はじめに
今朝(2025/08/06)の朝にgpt-ossが発表されました。
詳細は下記のリンクを参照してもらえたらと思います。
ざっと説明すると、OpenAIが出した誰でも使える"オープンウェイト"な推論モデルです。
ライセンスはApache2.0です。
[OpenAI公式リリース]
[npakaさんまとめのgpt-oss概要]
FoundryLocalで手軽に動かしてみる
FoundryLocalでもすぐに使えるようアップデートが入ったので早速動かしてみたいと思います。
FoundryLocalについては弊社メンバーの記事を参考に導入をしてください。
OpenAIの公式リリースにも記載の通り、早速FoundryLocalですぐに使えるようになっていました。
foundry model listでモデル一覧を確認すると・・・
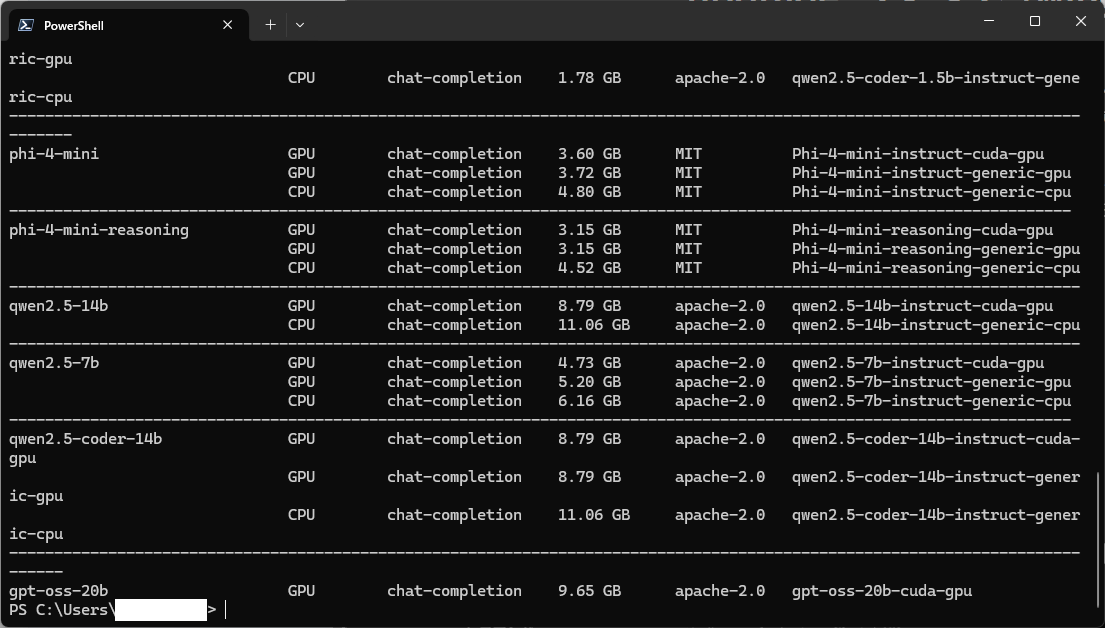
gpt-oss-20b-cuda-gpuがリストの一番下に存在が確認できました。
FoundryLocalのリリースノートにも記載されていますが、現状サポートされている環境はNVIDIAのGPUが搭載されており、なおかつVRAMが16GBの環境となります。
AMDやIntelのGPU、またmacOS(AppleSillicon)のサポートは後日との事です。(8/6現在)
ちなみに、今回の動作検証に使用したGPUはNVIDIA RTX 4070Ti SUPER(VRAM 16GB)となっています。
gpt-ossを起動
次のコマンドでモデルのダウンロードからロードまで実施してくれます。
foundry model run gpt-oss-20b

何か質問してみた
質問内容は「ロサンゼルス・ドジャースについて教えて。日本語で回答して」と英語で入力しました。

ちなみに英語にしているのは、日本語を直接入力した場合に質問の内容がおかしくなってしまったので英語にしています。
FoundryLocalにはまだ不具合などがあるので、SDKやAPI経由だと正常に動く可能性もあります。
また、質問の直後からGPTの思考途中と思われるテキストも出力されています。
出力されたテキストの末尾の方まで追っていくとFinally, I Will produce the final answer.という文字列とともに、最終的な回答が記載されています。

