執筆日
2024/09/30
概要
公式ページの概要要約
PyMuPDF4LLMは、LLMやRAG環境で必要な形式でPDFコンテンツを簡単に抽出することを目的としています。
LlamaIndex文書出力だけでなく、Markdown抽出もサポートしています。
ということで、名前の通りPDF処理ライブラリとして知られるpymupdfにLLMのための出力機能を持たせたライブラリになっています。
使い方は非常にシンプルでAPIドキュメントは、マークダウン変換を行うto_markdown関数とLlamaIndex文書処理のためのLlamaMarkdownReaderクラス(load_dataしかクラス関数がない)しかありません。(なので解説記事を出すまでもない気もしますが日本語ドキュメントはないので……)
従来のPDF処理ライブラリの弱点を完全に克服しているとは言えないものの使いやすさの点で素晴らしいライブラリだと感じました。
依存ライブラリインストール
pip install pymupdf4llm
スクリプト
今回はテスト用のPDFとしてちょうどいい感じにいろんな形式の表が含まれていたヘッドウォータースの決算短信を使用しました。
最短でマークダウン出力を試す
一行でマークダウン出力したテキストを文字列型で受け取ることができます。
まあまあ文章量のある12ページのPDFが約1.02秒で処理でき十分な速度がありそうです。
ただし、PDFの全ページを一括で処理するためページ数が多いPDFを処理する場合はメモリに気を使う必要があり、自動化したシステムで使うには不安があります。
import pymupdf4llm
filename = "テスト.pdf"
md_text = pymupdf4llm.to_markdown(filename)
with open("output.md", "w", encoding="utf-8") as f:
f.write(md_text)
結果
配置の複雑な文字
適当に空白を入れて抽出してくれました

↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓

いろんな表
OCRや画像認識で上手くいかないがちな結合されたセルのある表はやはり完全に抽出は難しいです。こればっかりはOSSだと何を使っても……という感じなので逆に諦めが付きます。(この手の表はGPTに画像分析させても上手くいきません。表抽出特化なMLモデルじゃないとまだしばらくは難しそうという印象です。)
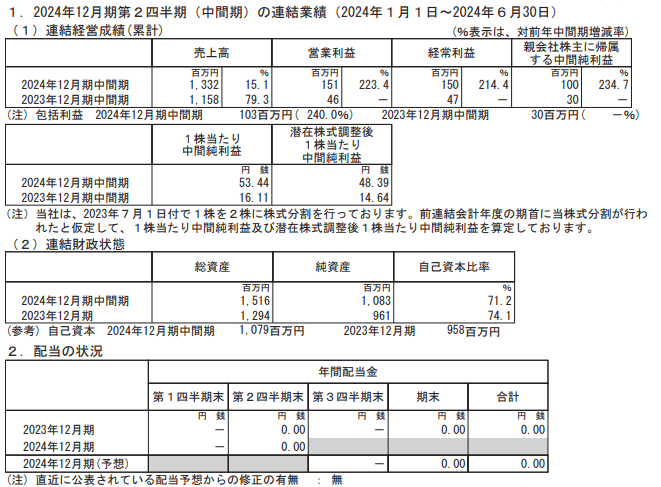
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
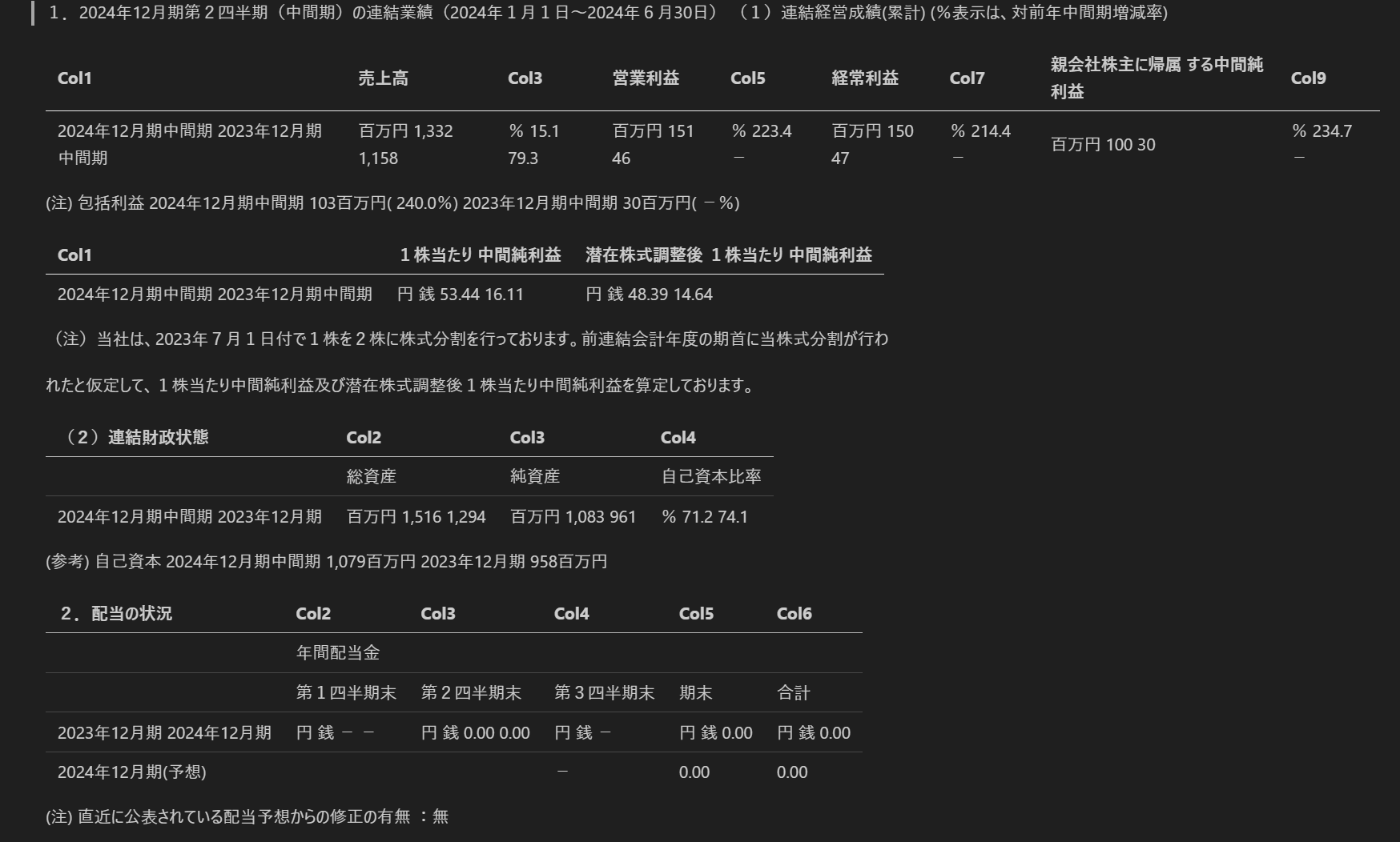
実線による明確なラインがなく色分けだけだと表として認識できませんでした。
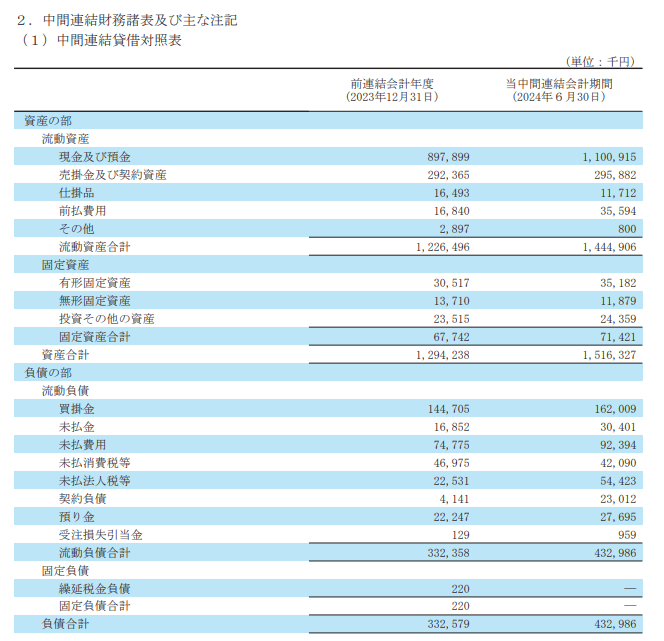
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓

