発生した事象
ZennのAPIを叩いてHTML情報を取得してCSVファイルに入れています。
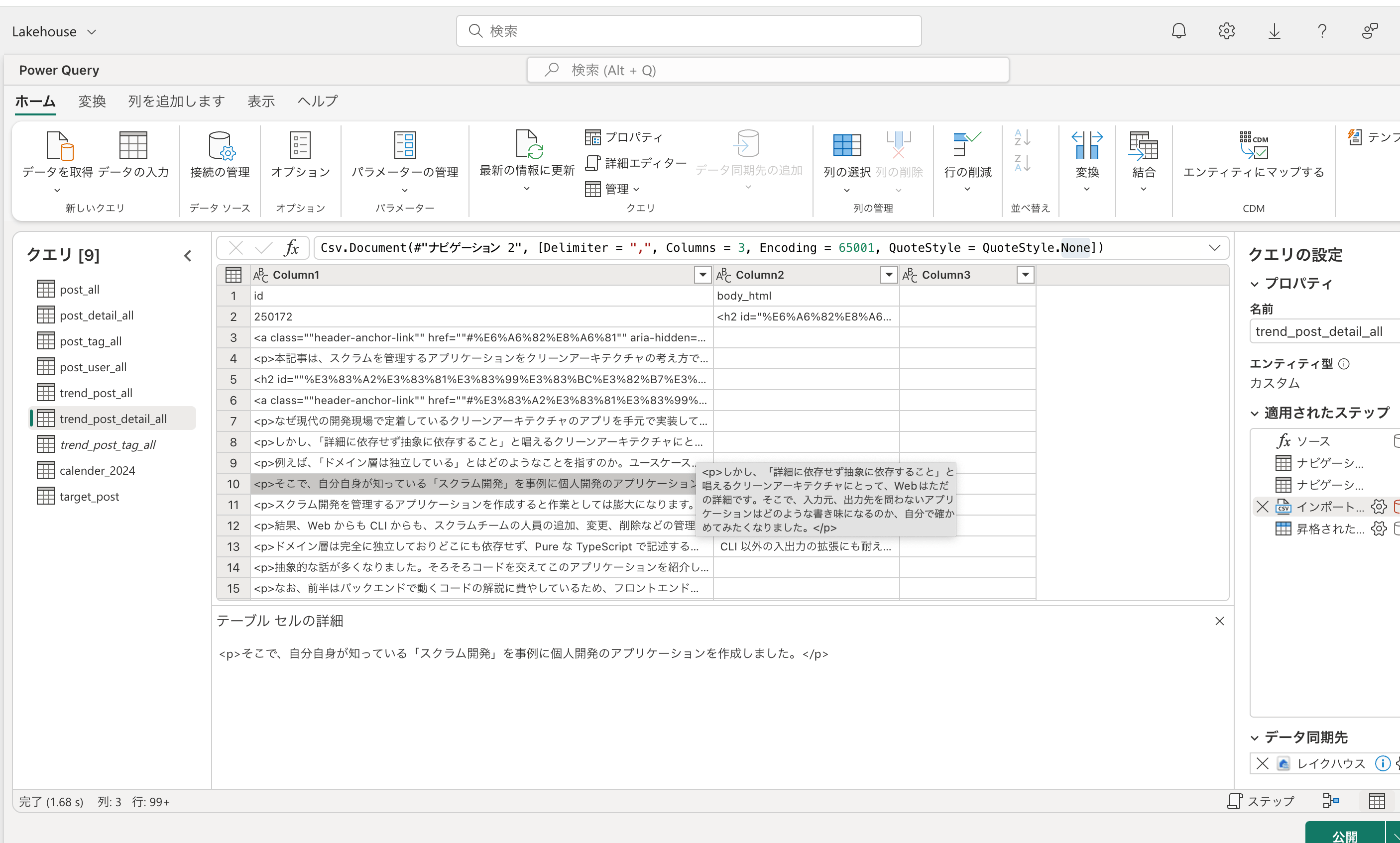
DataflowやNotebookのSparkで読み込む際にHTML内のスペースが新しい列と認識されてしまい、意図したデータ構造になりません。
DataflowでCSVファイルを読み込んだ時
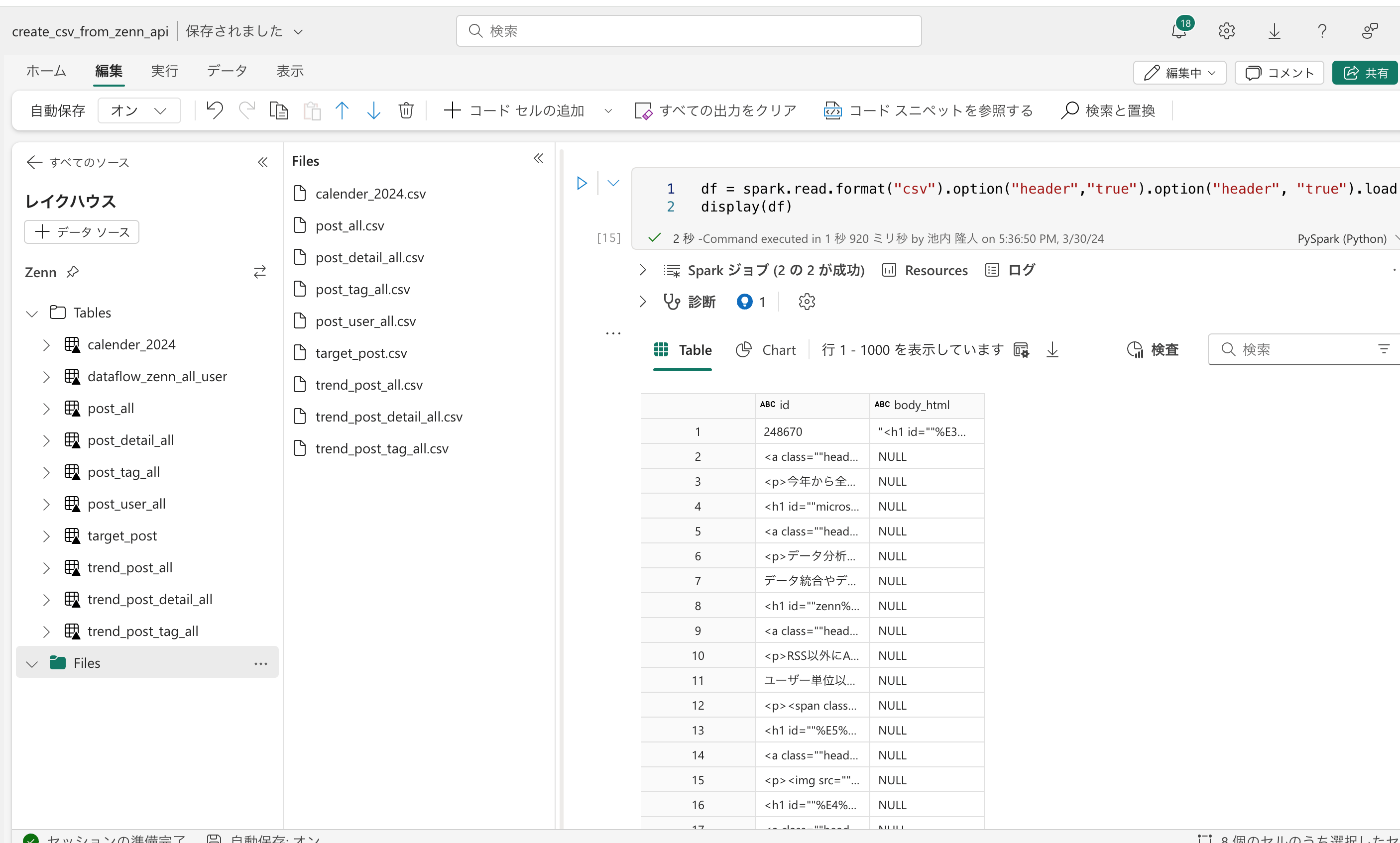
Notebook上でSparkで読み込んだ時
解決方法
1. Dataflow
