軽量でEdgeでも動くGraphDB
を探していたら、このkuzuDBというものがあるそうです。

主にGPT-5にまとめてもらいましたが、on the Edgeで動くパーソナライズ向けGraphDBとしてだけでなく、Edge RAGを実現するための主要コンポーネントになる可能性もあるなと思いました。
Kùzu(KuzuDB)の特徴
Kùzuは、「組み込み型(embedded)」のプロパティグラフデータベース(GDBMS)で、「大きなグラフに対する複雑な分析クエリ/結合が重いワークロード」に向けて設計されている。
| 項目 | 内容 |
|---|---|
| データモデル/クエリ言語 | プロパティグラフモデル。ノード(vertex)、リレーションシップ(edge)それぞれにプロパティ。スキーマをあらかじめ定義する。クエリ言語は Cypher。 (Kuzu) |
| アーキテクチャ | 埋め込み型(in‐process)で動く。サーバーとして別プロセスを立てる必要がなく、アプリケーションに組み込んで使える。 (Kuzu) |
| ストレージ/インデックス/内部構造 | ディスクベースの列指向(columnar)ストレージ。隣接関係(adjacency list)/結合(join)用インデックスが CSR(compressed sparse row)や列指向データ構造を使っている。ベクトル化処理(vectorized)、因子化された処理(factorized)といった query processor の最適化が入っている。マルチコア対応・並列処理。ACID(直列化可能なトランザクション)をサポート。 (Kuzu) |
| 検索/拡張機能 | フルテキストサーチ、ベクトル検索(vector index)、グラフアルゴリズムのパッケージなどを標準搭載。AI・データサイエンス周りのエコシステムとの統合にも力を入れている(Parquet, Arrow, Pandas, LangChain等) (Kuzu) |
| ライセンス・O/S | オープンソース(MIT ライセンス)。ただし、エンタープライズエディションとしてスタンドアローンサーバー展開、セキュリティ/観測性/バックアップやリカバリー等の追加機能を持つものも用意されている。 (Kuzu) |
長所
- 組み込みで軽量 → アプリケーションへの導入が比較的容易
- 高速な結合(joins)、大きなグラフの分析クエリ向け最適化されている
- 最新のストレージ・インデックス構造(CSR, 列指向, vectorized等)を使って速度を追求
- プロパティグラフとCypherを使うため、Neo4j等との親和性がある(学習コスト低め)
- RDBMS等/列ストア型DB形式のデータとの相性が良く、既存データをグラフとして扱いたい用途に便利
短所/制限的な点
- 分散構築(クラスタリング・シャード・マルチマシン環境)での使用例・サポートが十分かどうか不明(2025/9時点)
- スキーマ変更や複雑なスキーマ設計(ネスト・複合キーなど)の制限がある場合あり(例:現状「複合キーをサポートしていない」との記述が使われている例あり)
https://fithis2001.medium.com/a-graph-gold-model-for-the-imdb-dataset-36396fc3944f - 組み込み型なので、フルマネージドクラウドDBサービスのような運用管理機能(HA やバックアップ・フォールトトレランス等)の一部はエンタープライズ機能が必要
- サーバー型・クラスタ型のグラフDBに比べるとスケールアップ(単一マシン内でのメモリ・ディスク容量)には限界がある
競合
| 製品 | 特長/強み | Kùzu との差異・勝ちどころ・弱点になるところ |
|---|---|---|
