レイクハウスとは?
レイクハウスは、さまざまなツールとフレームワークを使用してそのデータを処理および分析することで、組織が構造化データと非構造化データを 1 か所で格納および管理できるデータ アーキテクチャです。データ エンジニア、データ サイエンティスト、データ アナリストがデータにアクセスして使用するための一元化された場所です。これらのツールとフレームワークには、SQL ベースのクエリと分析のほか、機械学習やその他の高度な分析手法が含まれます。レイクハウスを使用すると、データの一貫性と整合性のための ACID (原子性、一貫性、分離性、持続性) トランザクションが Delta Lake 形式のテーブルを介してサポートされます。
レイクハウスでできること
- Spark エンジンと SQL エンジンを使用して大規模なデータを処理し、機械学習または予測モデリング分析をサポート。
- ローカル ファイル、データベース、API を含め、さまざまなソースから一般的な形式のデータを読み込むこと。
- Microsoft Fabric の Data Factory パイプラインまたはデータフロー (Gen2) を使用してデータ インジェストを自動化すること。
- Azure Data Lake Store Gen2 やレイクハウス自体のストレージの外部にある Microsoft OneLake の場所など、外部ソース内のデータへの Fabric "ショートカット" の作成。
- Lakehouse Explorer を使用すると、ファイル、フォルダー、ショートカット、テーブルを参照し、Fabric プラットフォーム内でその内容を表示。
