やること
yolov8で骨格情報を取得してみる。
手順
- WebカメラをPCに接続する
- 以下のコードを実行する
import cv2
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
model = YOLO('yolov8n-pose.pt')
# Open a connection to the webcam (usually device 0, but it may be different on your system)
cap = cv2.VideoCapture(0)
# Check if the webcam is opened correctly
if not cap.isOpened():
print("Error: Could not open webcam.")
exit()
while True:
# Read a frame from the webcam
ret, frame = cap.read()
if not ret:
print("Error: Could not read frame.")
break
# Run inference on the frame
results = model(frame)
# Iterate through results and render the annotations on the frame
annotated_frame = results[0].plot() # Use plot() instead of render()
# Display the results
cv2.imshow('YOLOv8 Inference', annotated_frame)
# Break the loop if the user presses 'q'
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release the webcam and close the window
cap.release()
cv2.destroyAllWindows()
- 以下のようなログと動画が表示される
ログ
0: 480x640 2 persons, 123.4ms
Speed: 2.1ms preprocess, 123.4ms inference, 0.9ms postprocess per image at shape (1, 3, 480, 640)
0: 480x640 2 persons, 105.6ms
Speed: 1.0ms preprocess, 105.6ms inference, 1.0ms postprocess per image at shape (1, 3, 480, 640)
0: 480x640 2 persons, 123.7ms
Speed: 1.0ms preprocess, 123.7ms inference, 0.0ms postprocess per image at shape (1, 3, 480, 640)
0: 480x640 2 persons, 115.4ms
Speed: 2.0ms preprocess, 115.4ms inference, 1.0ms postprocess per image at shape (1, 3, 480, 640)
0: 480x640 2 persons, 111.1ms
Speed: 1.0ms preprocess, 111.1ms inference, 0.9ms postprocess per image at shape (1, 3, 480, 640)
0: 480x640 1 person, 109.2ms
Speed: 1.0ms preprocess, 109.2ms inference, 1.0ms postprocess per image at shape (1, 3, 480, 640)
0: 480x640 1 person, 111.1ms
Speed: 0.8ms preprocess, 111.1ms inference, 0.0ms postprocess per image at shape (1, 3, 480, 640)
0: 480x640 2 persons, 114.0ms
Speed: 1.0ms preprocess, 114.0ms inference, 1.0ms postprocess per image at shape (1, 3, 480, 640)
0: 480x640 2 persons, 107.7ms
Speed: 1.0ms preprocess, 107.7ms inference, 0.0ms postprocess per image at shape (1, 3, 480, 640)
0: 480x640 2 persons, 114.6ms
Speed: 1.0ms preprocess, 114.6ms inference, 0.6ms postprocess per image at shape (1, 3, 480, 640)
0: 480x640 1 person, 115.4ms
Speed: 1.0ms preprocess, 115.4ms inference, 0.6ms postprocess per image at shape (1, 3, 480, 640)
0: 480x640 1 person, 108.1ms
Speed: 1.3ms preprocess, 108.1ms inference, 1.0ms postprocess per image at shape (1, 3, 480, 640)
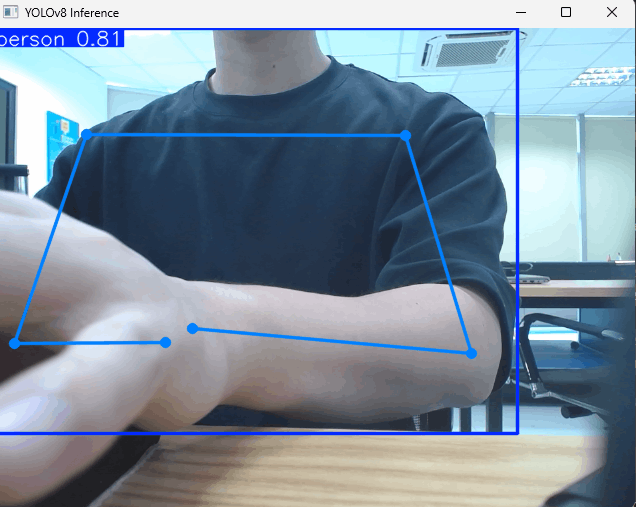
骨格情報を取得してみる
以下の記事を参考にしました。
- 以下のコードを実行
import cv2
from ultralytics import YOLO
model = YOLO("yolov8n-pose.pt")
Skeletal_information = ["鼻","左目","右目","左耳","右耳","左肩","右肩","左肘","右肘","左手首","右手首","左腰","右腰","左膝","右膝","左足首","右足首"]
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("Error: Could not open webcam.")
exit()
while True:
# Read a frame from the webcam
ret, frame = cap.read()
if not ret:
print("Error: Could not read frame.")
break
# Run inference on the frame
results = model(frame)
# Annotate the frame with the results
annotated_frame = results[0].plot()
# Extract keypoints and print them
for i, result in enumerate(results):
if hasattr(result, 'keypoints') and result.keypoints is not None:
keypoints = result.keypoints
if keypoints.conf is not None and keypoints.xy is not None:
confs = keypoints.conf[0].tolist()
xys = keypoints.xy[0].tolist()
for index, (xy, conf) in enumerate(zip(xys, confs)):
score = conf
if score < 0.3:
continue
x = int(xy[0])
y = int(xy[1])
print(
f"Keypoint Name={Skeletal_information[index]}, X={x}, Y={y}, Score={score:.4}"
)
# Display the results
cv2.imshow('YOLOv8 Inference', annotated_frame)
# Break the loop if the user presses 'q'
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release the webcam and close the window
cap.release()
cv2.destroyAllWindows()
ログ
0: 480x640 1 person, 106.0ms
Speed: 1.0ms preprocess, 106.0ms inference, 0.0ms postprocess per image at shape (1, 3, 480, 640)
Keypoint Name=鼻, X=209, Y=10, Score=0.9118
Keypoint Name=左目, X=251, Y=0, Score=0.905
Keypoint Name=右目, X=187, Y=0, Score=0.5997
Keypoint Name=左耳, X=329, Y=35, Score=0.9101
Keypoint Name=左肩, X=438, Y=220, Score=0.9406
Keypoint Name=右肩, X=82, Y=262, Score=0.9069
Keypoint Name=左手首, X=0, Y=0, Score=0.3053
0: 480x640 1 person, 103.9ms
Speed: 1.1ms preprocess, 103.9ms inference, 0.0ms postprocess per image at shape (1, 3, 480, 640)
Keypoint Name=左耳, X=352, Y=23, Score=0.6302
Keypoint Name=左肩, X=499, Y=278, Score=0.7734
Keypoint Name=右肩, X=44, Y=295, Score=0.7507
0: 480x640 (no detections), 105.7ms
Speed: 1.0ms preprocess, 105.7ms inference, 0.0ms postprocess per image at shape (1, 3, 480, 640)
0: 480x640 (no detections), 108.0ms
Speed: 1.0ms preprocess, 108.0ms inference, 0.0ms postprocess per image at shape (1, 3, 480, 640)
まとめ
yolov8で骨格の情報を取得してみた。
Azure Kinectや Orbbec Femto Bolt など骨格推定するデバイスとの精度の比較を今後やっていこうかなと思います。

Discussion