


やってみること
Microsoft FabricのData Wranglerを使ってみる
前提
以前検証した際に作成した、NotebookとLakehouseを使用する
手順
- 以前検証したNotebookを開く
- 下記のコードを実行する
df = spark.sql("SELECT * FROM test01.temperature_humidity LIMIT 1000")
display(df)
- データを確認
- 「データ」をクリック
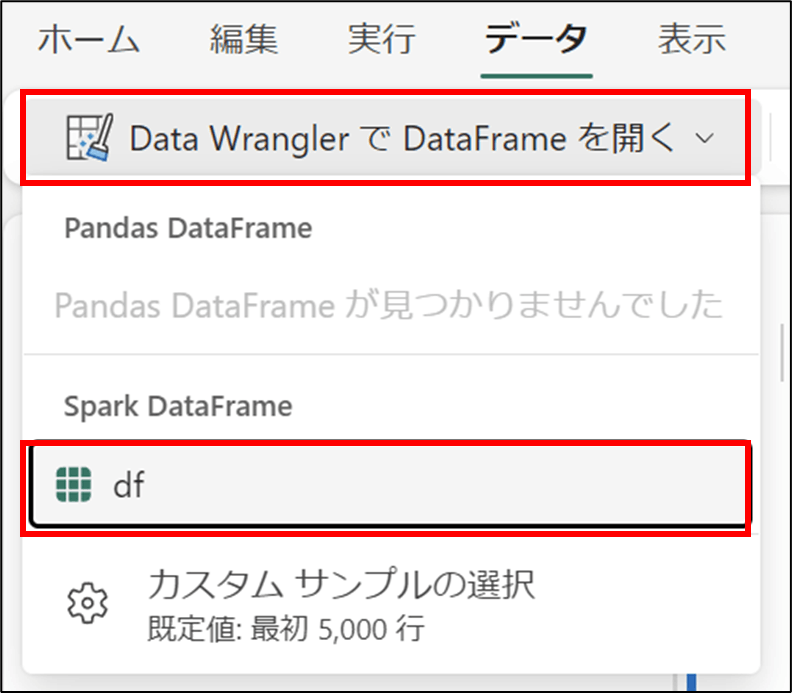
- 「Data WranglerでDataFrameを開く」を選択し、「df」をクリック
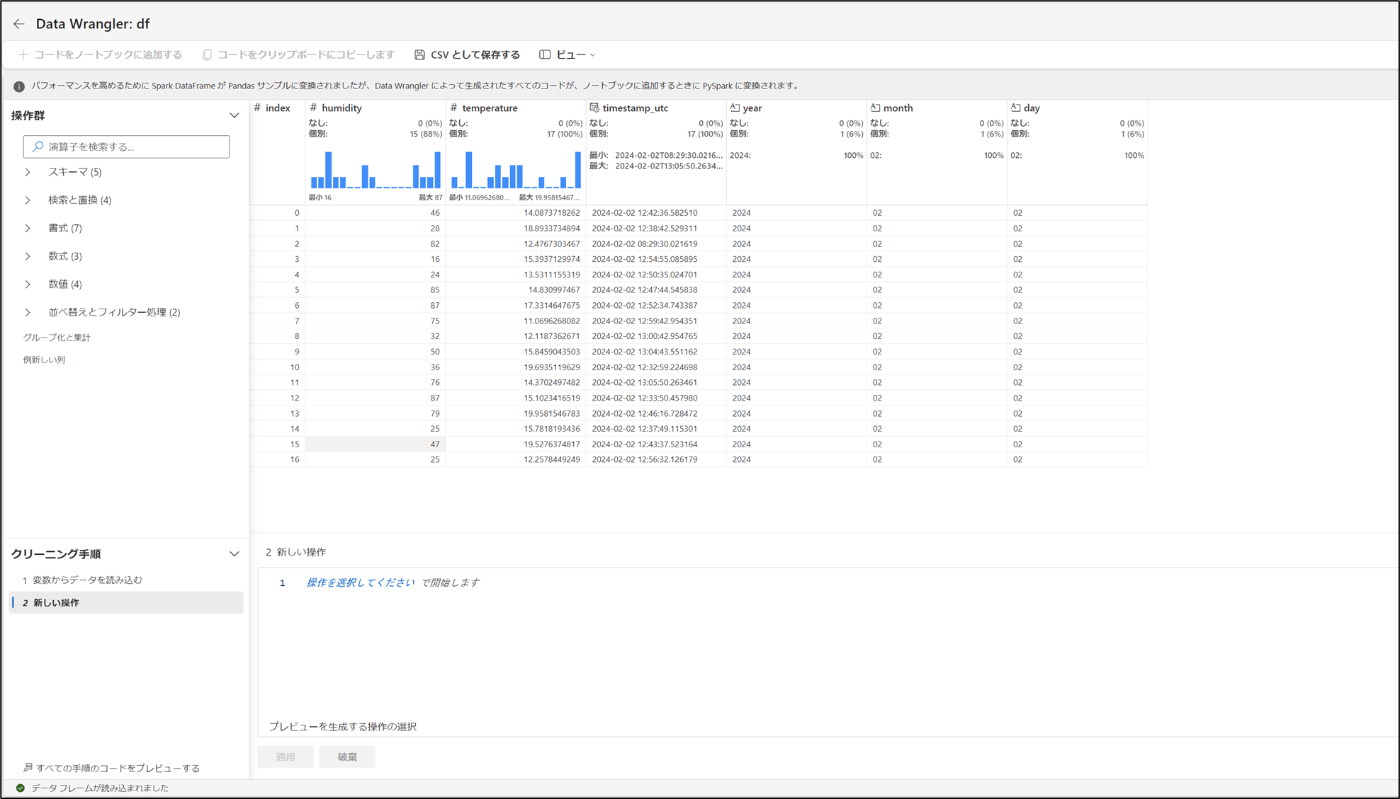