- レイクハウスにデータを取り込んだ後、ノートブックまたはデータフロー (Gen2) を使用してデータを探索および変換。
- Data Factory パイプラインを使用して Spark、データフロー、およびその他のアクティビティを調整することができ、複雑なデータ変換プロセスを実装。
- データ変換後、SQL を使用してクエリを実行することや、機械学習モデルのトレーニング、リアルタイム分析の実行、Power BI でのレポート開発に使用すること。
- データ分類やアクセス制御などのデータ ガバナンス ポリシーをレイクハウスに適用すること。
レイクハウスを使用するにあたり、知っておいた方がいい用語
Apache Spark
各 Fabric レイクハウスでは、Notebooks または "Spark ジョブ定義" を使用して Spark プールを使用し、Scala、PySpark、または Spark SQL を使用してレイクハウス内のファイルとテーブルのデータを処理できます。
Notebooks
コードを使用して、テーブルやファイルとしてレイクハウスのデータを直接読み取り、変換し、書き込むことができる対話型コーディング インターフェイス。
Spark ジョブ定義
Spark エンジンを使ってレイクハウス内のデータを処理するオンデマンドまたはスケジュールされたスクリプト。
SQL 分析エンドポイント
各レイクハウスには、Transact-SQL ステートメントを実行して、レイクハウス テーブル内のデータのクエリ、フィルター処理、集計、その他の探索を行うことができる SQL 分析エンドポイントが含まれています。
データフロー (Gen2)
データ フローを使用すると、レイクハウスにデータを取り込むだけでなく、データフローを作成して、Power Query を介して後続の変換を実行し、必要に応じて変換されたデータをレイクハウスに戻すことができます。
データ パイプライン
一連のアクティビティ (データフロー、Spark ジョブ、その他の制御フロー ロジックなど) を介してレイクハウス内のデータを操作する複雑なデータ変換ロジックを調整します。
レイクハウスの作成
-
Microsoft Fabricに入る。
https://app.fabric.microsoft.com/home -
"Synapse Data Engineering"をクリックする。

-
「作成」をクリックする。
-
「レイクハウス」をクリックする。
-
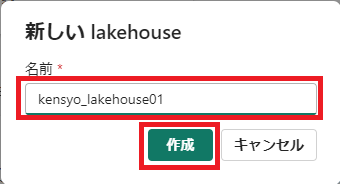
「名前」を入力し、「作成」をクリックする。
-
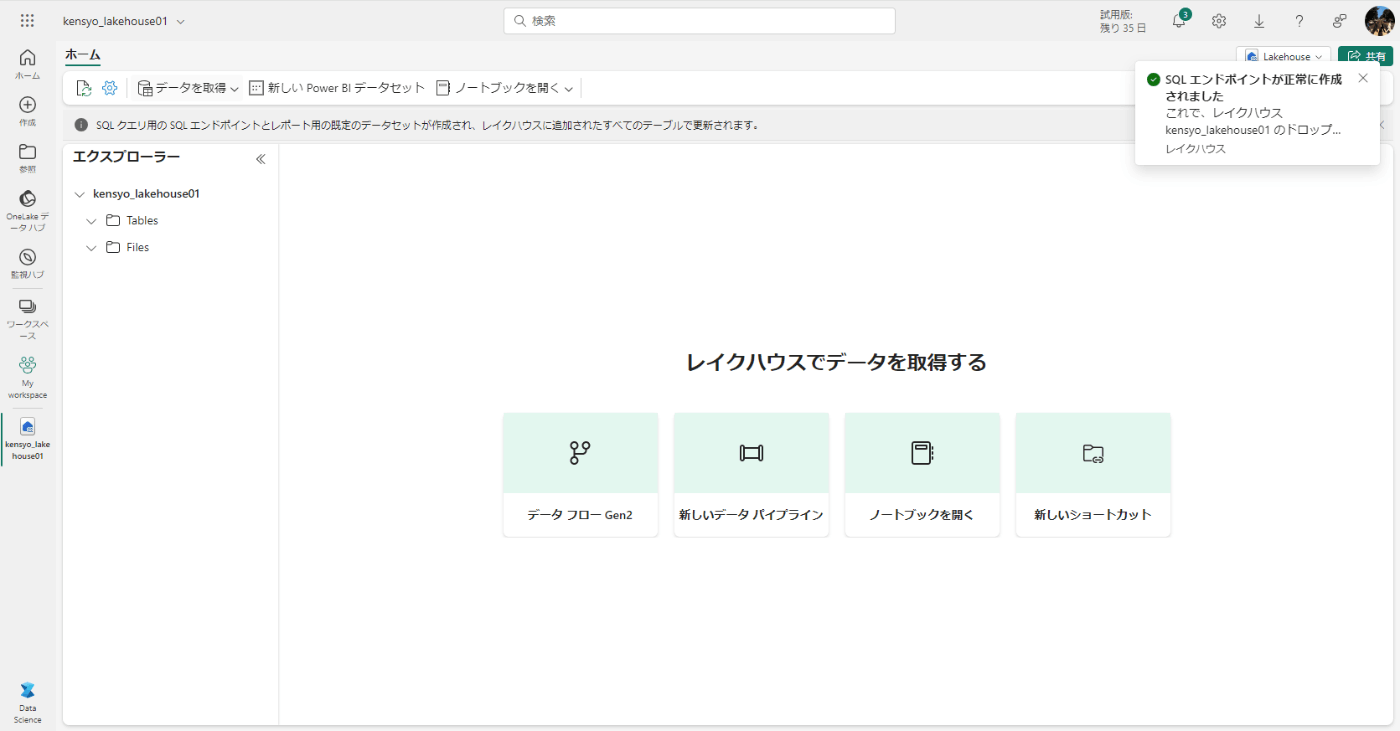
レイクハウスが作成されることを確認する。作成には15秒ほどかかります。
レイクハウスでのファイルの操作
-
レイクハウス エクスプローラー ペインの [Files] フォルダーの [...] メニューをクリックする。
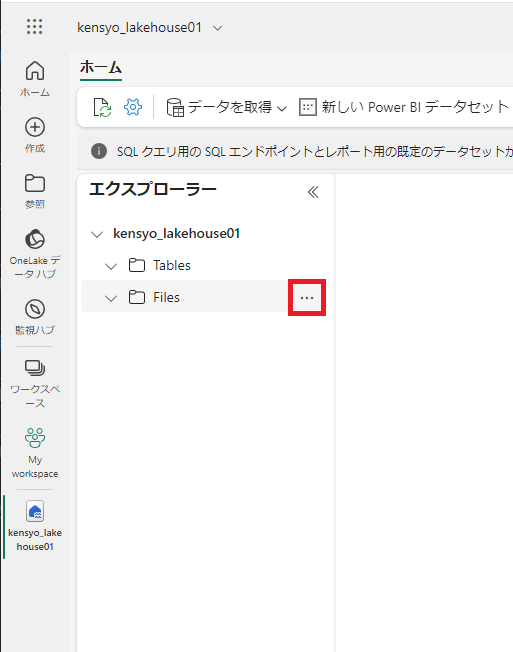
