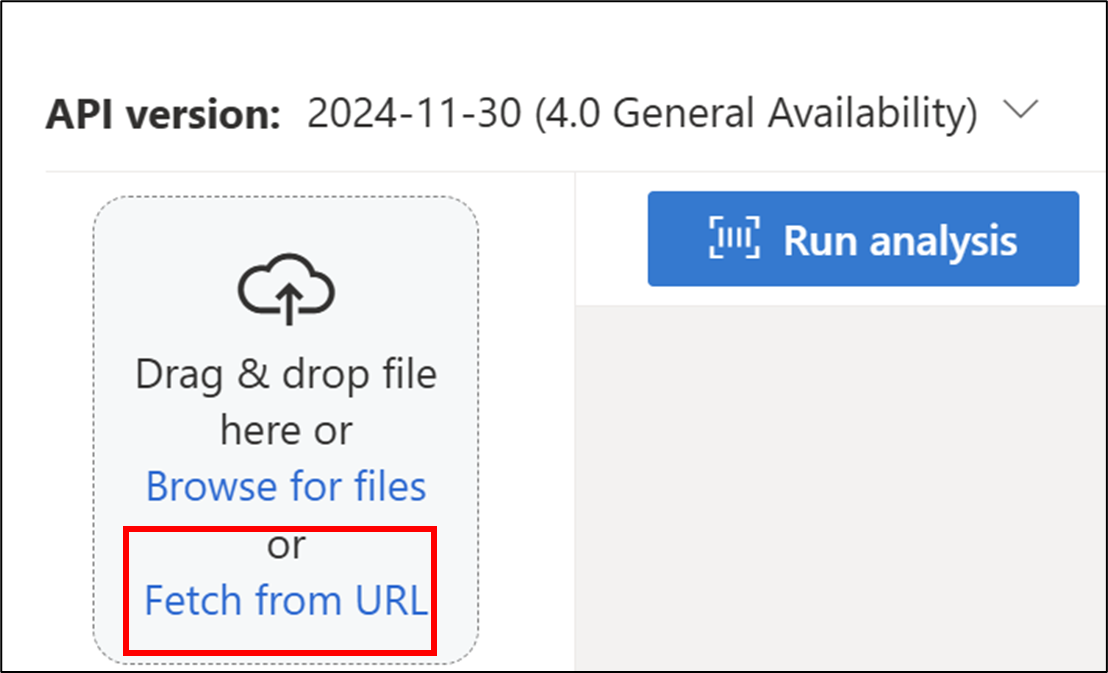
- 以下を入力し、Fetchをクリックする
https://global-assets.irdirect.jp/pdf/tdnet/batch/140120241113521226.pdf

5. uploadされたことを確認する
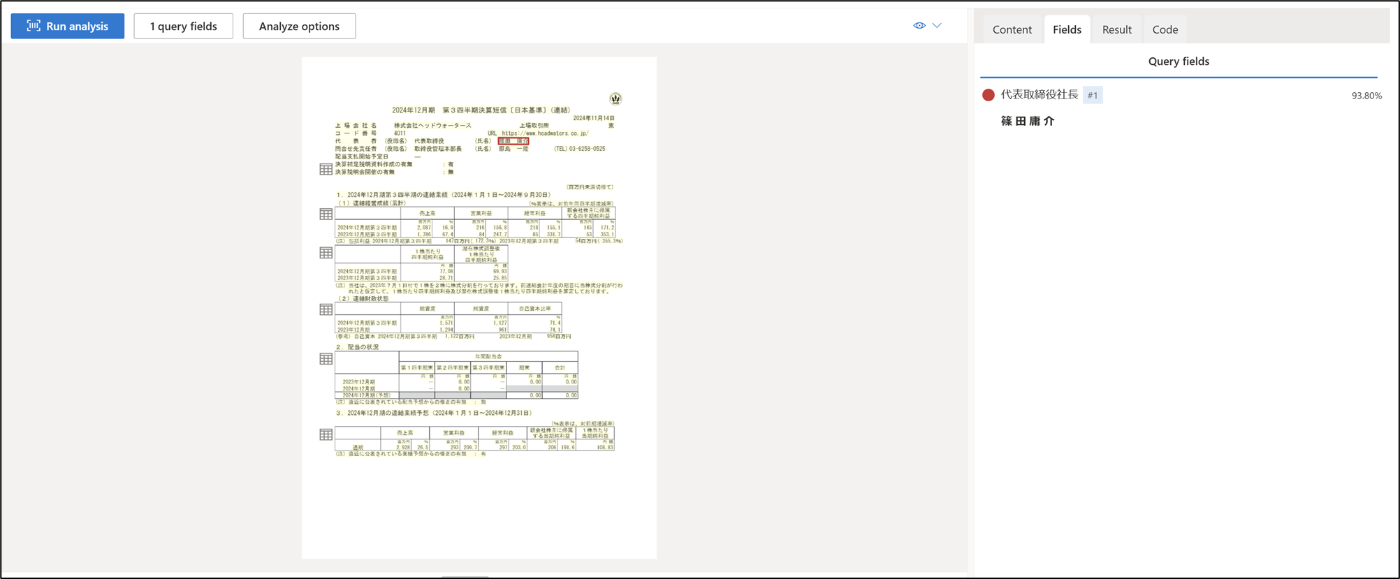
6. query filedをクリックする