- Wraglerでdf(DataFrame)が開いたことを確認
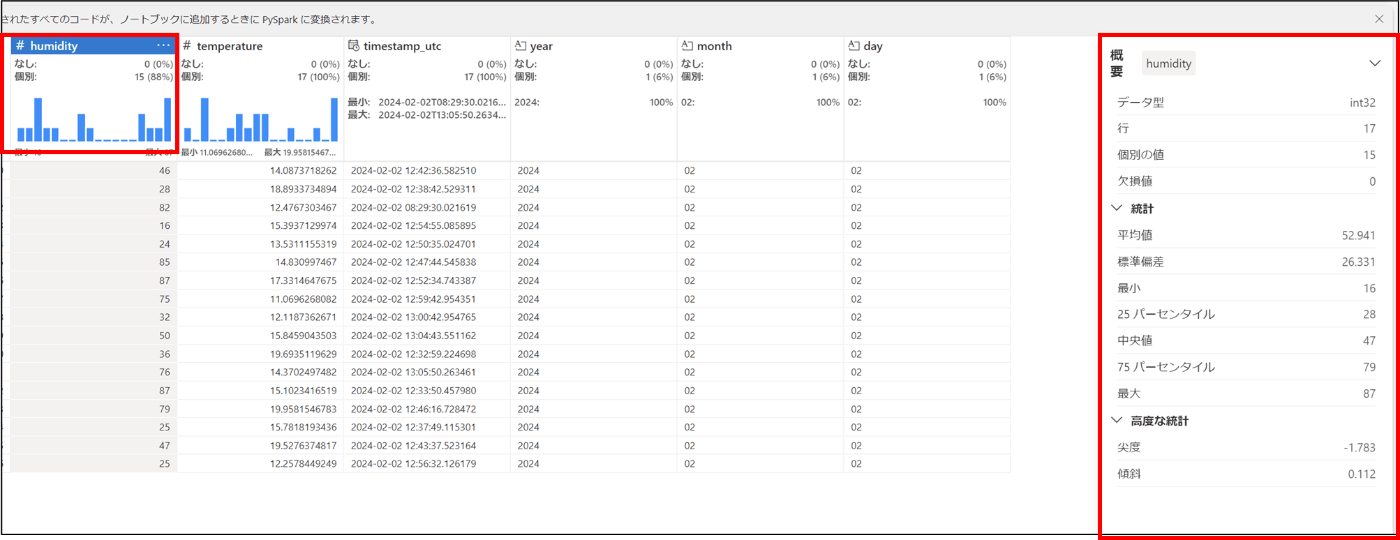
- 「humidity」を選択すると、データの概要が確認できる