-
[新しいサブフォルダー] をクリックする。
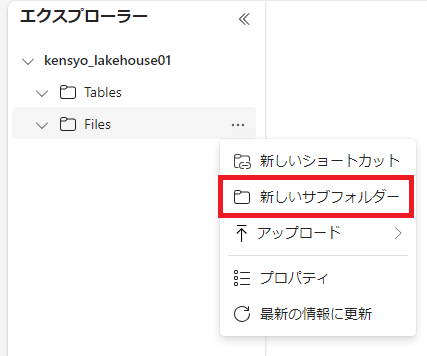
-
「名前」を入力し、「作成」をクリックする。
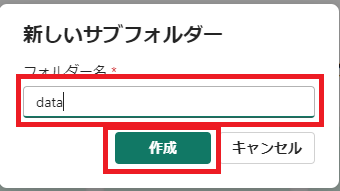
-
サブフォルダーが作成されたことを確認する。
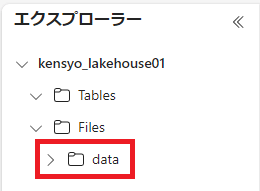
-
新しいデータ フォルダーの [...] メニューで、 [アップロード] と [ファイルのアップロード] を選択する。
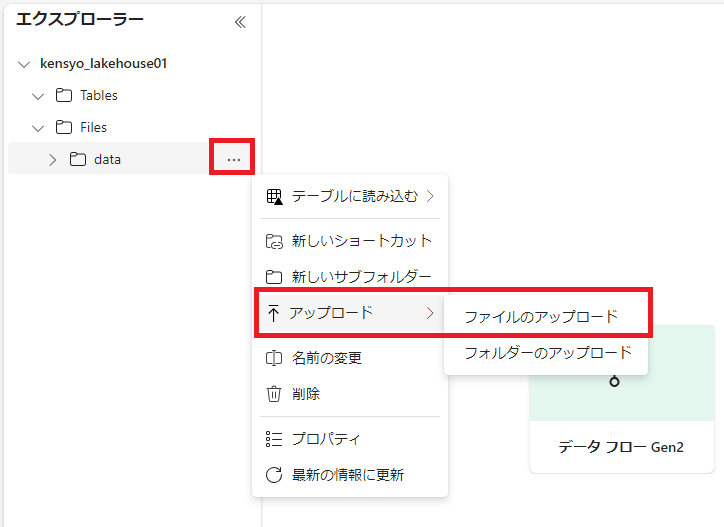
-
[Files/data]の入力欄の箇所をクリックする。
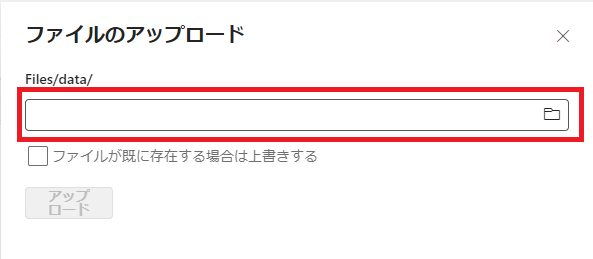
-
データ用のファイルをアップロードする。今回はガンの罹患者のデータを引用しました。(大体、CSVファイルが主だと思います)
https://ganjoho.jp/reg_stat/statistics/data/dl/index.html
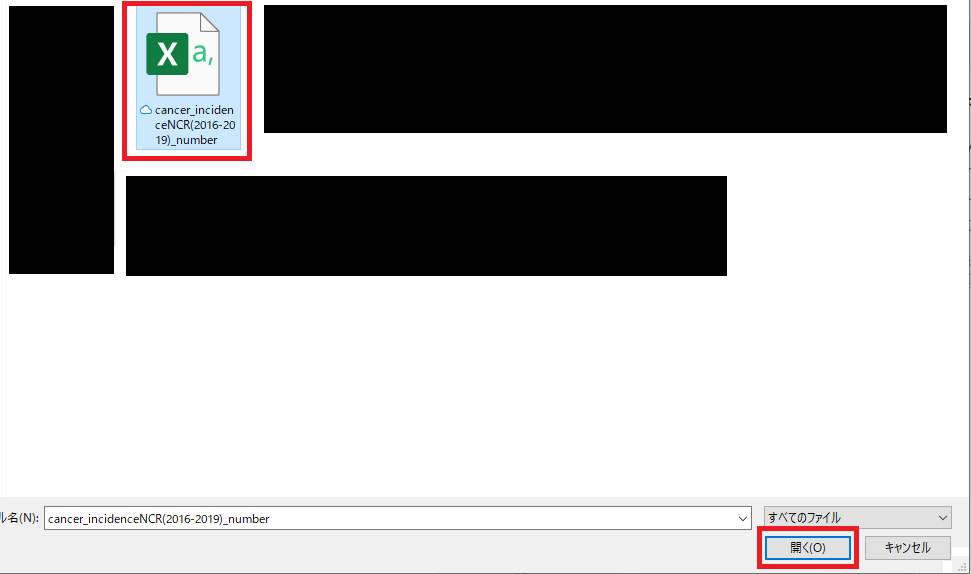
-
ファイルがアップロードされたことを確認し、[アップロード]をクリックする。

-
ファイルがアップロードされたことを確認する。
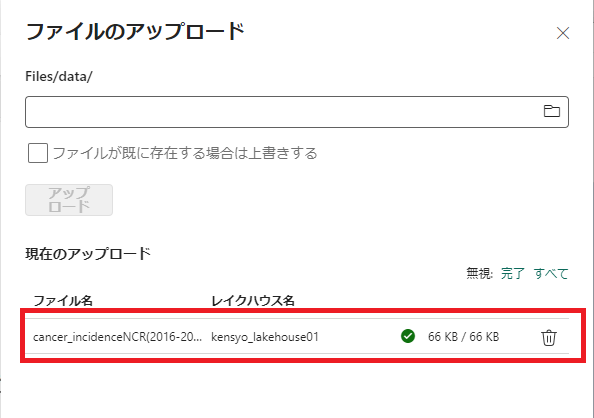
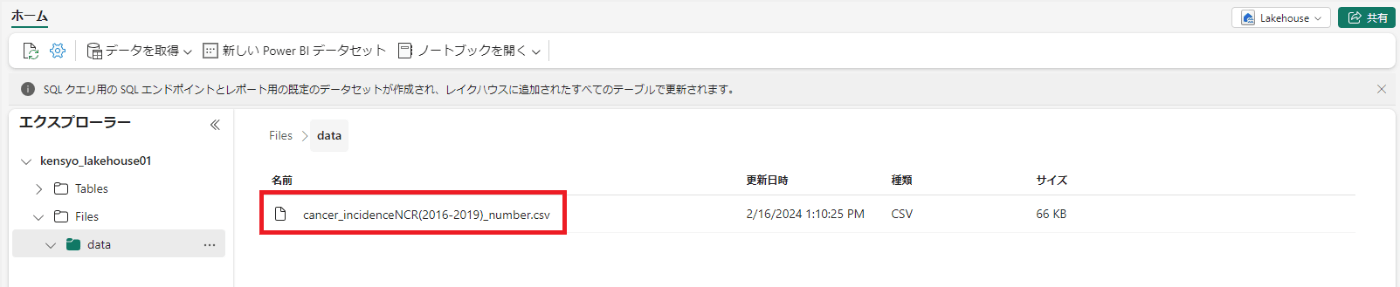
ファイル・データを表に読み込む
