概要
Microsoft Purview(以下Purview)と Azure Databricks Unity Catalog(以下UC)を連携すると、Databricks側のカタログ/スキーマ/テーブルなどの メタデータをPurviewに取り込み、組織全体の検索・可視化・ガバナンスの起点にできます。
この記事では、土台となる「データマップ」と「スキャン」の目的を整理し、スキャンを実施してみます。
Purviewの「データマップ」とは
データマップ(Data Map) は、Purviewにおける 企業内データの索引(メタデータのデータ) です。
オンプレ/マルチクラウド/SaaSを含む様々なデータソースの 技術メタデータ(構造、場所、所有者、説明、分類、系統など)を収集・整理し、一元的かつドメインごとに管理できる状態 を作ります。
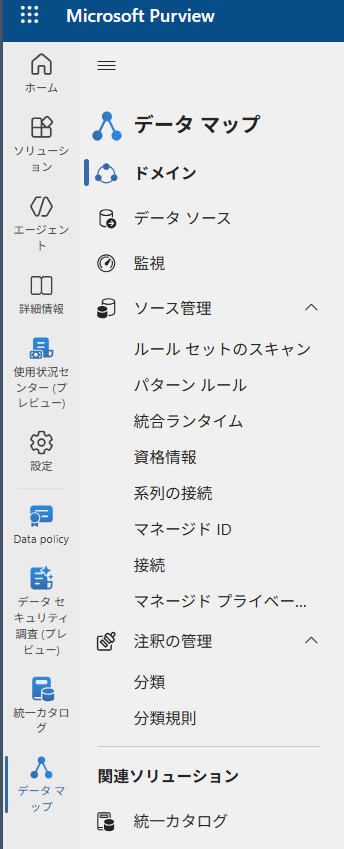
データマップのメニューはこんな感じ
ポイントは「データそのものをコピーして持ってくる場所」ではなく、どこに・何が・誰のものとして・どう使われているかを示すメタデータのレイヤー ということです。
これがあることで、利用者はPurviewの検索から必要なデータ資産へ辿り着けるし、管理者はガバナンス施策(分類、責任分界、品質、アクセス統制など)を横串で当てられます。
データマップの「スキャン」とは
データマップにデータを登録した後、スキャンを行います。
スキャン(Scan / Ingestion)は、各データソースに接続し、メタデータを読み取ってData Mapへ取り込むプロセス です。Purviewはスキャンジョブを通じて、テーブル定義や列、タグ、権限、リネージなどを継続的に更新します。
Databricks UCの場合、Purviewは DatabricksのSQL Warehouseに接続してUCメタストアの情報を取得 します。
認証方式はPAT/サービスプリンシパル/システム割り当てマネージドIDが選べ、増分スキャンにも対応しています。
なぜスキャンするのか
(1) データがどこにあっても「探せる」状態を作るため
スキャンの1番の目的は、社内外に散らばったデータ資産を“同じルール・同じ視界”で扱える状態を作ること にあります。
企業のデータは、ADLSやSQL、SaaS、オンプレDWH、BIのセマンティック層など、複数の場所に分散して存在するのが普通です。
そこで、スキャンしてデータマップに載せることで、場所や製品に依存せず、全社横断で“データ探索の入口が一つ”にできます。
それに伴い、「データがどこにあるかわからない」「データ概要を担当者しか知らない」を減らし、使う側の探索コストを下げられます。
(2) リネージで全体最適の判断ができるため
スキャンによってメタデータが揃うと、ソースをまたいだ データの流れ(リネージ)や依存関係 が可視化できます。これにより、
- どの外部データがどの加工を経て
- どのレポート/AI/業務に使われているか
までつなげて追うことができるようになります。
結果として、変更影響の把握、不要資産の整理、重要データの監査 など“全社目線の意思決定”が可能になります。
(3) 「データ活用のスピード」と「リスク低減」を両立するため
外部ソースが多いほど、活用はスピード勝負になりますが、同時にリスク(誤用、漏えい、品質問題)も増えます。そこで、スキャンで資産を見える化し、分類や責任を紐付けておくと、“安心して早く使えるデータ”の割合が増えます。
活用を止めるための統制ではなく、活用を加速するための統制、という位置づけでデータスキャンを行います。
UCをスキャンする
実際にPurviewのスキャンがどのように行われるのかをイメージするため、Databricks UCを例にデモをしてみます。
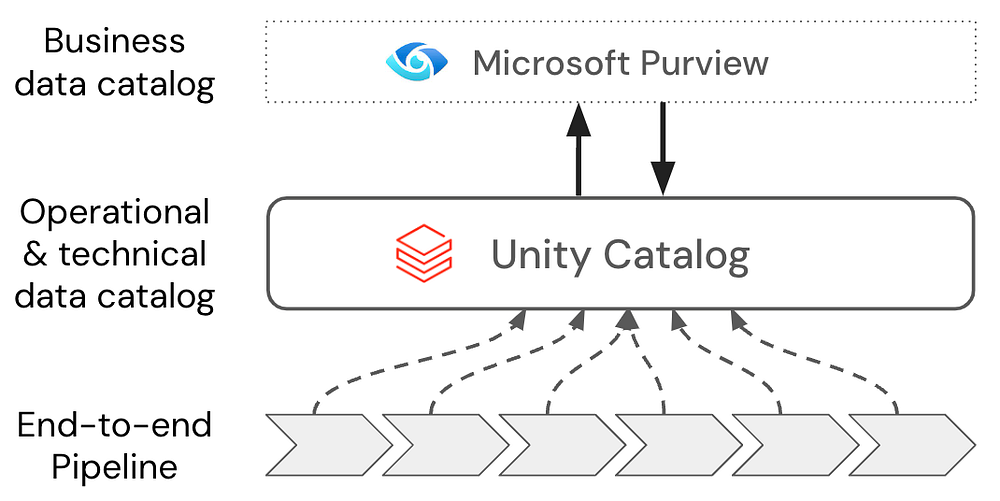
https://github.com/davegeyer/unity-catalog-purview-integration-samples
今回は上記イメージですが、Databricks部分は他サービス(SnowflakeやSAP等)にも置き換えることが可能です。対応しているデータソース一覧はこちらから。
1. (Databricks)PATを発行
Databricksの管理コンソールからパーソナルアクセストークンを発行します。