| Neo4j | プロパティグラフの老舗。豊富な機能、商用サポート充実、分散/クラスタ構成。可視化ツール・エコシステムが整っている。 | Kùzu は組み込み型で軽量、高速。Neo4j はサーバー型で大規模展開に強い。パフォーマンスで Kùzu が優れるケースも。だが Neo4j は成熟度・運用体制で勝る。 |
| TigerGraph | MPP(Massively Parallel Processing)型で大規模グラフ解析に強み。ビジュアルクエリや GSQL等の独自言語や使い勝手も工夫されている。 | Kùzu は分散/クラスタでの能力はそこまで報告されていない。TigerGraph が必要な規模だと Kùzu 単体では足りない可能性。 |
| NebulaGraph | オープンソース、分散グラフデータベース。巨大なグラフ・複数ノード構成での高可用性/スケーラビリティ。 | Kùzu のほうが組み込み性やアプリへの統合や軽さでは優れるが、NebulaGraph のほうがクラスタ環境での大規模利用に耐える設計。 |
| ArangoDB | マルチモデル DB(ドキュメント/グラフ/キー値など)をサポート。データモデルの柔軟性が高い。 | Kùzu はグラフ特化、プロパティグラフモデル。もしアプリで複数モデル(ドキュメント+グラフなど)が必要なら ArangoDB の方が柔軟。 |
| Amazon Neptune / Azure Cosmos DB / Google Cloud Graph 型サービス | クラウドネイティブ、マネージドサービス、スケーラブル、可用性/運用に強み。 | Kùzu は埋め込み型でローカル処理/アプリ内処理が得意。クラウドネイティブな分散や SLA 必須の用途ではネイティブクラウドDBの方が安心。 |
実例・ベンチマーク・ユースケース
いくつかの実例やベンチマークが報告されている。
Neo4jとのベンチマーク比較
人‐関心‐ロケーションなどの人工のソーシャルネットワーク構造を持つデータセットを用いて、CypherクエリについてKùzuとNeo4j Community Editionを比較した研究がある。Kùzu の方がかなり高速であるという結論を出したもの。
Relational→Graphデータ変換
リレーショナルデータをそのままグラフスキーマに落とし込んで、ノード/リレーションテーブルとして扱い、グラフクエリを行う例。既存データを活かす用途でのユースケース。
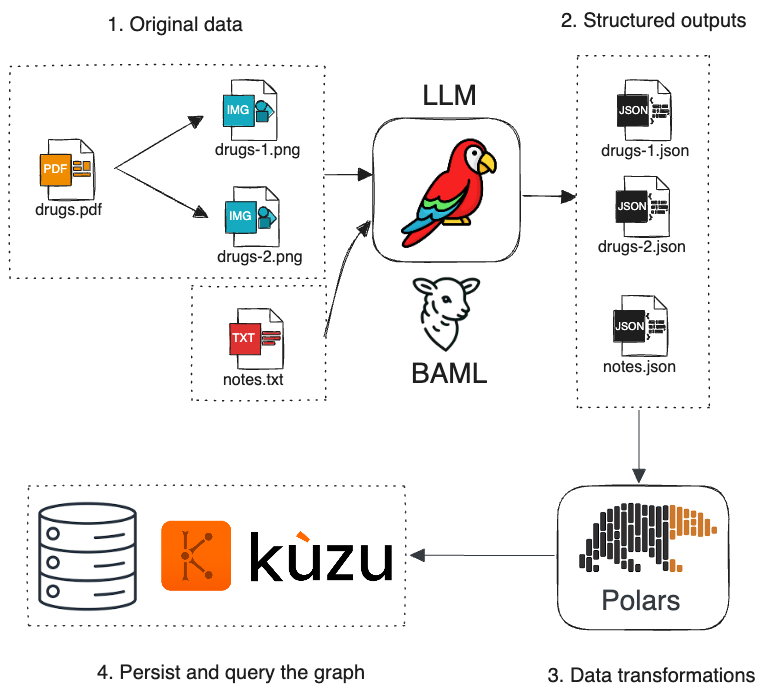
非構造化データからのグラフ変換
PDF/画像/テキストなど非構造化データをLLM や専用処理(例:BAML)で構造化 JSON に変換し、Kùzu に取り込んでグラフとしてクエリするワークフロー。 Q&A/情報抽出/検索補助型のアプリケーションで使える。
Kuzu Blog
gitlab knowledge graph
軽量で高速という理由かもしれませんが、このくらい複雑そうなサービスでも使われている。
Kùzuが得意なケース
- アプリケーション内部で、グラフ構造を扱いたいが、重いサーバ型DBを立てたくない/運用が大変な環境 → 組み込みで使える点が強み
- 知識グラフ (knowledge graph)、推薦システム、複雑なパス探索・結合が多数ある分析型クエリ
- データサイエンス/機械学習用途で、グラフを使った前処理や探索的分析を手軽に行いたい人/チーム
- 非構造化データを構造化AI/LLM と組み合わせてグラフに落として探索したい用途
逆に向かない/慎重になるべき用途
- 超大規模データを複数サーバーで分散させて運用する必要があるとき(クラスタリング/分散処理が十分サポートされていない場合)
- 商用SLAや高可用性・監査・セキュリティ要件が非常に高い組織(ただし Enterprise版でこうした機能を補っていく可能性あり)

Discussion