- 「temperature」を選択し、「四捨五入」をクリック
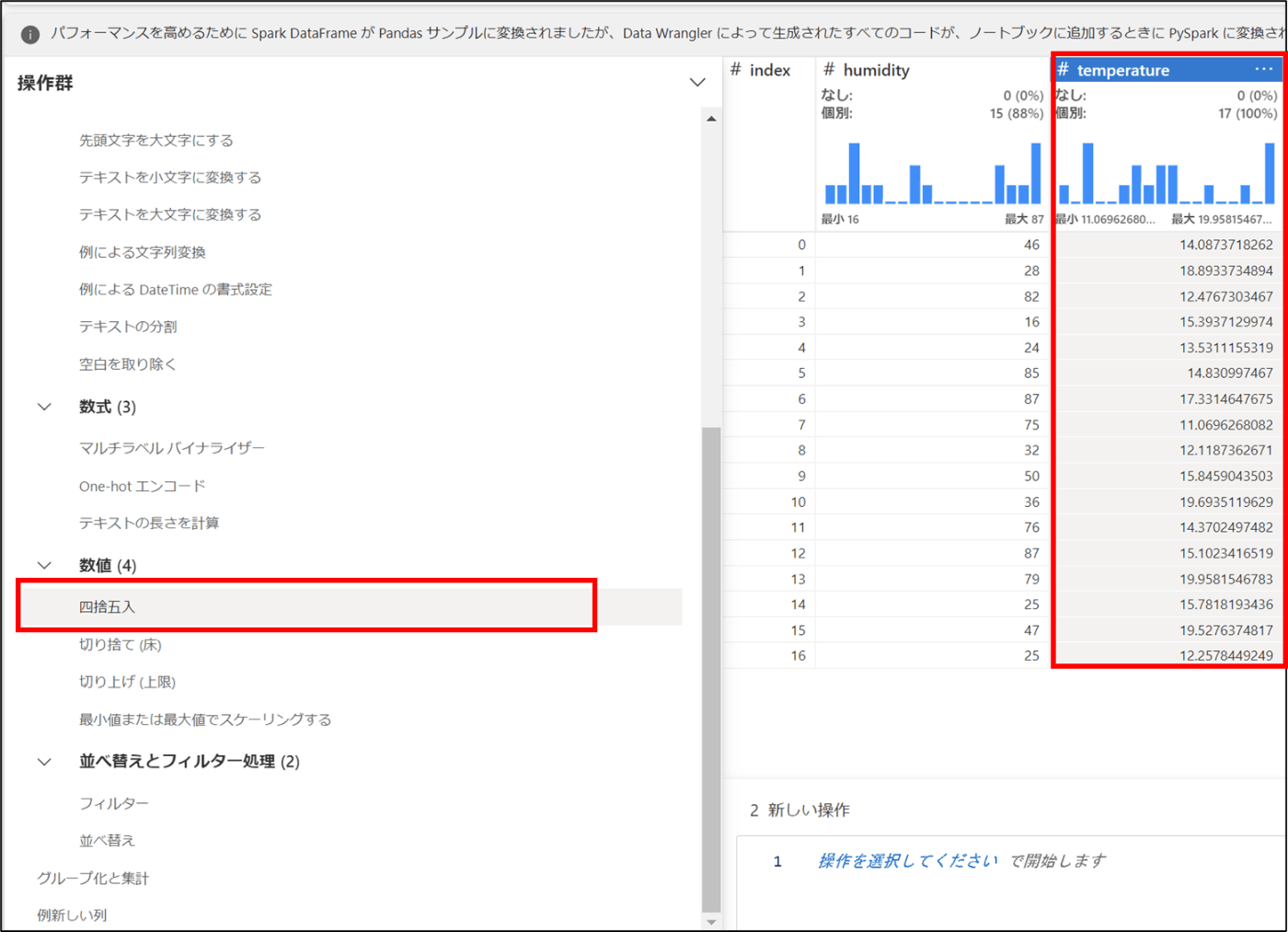
- 「小数点以下の桁数」を1と入力し、「適用」をクリック
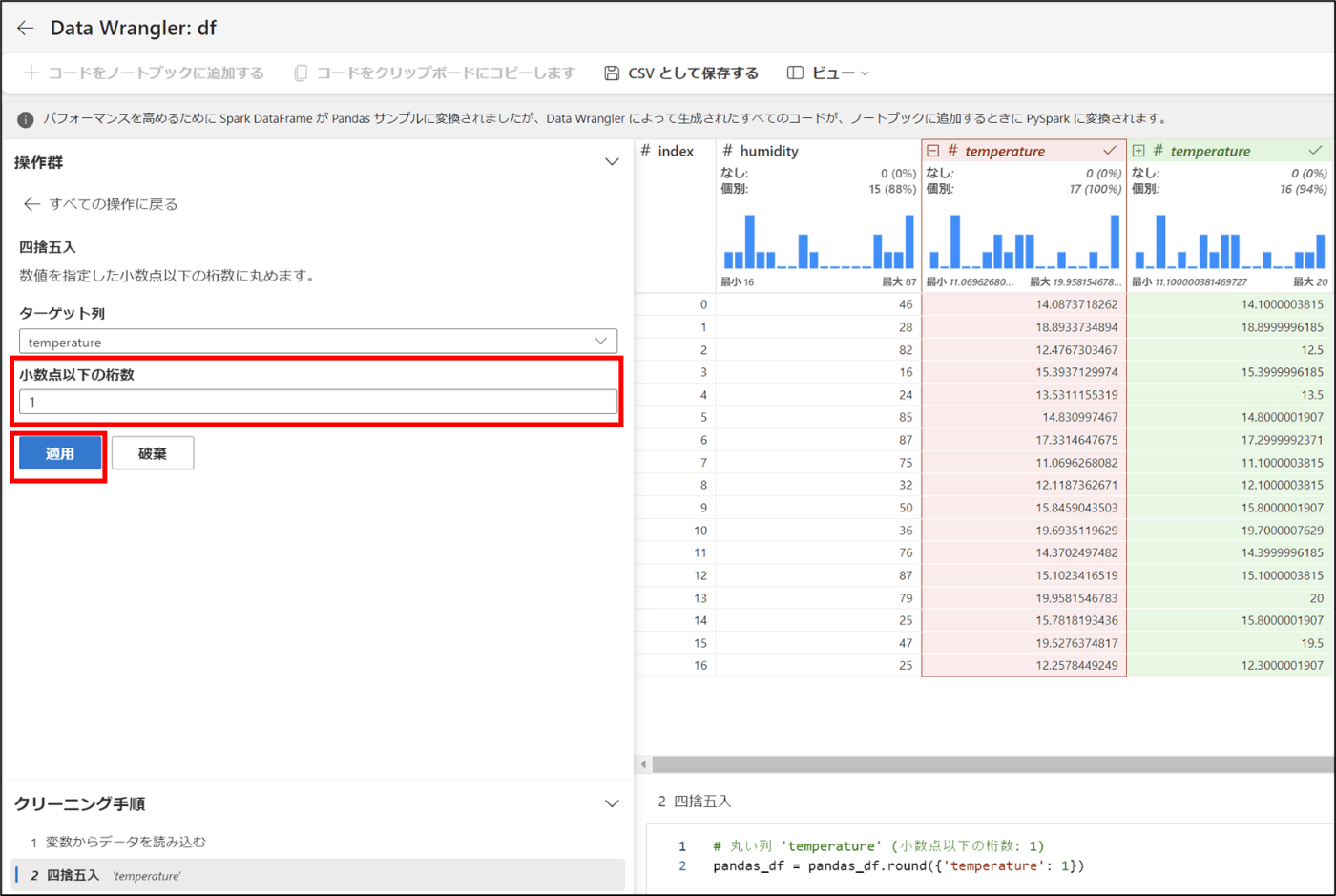