1.[ホーム] ページで [ファイル/データ] フォルダーを選択し、そこに含まれるsales.csvファイルを表示します。
2.sales.csv ファイルの [...] メニューで、[テーブルにロード] を選択します。
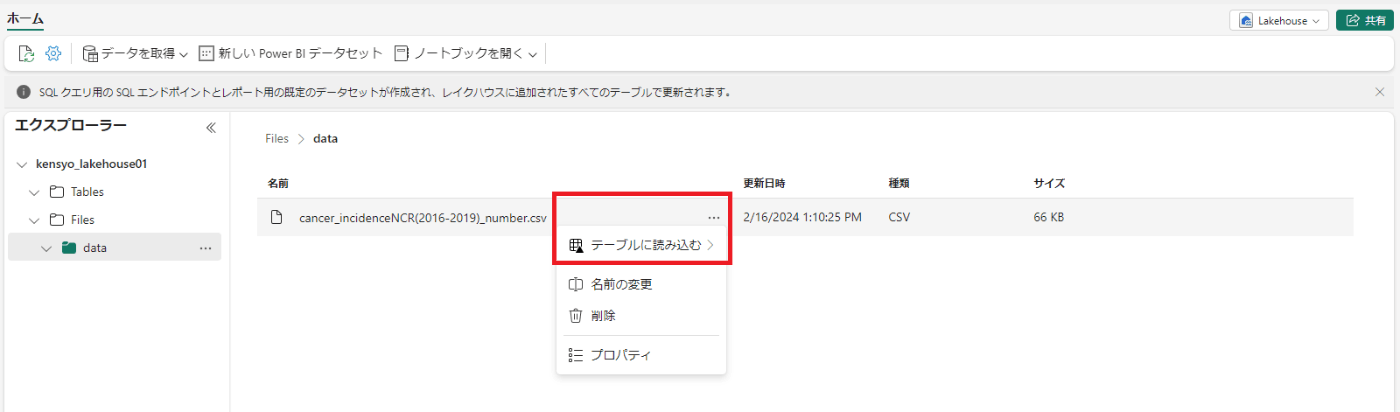
-
[新しいテーブル]をクリックし、[新しいテーブル名]を入力する。
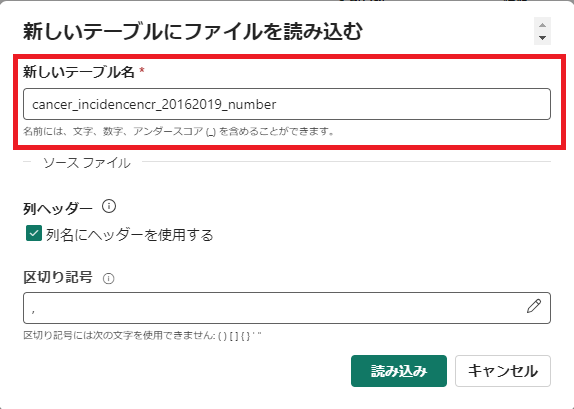
-
[読み込み]をクリックする。(ファイルの容量によると思うが、ここは時間がかかりました。4分ほどかかりました。)
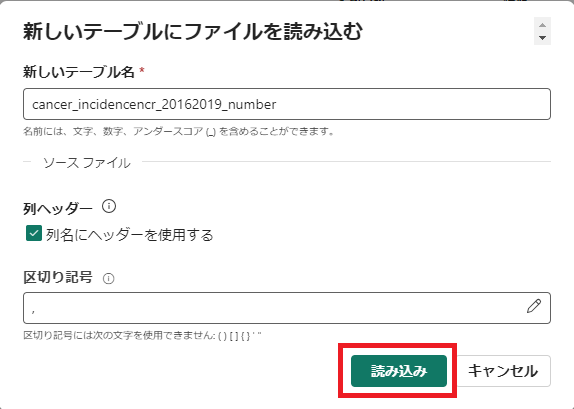
5.レイクハウス エクスプローラー ペインで、データを表示するために作成されたテーブルをクリックする。(ここも表が表示されるまでに時間かかります。これも4分ほどかかりました。)
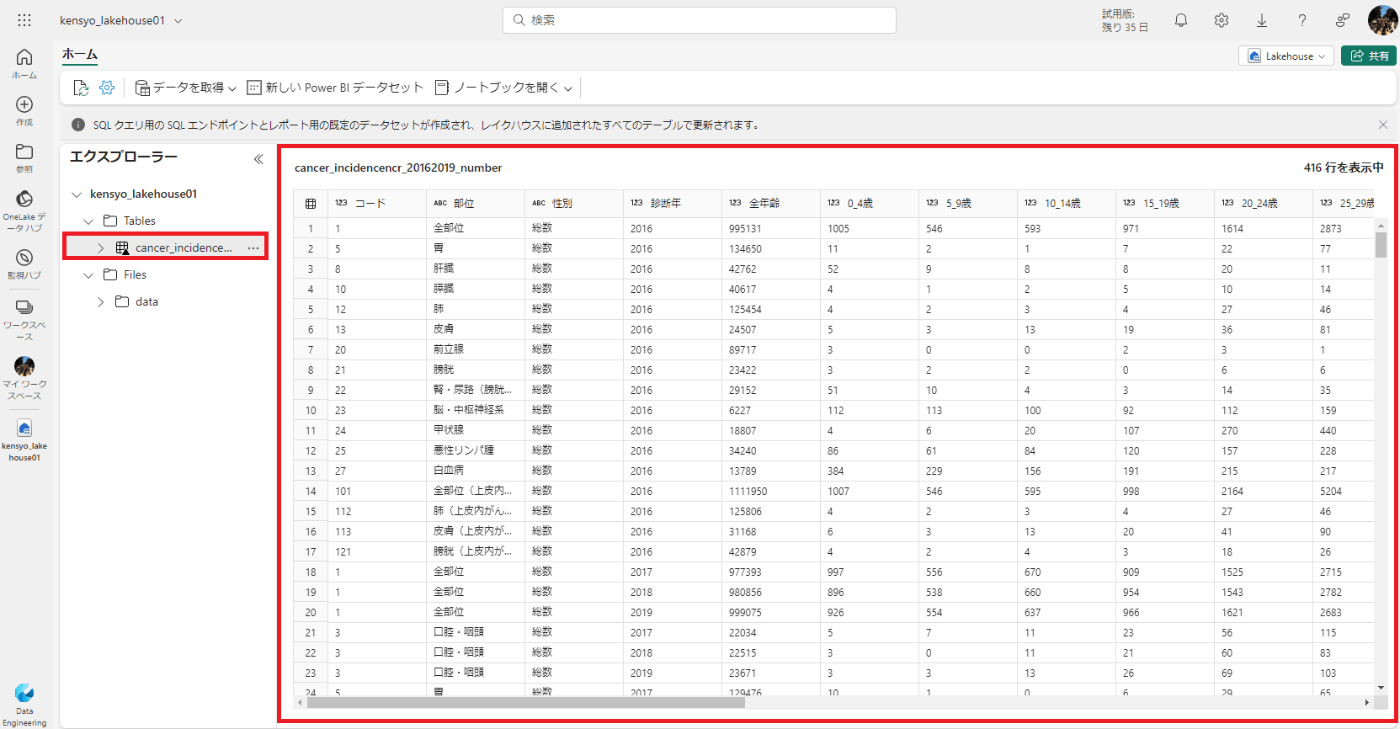
6.sales テーブルの [...] メニューで [ファイルの表示] を選択し、このテーブルの基になるファイルを表示します。

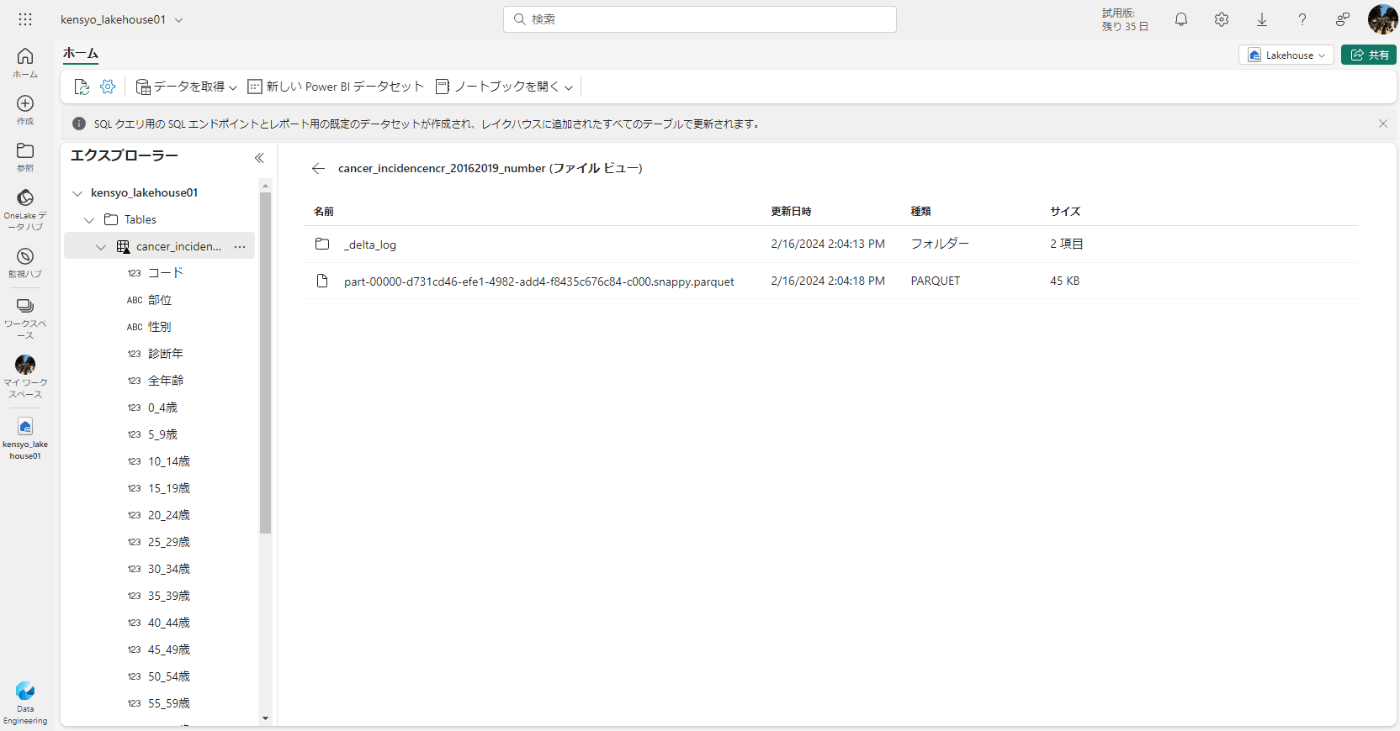
- 差分テーブルのファイルは Parquet 形式で格納され、テーブルに適用されたトランザクションの詳細がログに記録される _delta_log という名前のサブフォルダーが含まれます。
SQLを使用してテーブルをクエリする
-