2. (Azure)キーコンテナに登録
先ほど発行したPATをシークレットとして登録します。この時に登録した名前は後ほどPurviewで使用します。

3. (Databricks)SQLウェアハウスを起動/URLパスの取得
スキャンのためにSQLウェアハウスを起動させる必要があるようです。
(私はここを見逃していて接続エラーとなっていました)
起動したウェアハウスのURLパスも後ほど必要になります。

4. (Purview)データソースを接続
登録するドメインとコレクションを予め作成しておきます。
今回は例として以下のように名前を付けています。
- ドメイン:CON(部署)
- コレクション:Databricks(ツール)
その後、「データソース」>「登録」
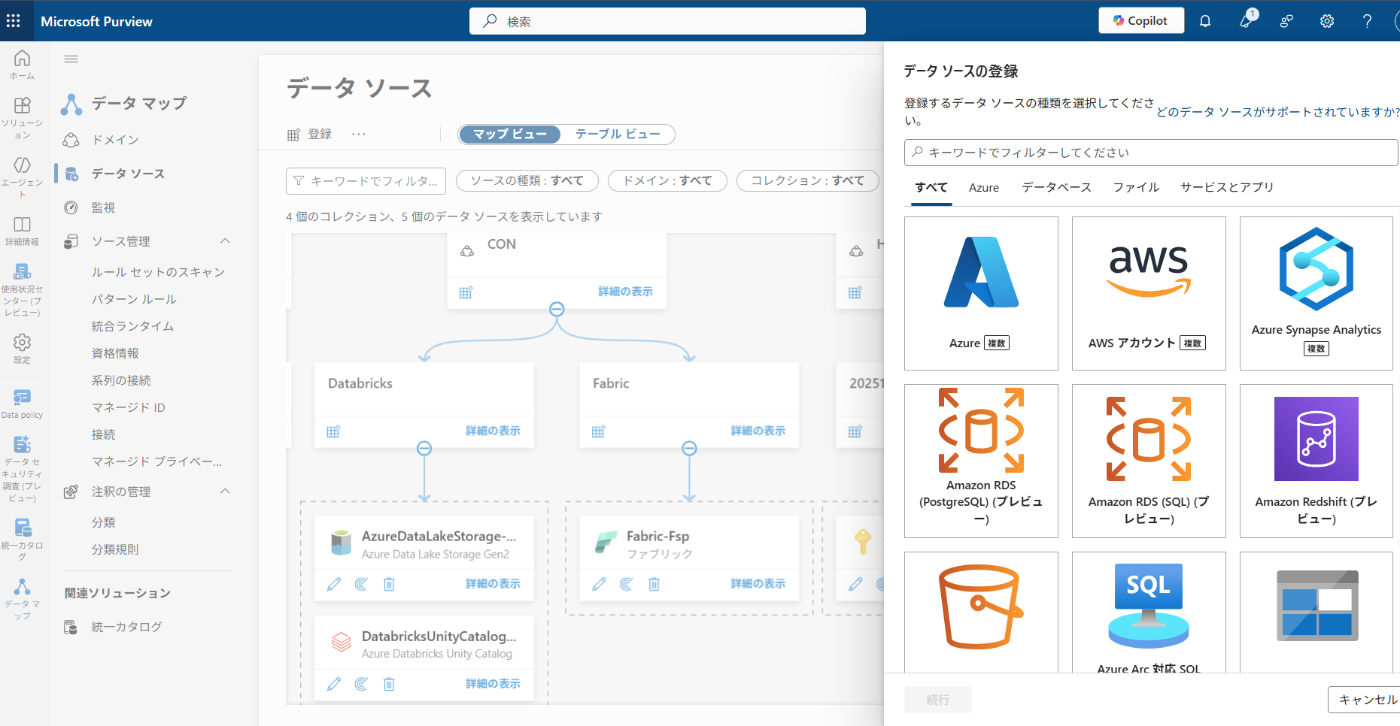
必要な情報を入力していきます。