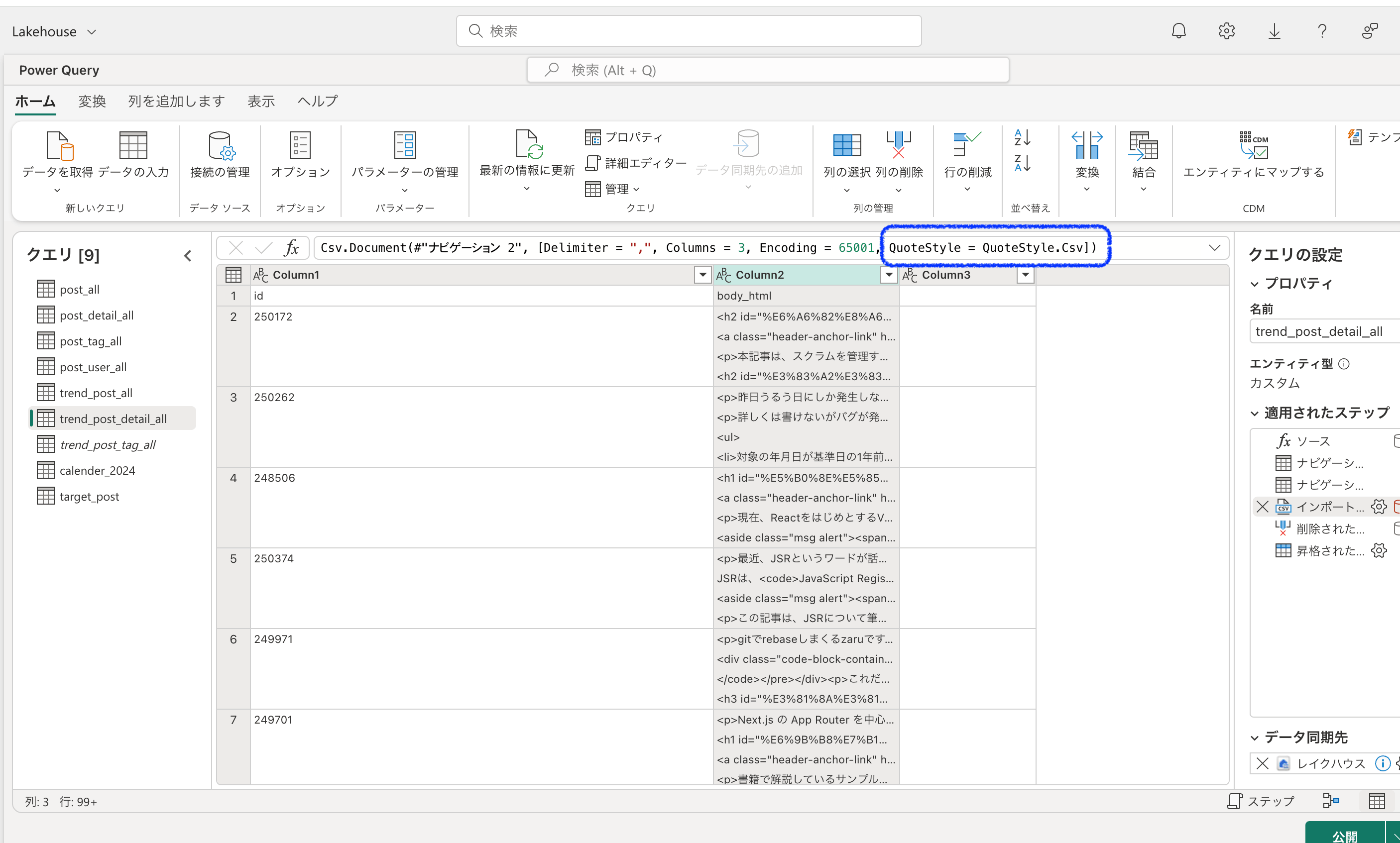
CSVファイルをインポートしている文を修正します。
QuoteStyleをQuoteStyle.NoneからQueteStyle.Csvに変更します。
2. Spark
読み込む際の処理にoptionを追加します。
以下の三つを追加することで、スペースがあっても新しい行にいきません。
.option("multiLine", "true") # 複数行にわたるレコードを許可
.option("quote", "\"") # ダブルクォートで囲まれたフィールドを指定
.option("escape", "\"") # エスケープ文字を指定
全体のコード
df = spark.read.format("csv").option("header","true").option("header", "true").option("multiLine", "true").option("quote", "\"").option("escape", "\"").load("Files/post_detail_all.csv")
display(df)


Discussion