文書ではないPDFから画像を抽出
オプションでwrite_imagesをTrueにすることで画像を切り出してくれます。追加のオプションでdpiを設定したり、画像の出力フォルダを設定したりもできます。
import pymupdf4llm
filename = "テスト.pdf"
md_text = pymupdf4llm.to_markdown(
doc=filename,
write_images=True,
)
程よく画像と文字があるサイトとして上野動物園の公式ページをお借りしました。ブラウザの印刷機能でPDF化しました。
WebページのPDF化だと文章も塊で切り出して画像としてしか認識できませんでした。切り出しの精度自体は高いように感じますが、バナーや文字だけの部分は画像として認識するか微妙でした。また、先ほどの決算資料の色付き表は画像として認識されました。様々なフォーマットの情報が張り付けられたPDFだと手放しに抽出した画像データをすべて使っていると使用トークン数が爆上がりしそうで怖いです。
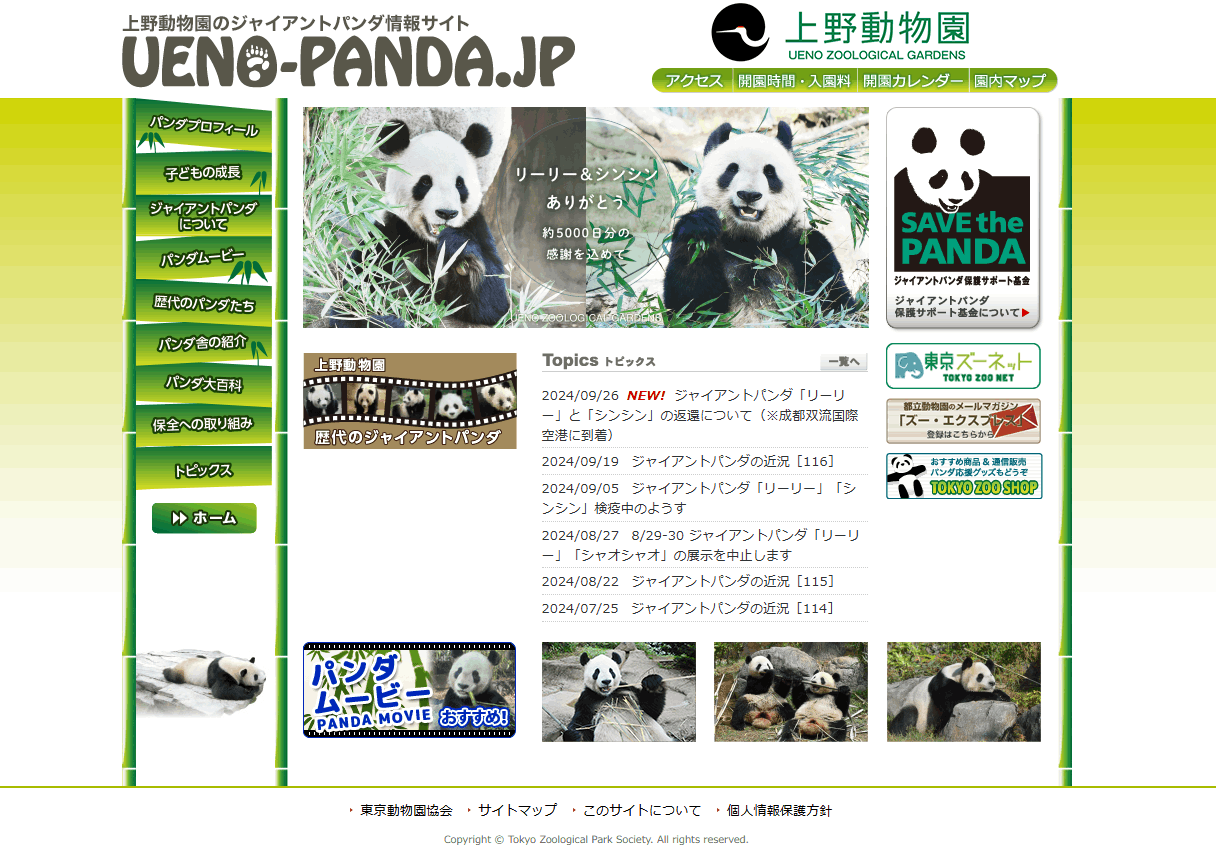
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓










感想
pymupdfも便利ですが、多機能なため汎用的に使いこなすには慎重に設計を考えなければいけません。その点シンプルな機能だけのpymupdf4llmは非常に簡単に汎用的なマークダウン化処理をしてくれるため、複雑な構造の文書がないことがわかっていればかなり有力な候補になると思いました。あとは人間が読みやすい文書を書くだけ……。
proライセンスがあればPDFだけでなくMSのオフィス文書にも対応できるらしいのでいつか触ってみたいです。
参考

Discussion