前書き:このシリーズについて
「文系・非エンジニアのための基礎理論」では、“知らなくても分かる”をコンセプトに、専門知識が無くても技術的な話をそこそこ深く理解できるような記事を作成していきます。
このシリーズでは以下のことをお約束します!
- 事前に押さえておくべき知識があれば冒頭でご紹介します
- 非日常的な英単語や専門用語、義務教育に登場しない数学記号は注釈無しに使いません
こんな方に是非!
- 会議などで技術的な話になるとついていけない
- 専門書を読むと英単語や専門用語や数式がハードルになる
- とにかく簡単に知りたいけど、あまり浅い理解では満足できない
この記事のまとめ
ファインチューニングってこんなもの
- 一言で言えば学習の手法の一つ
- 既存のモデルをタスクに合わせて学習させて調整すること
- モデルを一から学習させるよりも、少量のデータや学習で高い精度のモデルにすることができる
ファインチューニングってこんなイメージ
ファインチューニングというのは、AI開発の4要素データ、モデル、学習、タスクで言うと学習の部分に深く関わる概念で、簡単に言えば学習の手法の一つです。
イメージとしては三国志の勉強を世界史選択の学生にさせるようなものです。
世界史選択の学生(モデル)なら歴史を一から勉強しなくても、世界史の基礎知識の上に三国志の細かい知識(データ)を上乗せするだけなので、歴史を全く勉強したことがない学生と比べて、少ない教科書(データ)や勉強量(学習)でも試験の成績を伸ばすことができそうですよね。
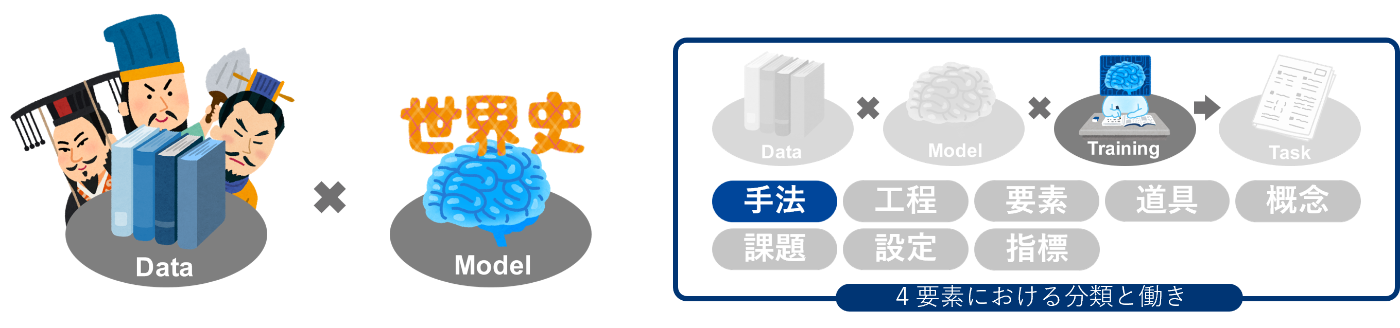
これと同じで、AI開発においても、タスク(ここで言うと三国志の問題)に対してある程度経験のあるモデル(ここで言うと世界史選択の学生)を導入して学習させることで、少ないデータや学習でも高い精度を出すことが可能になります。この手法をファインチューニングと言うのです。
もう少しだけ専門的な話
先述の通り、ファインチューニングと言うのは既存のモデルをタスクに合わせて学習させて調整する手法です。これには以下のようなメリットがあります。
- 少量のデータでも複雑なタスクに適応させることができる
- ある程度学習が済んだ状態から始めるので開発コストを削減できる
また、ファインチューニング自体は少量のデータで学習できる手法ですが、さらに少ないデータでも学習できる手法を少量データ学習と言い、これにも様々な方法があります。

Discussion