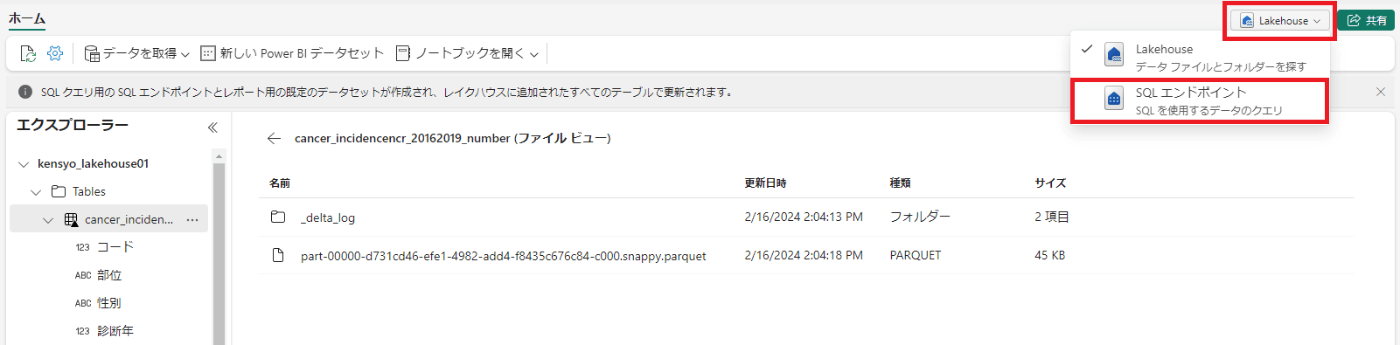
レイクハウスのページの右上で、[Lakehouse]から[SQL エンドポイント]に切り替える。(ここも30秒ほどかかります。)
-
[新規SQLクエリ]をクリックする。

-
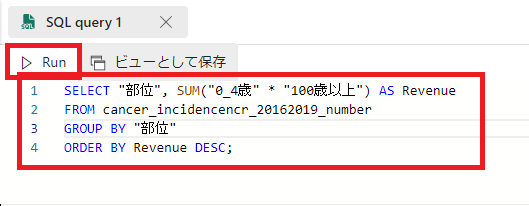
SQL クエリを入力し、[Run]をクリックする。(SQLクエリはあくまで参考例です。今回は0~100歳以上の全体的なガンの部位の総数を出してみました。)
SELECT "参考にしたいデータアイテム", SUM("参考にしたいデータ列" * "参考にしたいデータ列") AS Revenue
FROM "テーブル名(ここは命名したテーブル名)"
GROUP BY "参考にしたいデータアイテム"
ORDER BY Revenue DESC;
- 結果が表示されることを確認する。

ビジュアル クエリを作成する
-
ツールバーで、 [新しいビジュアル クエリ] を選択します。
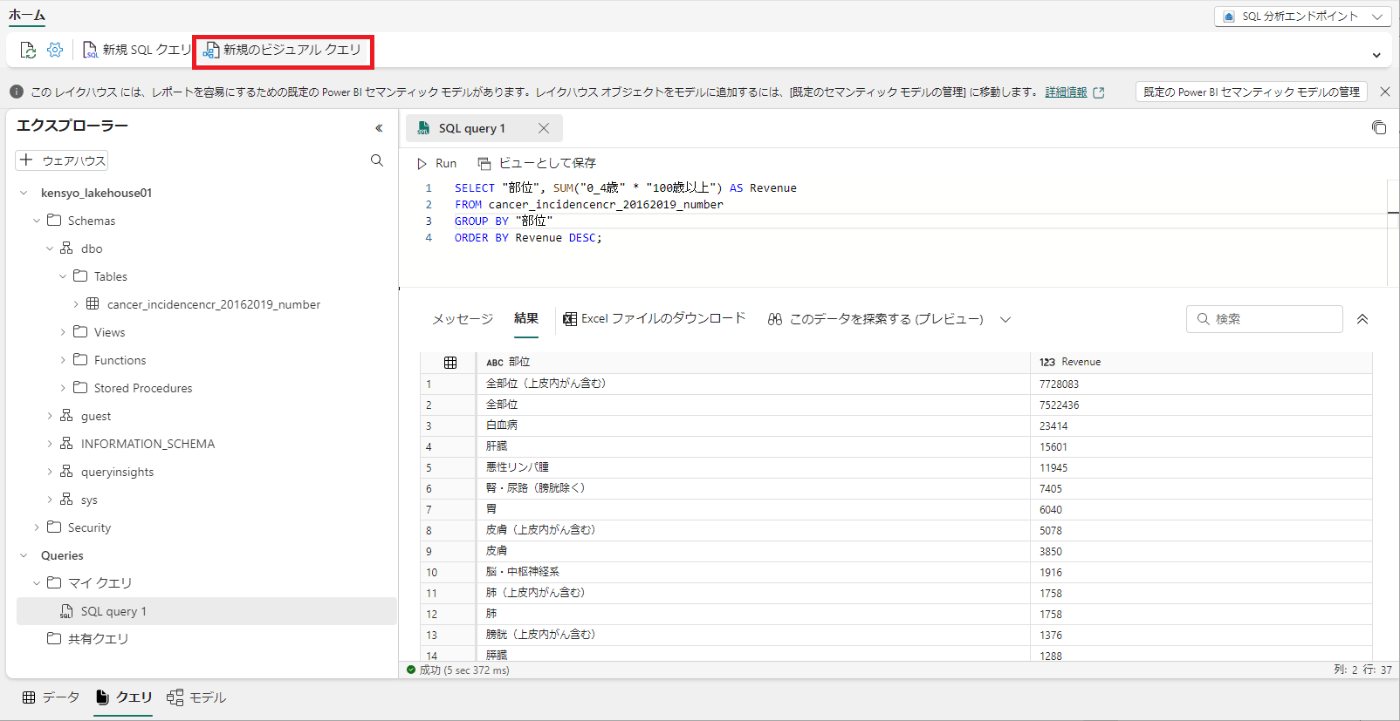
-
開いた新しいビジュアルクエリエディターウィンドウに対象のテーブルをドラッグして、Power Queryを作成する。
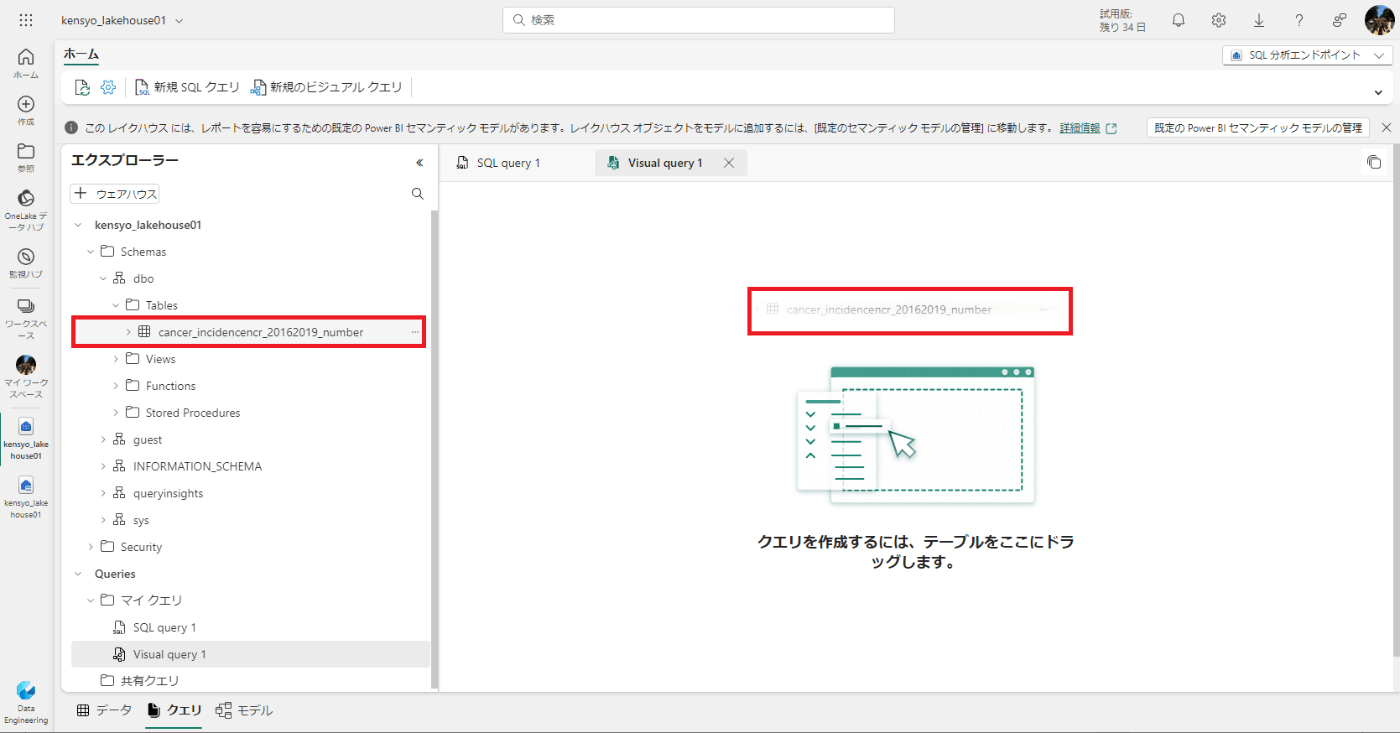
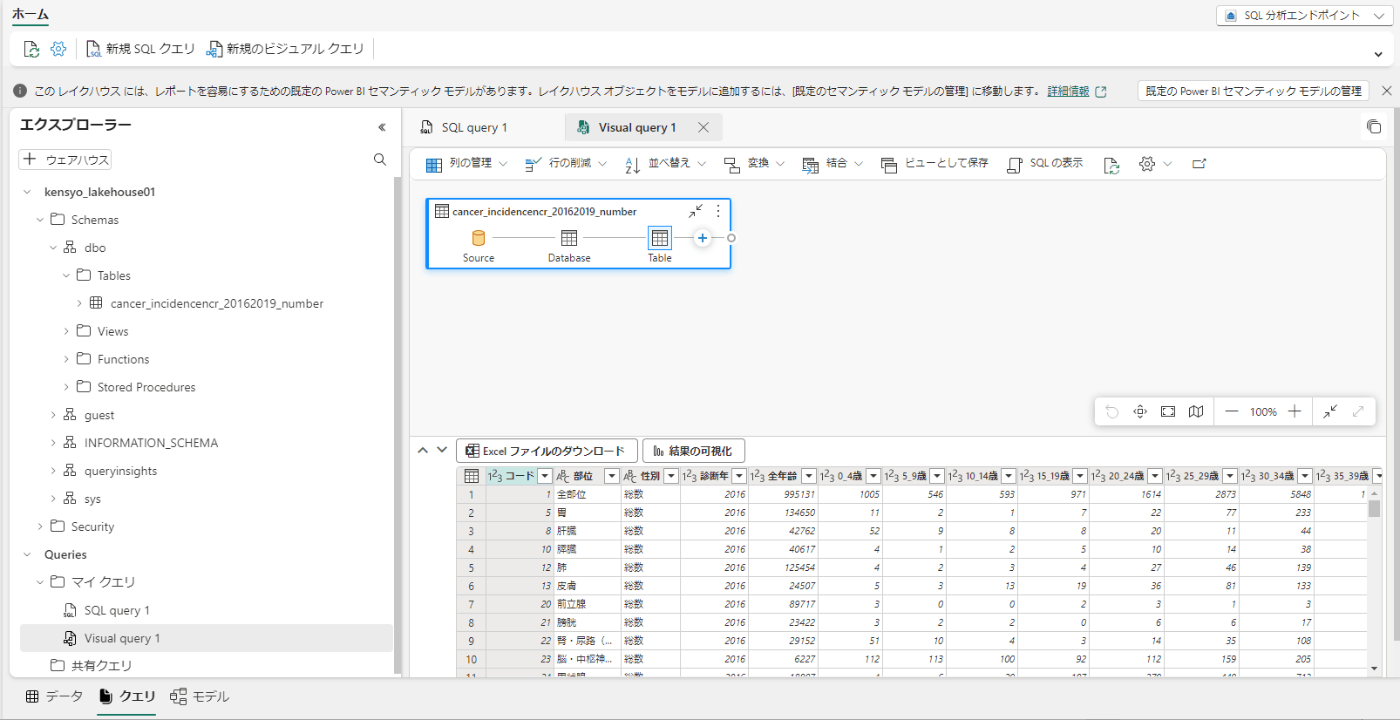
-
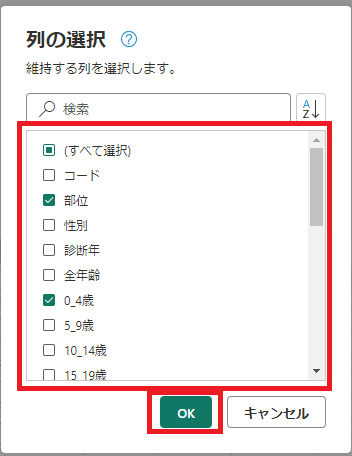