- 適用されたことを確認
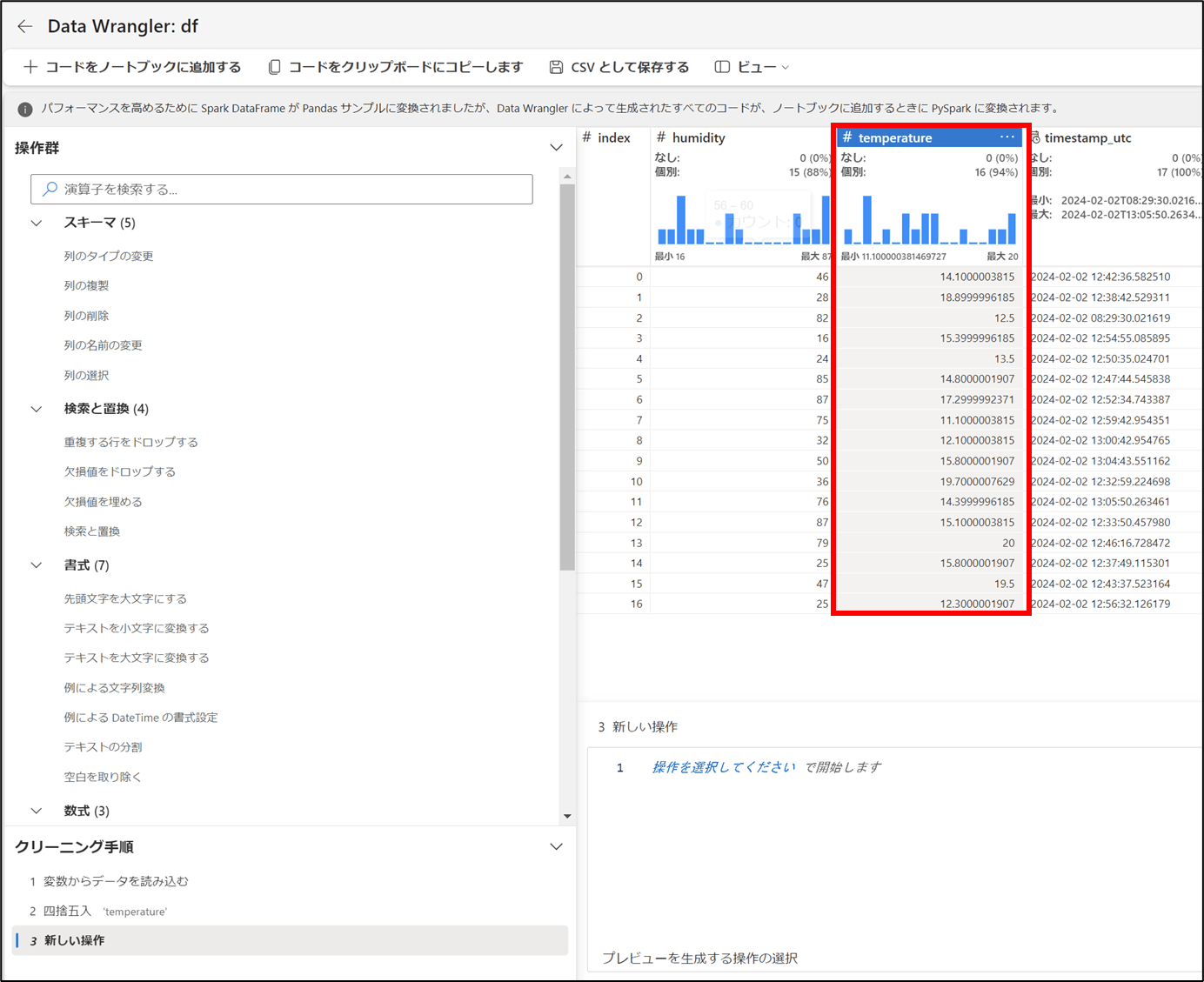
- 「+コードをノートブックに追加する」をクリック