本来であれば、以降の文字列だけが応答として返されるのが正常な動きのように思えます。
実行時の負荷とVRAM使用率は下記の通りで、90~100%近くを使用しており、VRAMもほぼ全部使い切っています。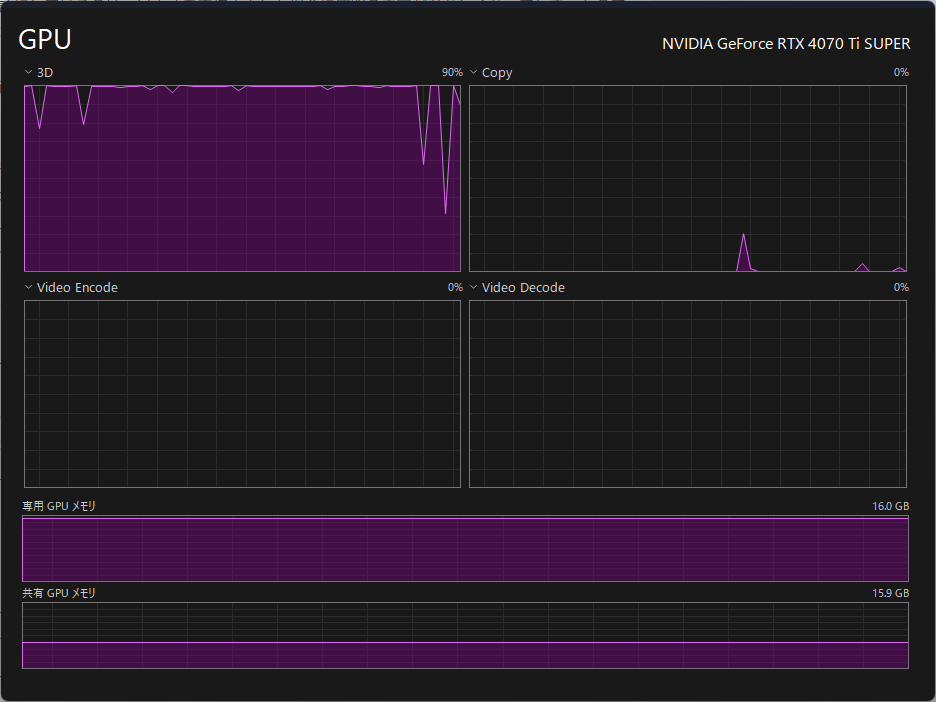
最終的な回答以外が出力される問題
検証はしていませんが、下記の記事に記載されているチャットテンプレート周りが恐らく原因かも。 FoundryLocal自体も頻繁に更新が入っているようなので、このあたりが早く解消されること期待したいと思います。
オンライン上でgpt-ossが試せる環境(無料)
こちらにデモサイトが開設されているので、ローカルで動かせない方は20bと120bの両方のモデルを試すことができます。
こちらでFoundryLocal環境と同じ質問を日本語でするとちゃんと返ってくるので、モデルというより実行環境にも問題がありそうな気がします。
まとめ
- FoundryLocalのインストールからgpt-ossのモデルをロードしてチャットを始めるまで、
PowerShell上で最短2行のコマンドでお手軽実行ができる。 - FoundryLocal自体の修正が頻繁に入っているので、まだ不具合はありそう。
- 現状はWindows + NVIDIA GPU(VRAM 16GB以上)環境に限定される
- そのままチャットしても回答がおかしいケースがある(内容がおかしい、日本語で返答しない等)
とりあえずは、手元のローカル環境で手軽に動くことが確認できて良かったです。
日本語で質問したり回答がおかしい場合が見られたので、ここが解消すればFoundryLocalとgtp-ossの強力でお手軽なローカルLLM環境が構築できそうだと感じました。

Discussion