[列の管理] メニューで、[列の選択] を選択する。
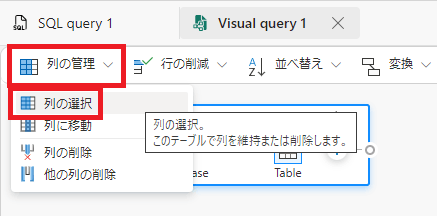
-
表示させたい列にチェックを入れ、[OK]をクリックする。(今回は「部位」と「0_4歳」を選択しました)
-
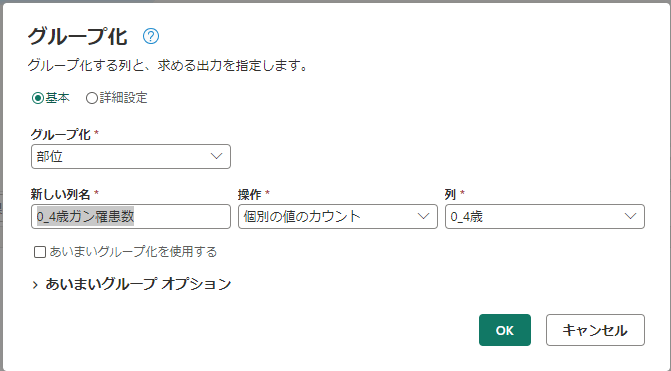
[変換] メニューで [グループ化] を選択する。

-
データをグループ化し、[OK]をクリックする。(あくまで事例です)
- 基本
- グループ化: 部位
- 新しい列名: 0_4歳ガン罹患数
- 操作: 個別の値のカウント
- 列: 0_4歳
- 処理が完了すると、0_4歳ガン罹患数が表示されます。

レポートを作成
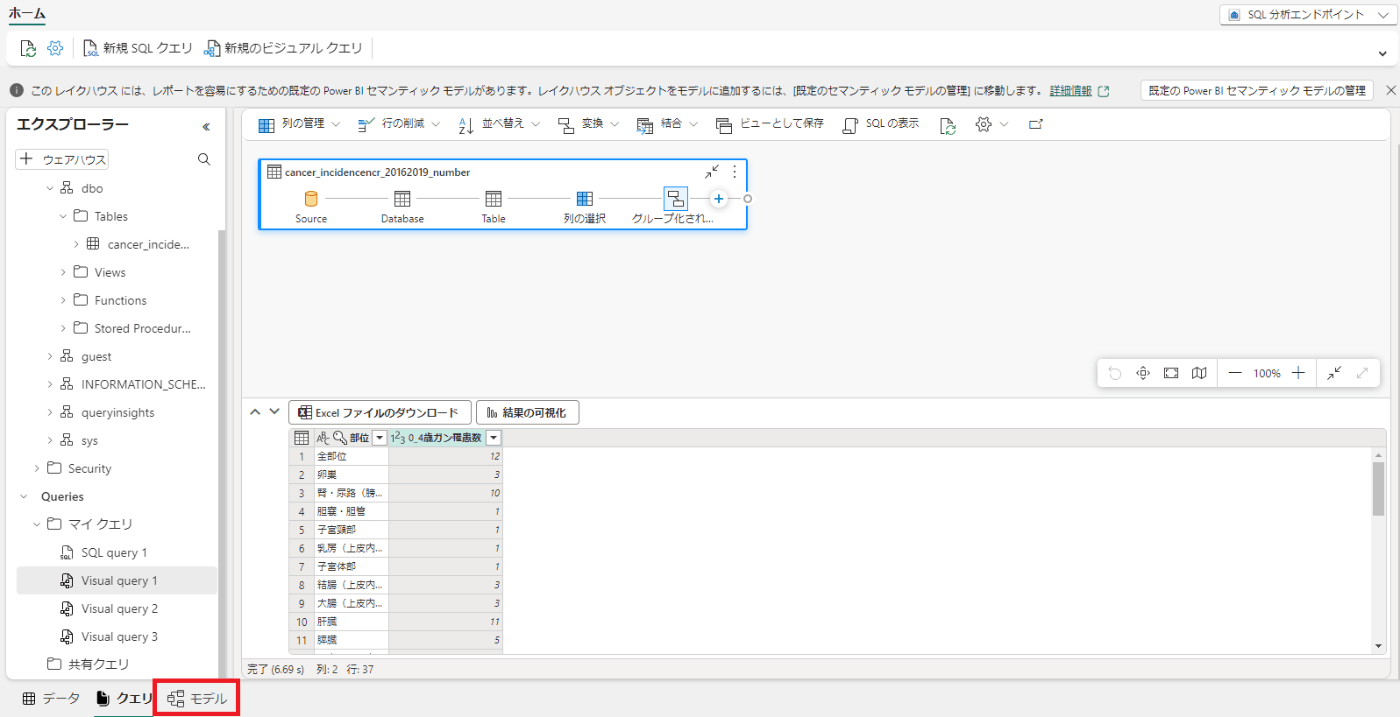
レイクハウス内のテーブルは、Power BI でレポートするための既定のセマンティック モデルに自動的に追加されます。
-
ページの下部にある[モデル]タブをクリックする。
-
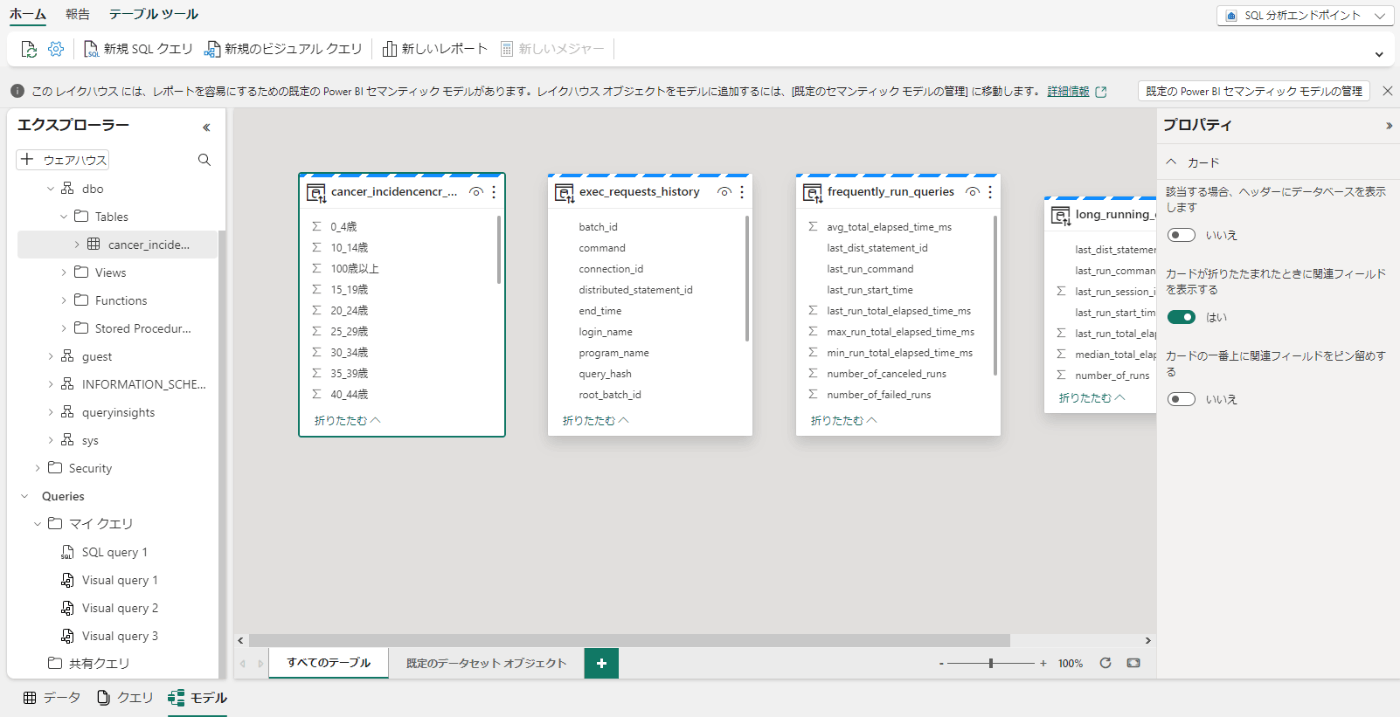
セマンティック・モデルのデータ・モデル・スキーマが表示されることを確認する。
-
[新しいレポート] をクリックする。

-
使用するテーブルに誤りがないことを確認し、[続行]をクリックする。(ここも30秒ほどかかります)

-
画面が切り替わったことを確認する。
-
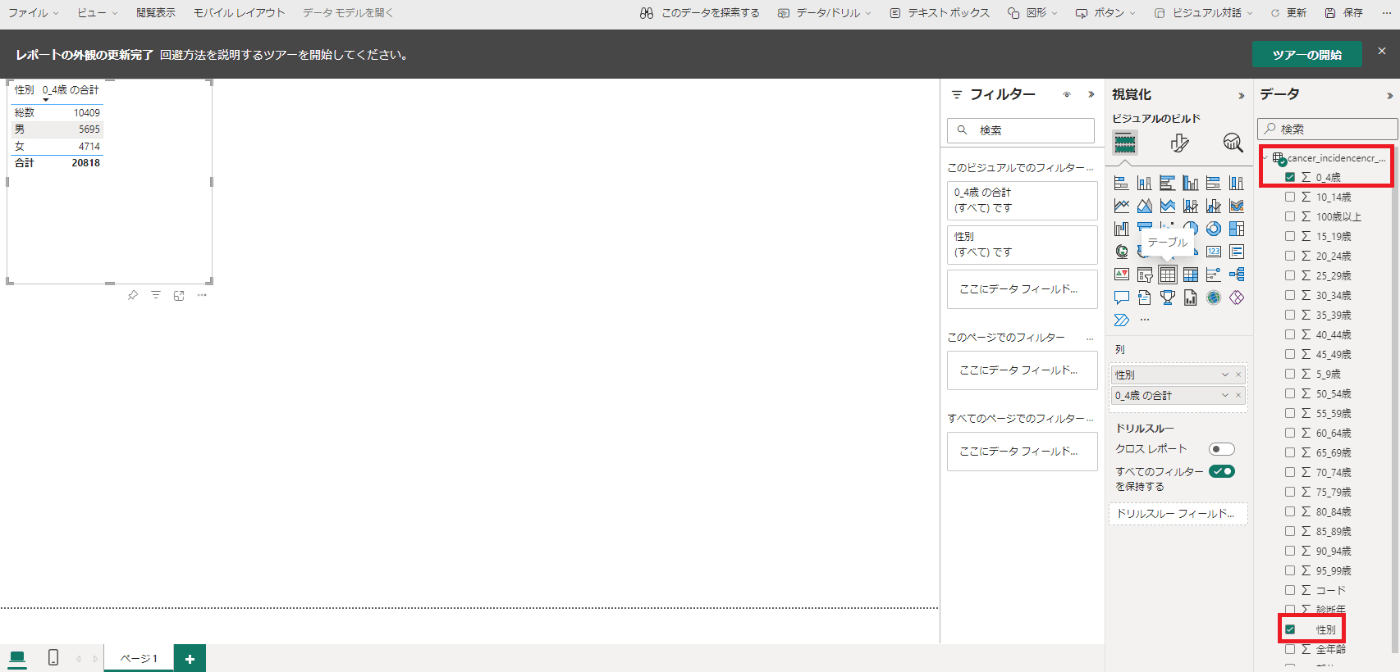