登録できました。
5. (Purview)スキャンの設定/実施
データソースから「新しいスキャン」を選択し、必要な情報を入力していきます。


スキャンのルール(強度や実行タイミング)もここで設定します。



5. (Purview)実行/結果
スキャンの実行が完了するとこんな感じに。

スキャン結果も教えてくれる。この規模で5~10分くらい。

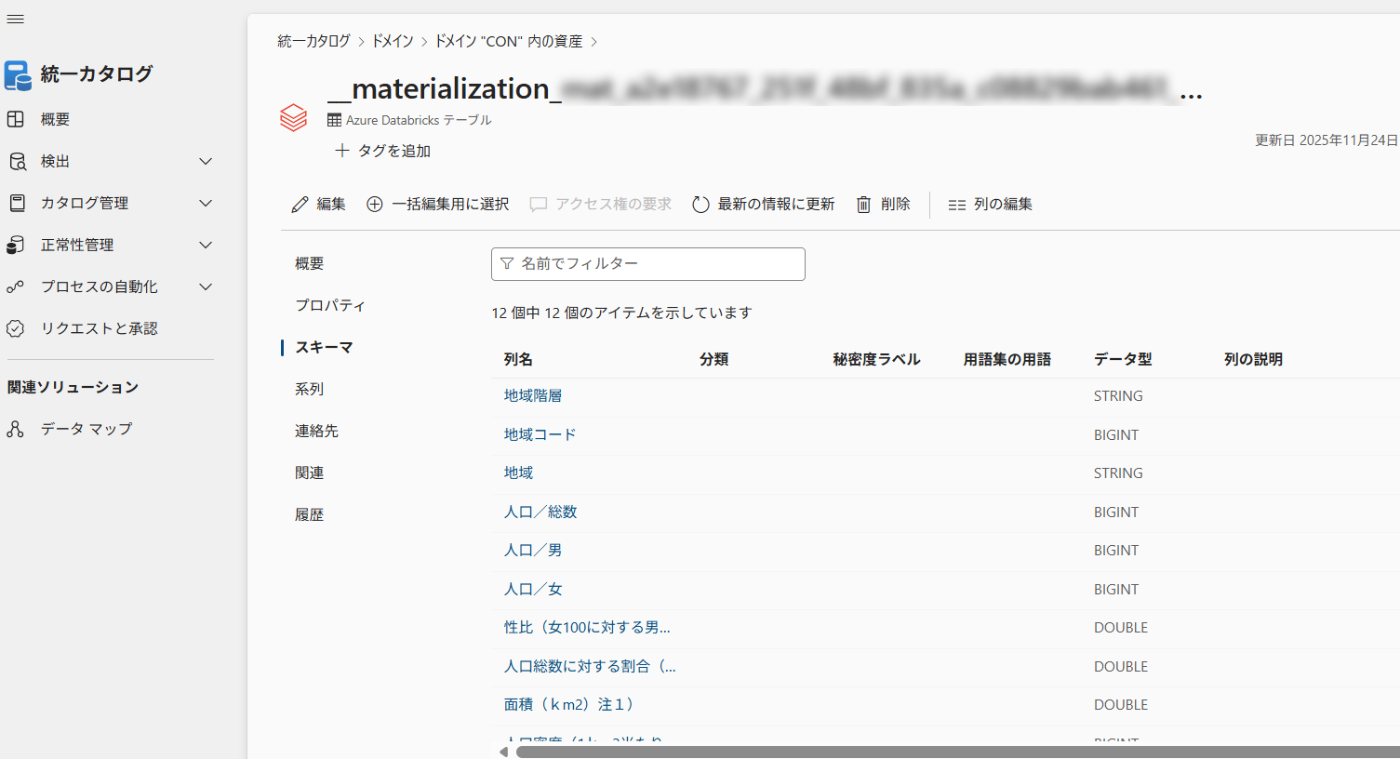
スキャンされたUCの1テーブルを見ると、作成日付や所有者、スキーマが自動判別されている。

スキーマに対して、分類や用語集を追加することで、探索性も向上できる。
以上です。たくさんスクショしました。
色々ありますが、一番手間取ったのは「権限設定」です。
Purview設定からデータソース接続まで、いろんなところで様々な権限が必要です。
特に規模の大きな組織においては組織ルールを大事にしつつ、ある程度のスピードを保てるよう、各所との連携が必要だと思います。

Discussion