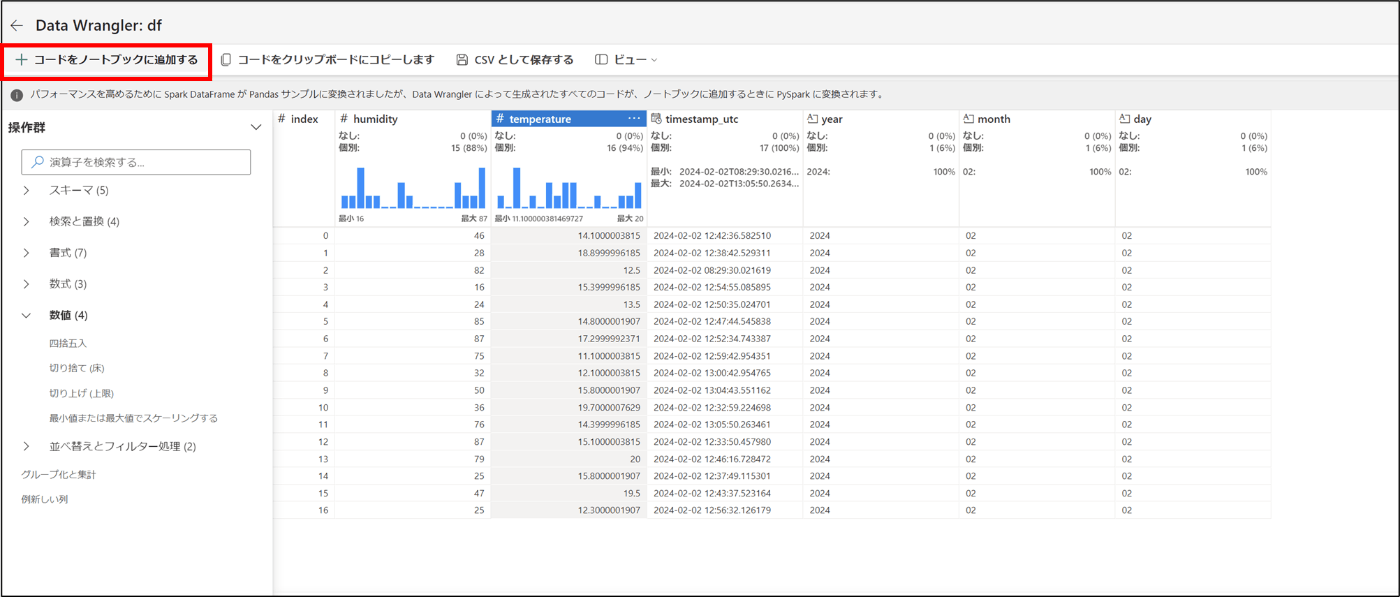
- 「追加」をクリック
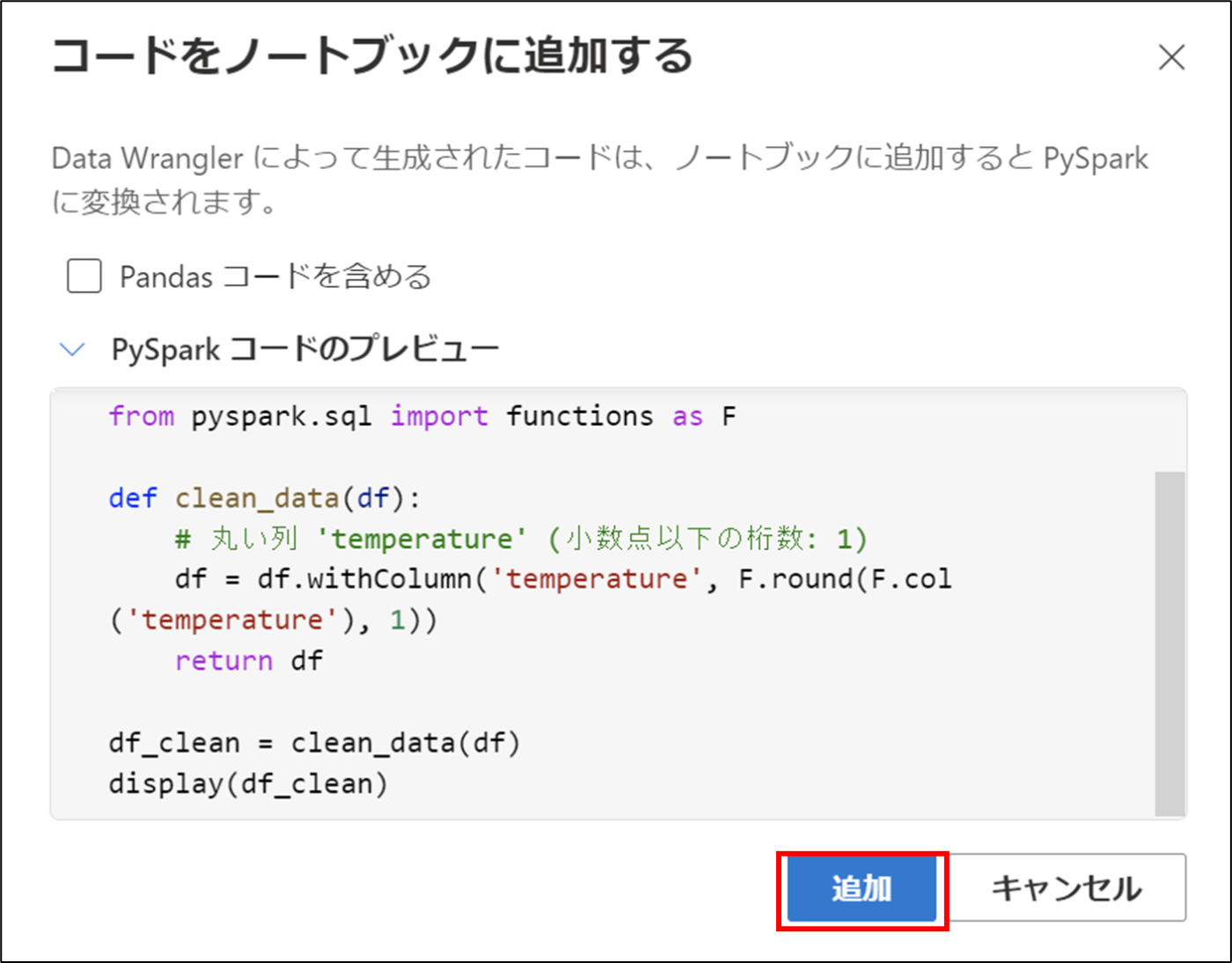
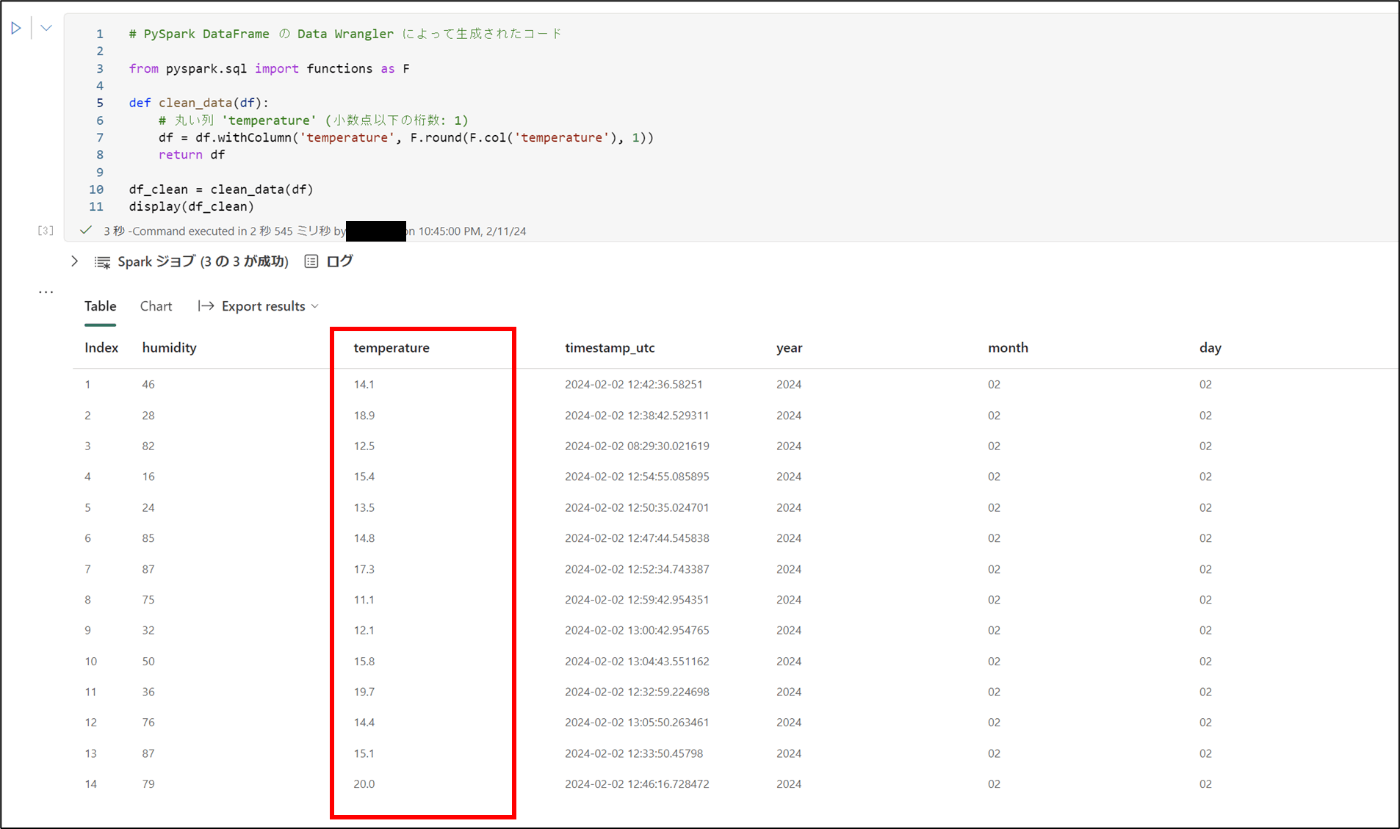
13.コードが生成される - コードを実行し、temperatureの値が変更されたことを確認
操作群一覧



まとめ
Data Wranglerは、データの前処理をGUIで出来るのが特徴だと理解しました。

Discussion