7. 取得したい fileds を追加する
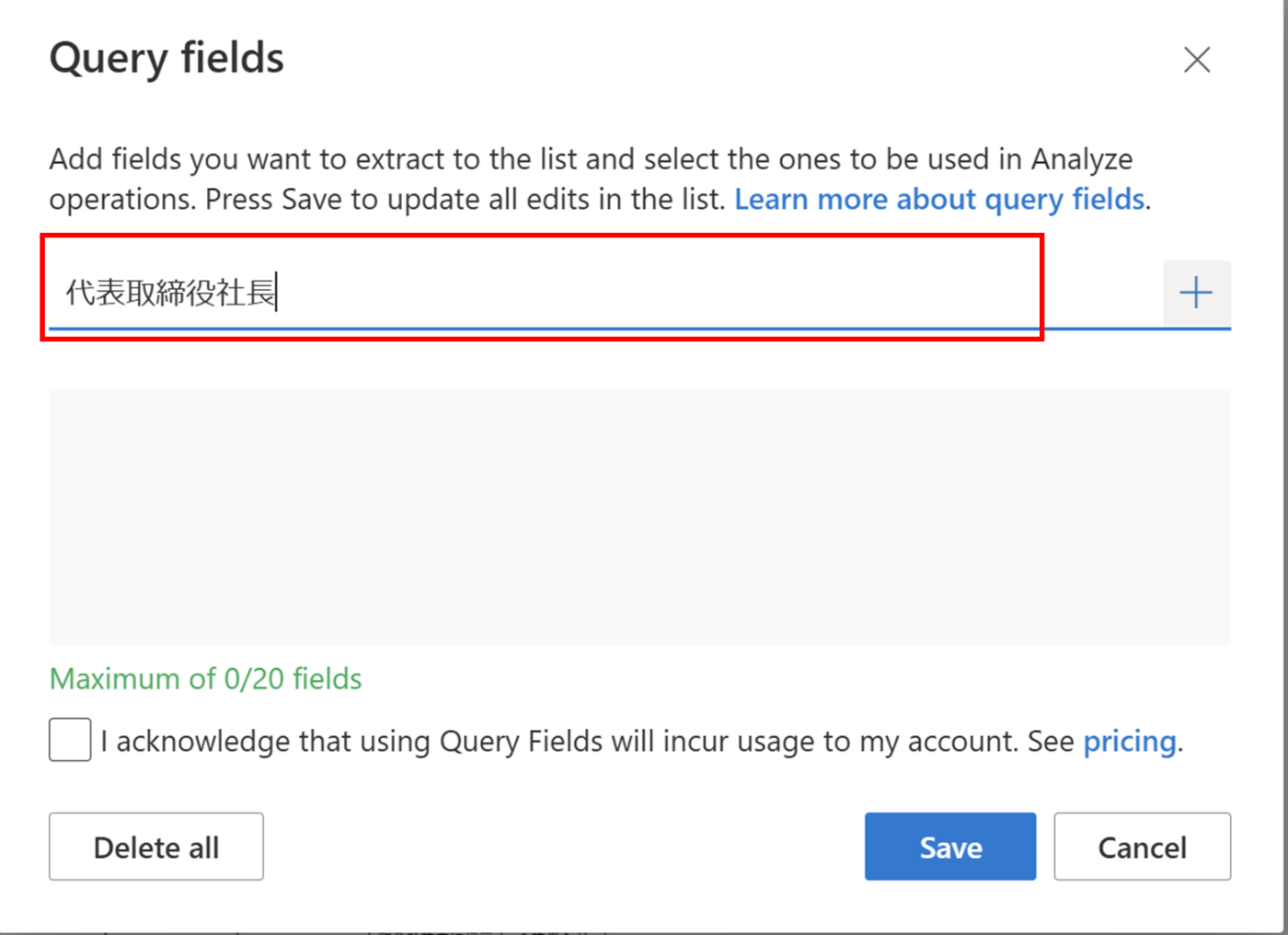
8. OCRを実行する
9. 7で追加したfiledsが取得できたことを確認する
補足
Layout/事前構築済みモデルともにFiledの追加方法は同じです。

Discussion