右側の[データ]ペインで、対象のテーブルを展開し、展開したいフィールドを選択します。そうすると、表の視覚化がレポートに追加されます。(今回は性別と「0_4歳」を選択しました。)
-
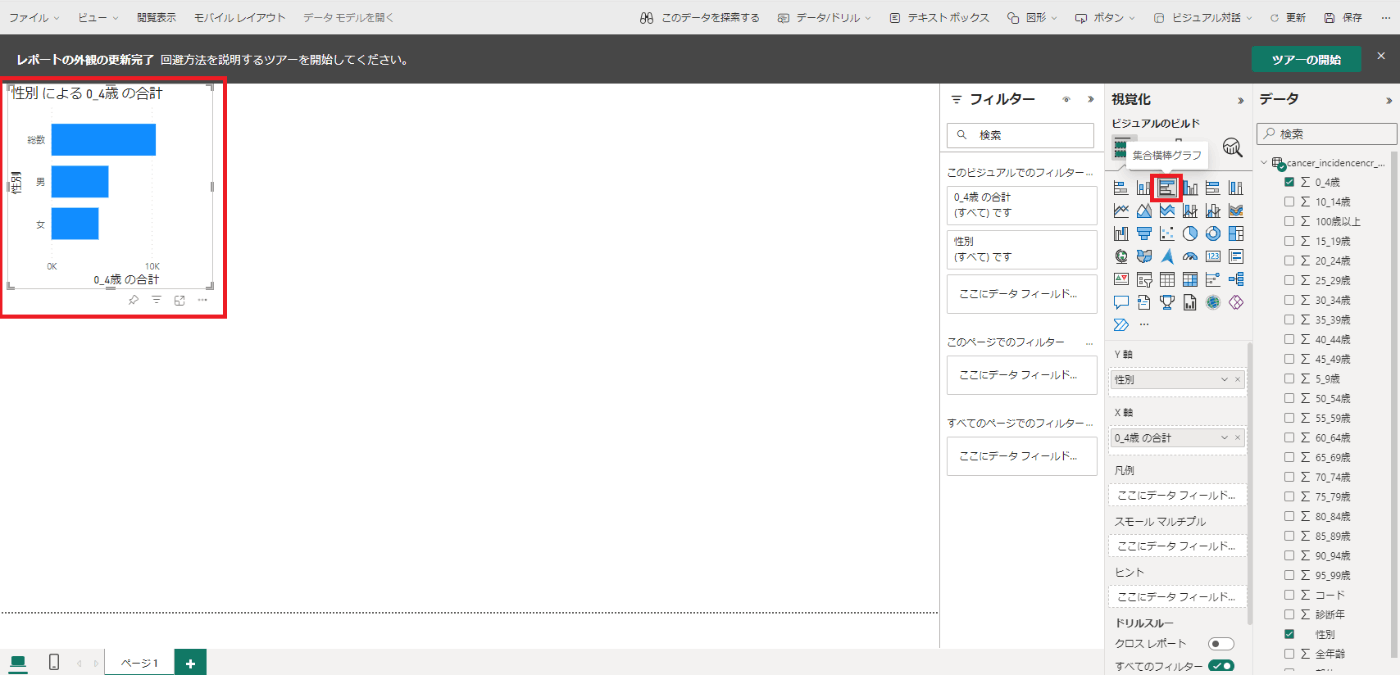
例えば、視覚化の[集合横棒グラフ]をクリックすると、横棒グラフが表示されます。
-
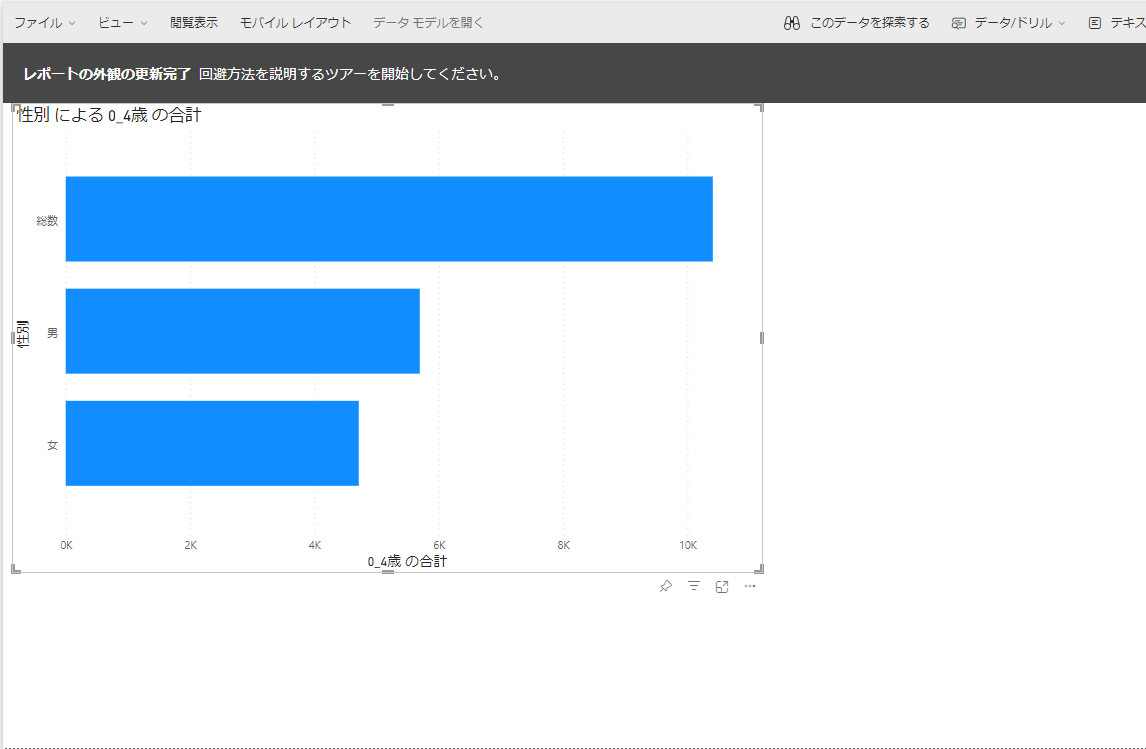
表示を大きくしたり、小さくしたりすることができます。(手順ではないですが)
-
[ファイル] メニューの [保存] を選択します。
-
レポート名を入力し、対象のワークスペースを選択して、[保存]をクリックする。

-
対象のワークスペースを開き、保存されていることを確認する。
使ってみての感想
重たい時もあるが、非常に使いやすいです!
SQLクエリを書く必要があるときはあるので、SQLクエリの知識、勉強は必要だと思いました!
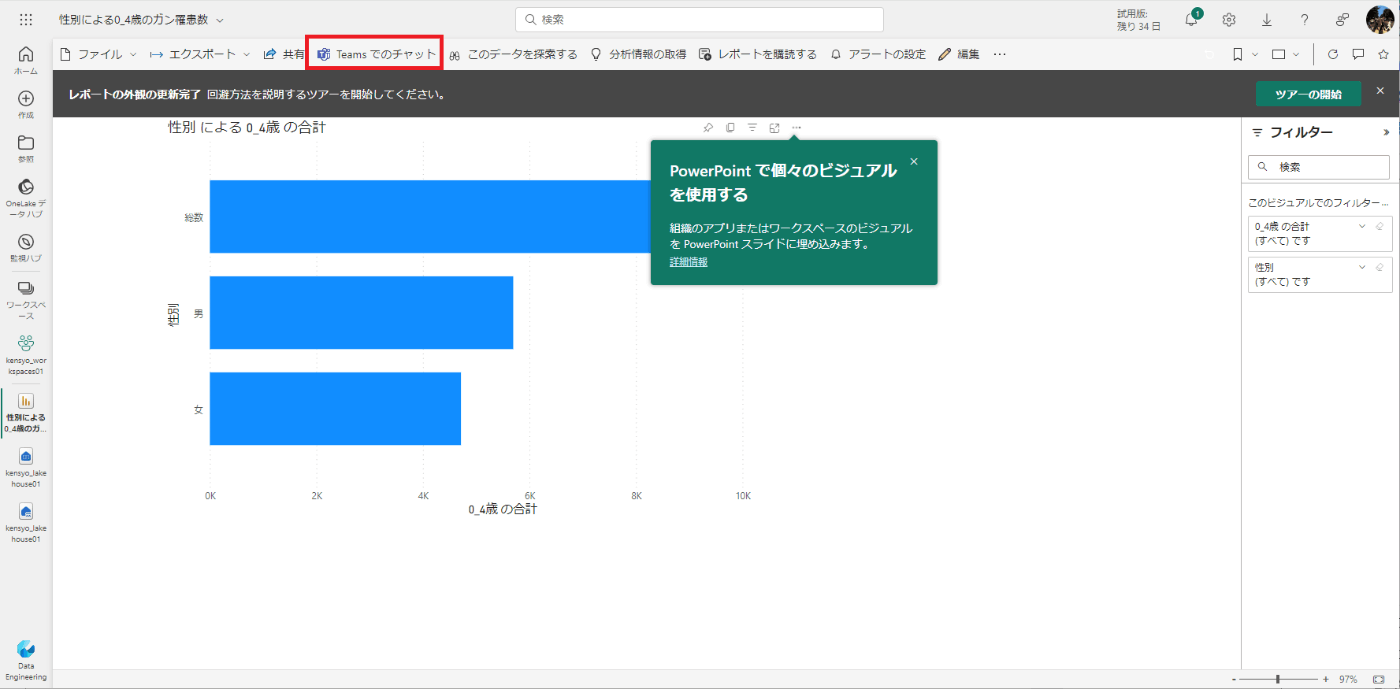
Teamsで共有ができる!!
余談な面はありますが、Power BIでテーブル化やグラフ化したものをTeamsでチーム内のメンバー等に共有することができます!!

Discussion
分かりやすい!いいね!
AOAIのデータソースでつかうとか、Azure AI Studioとの連携とかも書いて欲しいw
AOAIのデータソースでつかうとか、Azure AI Studioとの連携とかも書いて欲しいw
→こちら承知しました!検証で試してみます!
ありがとう!