現状できているとこ
AI Speechでリアルタイムに音声をテキスト変換はできました。
この記事でやっています。
次はそのテキスト内容をGPTに送って、返答を音声で出すところまでやってみます。
ついでにどのくらいでレスポンスが返ってくるのかも計測してみたいと思います。
※検証程度に実装したので、ところどころベストプラクティスじゃないところがありますが、ご了承ください。
Unityのバージョンと使うサービス
- Unity 2022.3.15LTS
- Azure OpenAI Service GPT-3.5
- Azure AI Speech Service
処理の大まかな流れ
- ボタンをクリックすることでAI Speechをストリーミング状態にする(Speech to Text)
- GPTに聞きたい内容を喋る
- 喋り終わったタイミングをAI Speechで検知して文字起こしする + ストップウォッチスタート
- 文字起こしした内容をGPT3.5に送る
- GPT3.5からのレスポンス情報を受け取ってUIに表示 + ストップウォッチストップ
- GPT3.5からのレスポンス情報を音声合成で発話させる(Text to Speech)
- 音声合成からの発話が終わったタイミングでまた喋れる状態にして「2.」を繰り返せるようにする
実装
以下の記事で書いてる内容の箇所(AI Speechでの文字起こし周り)は解説を省きます。
先にコード全体
using System;
using System.Collections;
using System.IO;
using System.Threading.Tasks;
using UnityEngine;
using UnityEngine.UI;
using TMPro;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Audio;
using Azure;
using Azure.AI.OpenAI;
public class AISpeechManager : MonoBehaviour
{
public TMP_Text spokenText;
public TMP_Text gptResponseTime;
public TMP_Text gptResponseText;
private SpeechRecognizer recognizer;
private SpeechConfig speechConfig;
private string recognizeText;
private string responseTextFromGPT;
private string responseTimeFromGPT;
private bool recognitionStarted = false;
private bool isTalking = false;
System.Diagnostics.Stopwatch stopWatch = new System.Diagnostics.Stopwatch();
public async void ButtonClick()
{
if (recognitionStarted)
{
await recognizer.StopContinuousRecognitionAsync().ConfigureAwait(true);
recognitionStarted = false;
spokenText.text = "Disconnected";
Debug.Log("RecognitionStarted: " + recognitionStarted.ToString());
}
else
{
await recognizer.StartContinuousRecognitionAsync().ConfigureAwait(false);
recognitionStarted = true;
Debug.Log("RecognitionStarted: " + recognitionStarted.ToString());
}
}
private async void AskOpenAI(object sender, SpeechRecognitionEventArgs e)
{
try
{
if (isTalking) return;
if (stopWatch.ElapsedMilliseconds == 0)
{
stopWatch.Start();
} else
{
stopWatch.Restart();
}
recognizeText = e.Result.Text;
isTalking = true;
Debug.Log("RecognizedHandler: " + recognizeText);
OpenAIClient client = new OpenAIClient(new Uri(<your endpoint>), new AzureKeyCredential(<your key>));
var chatCompletionsOptions = new ChatCompletionsOptions()
{
DeploymentName = "<your deployment name>",
Messages =
{
new ChatMessage(ChatRole.User, recognizeText),
},
MaxTokens = 300
};
Response<ChatCompletions> response = client.GetChatCompletions(chatCompletionsOptions);
stopWatch.Stop();
responseTimeFromGPT = $"GPT Reponse.. {stopWatch.ElapsedMilliseconds}ms";
responseTextFromGPT = response.Value.Choices[0].Message.Content;
using (var speechSynthesizer = new SpeechSynthesizer(speechConfig))
{
var speechSynthesisResult = await speechSynthesizer.SpeakTextAsync(responseTextFromGPT);
isTalking = false;
}
}
catch (Exception ex)
{
Debug.Log(ex.Message);
}
}
void Start()
{
speechConfig = SpeechConfig.FromSubscription("<your subscription>", "<your region>");
speechConfig.SpeechSynthesisVoiceName = "ja-JP-NanamiNeural";
speechConfig.SpeechRecognitionLanguage = "ja-JP";
AudioConfig audioConfig = AudioConfig.FromDefaultMicrophoneInput();
recognizer = new SpeechRecognizer(speechConfig, audioConfig);
recognizer.Recognizing += (s, e) => {
recognizeText = e.Result.Text;
Debug.Log("RecognizingHandler: " + recognizeText);
};
recognizer.Recognized += AskOpenAI;
recognizer.Canceled += (s, e) => {
recognizeText = e.ErrorDetails.ToString();
Debug.Log("CanceledHandler: " + recognizeText);
};
}
void OnDestroy()
{
recognizer.Recognized -= AskOpenAI;
recognizer.Dispose();
#if UNITY_EDITOR
UnityEditor.EditorApplication.isPlaying = false;
#endif
}
void Update()
{
if (recognitionStarted)
{
spokenText.text = recognizeText;
gptResponseText.text = responseTextFromGPT;
gptResponseTime.text = responseTimeFromGPT;
}
}
}
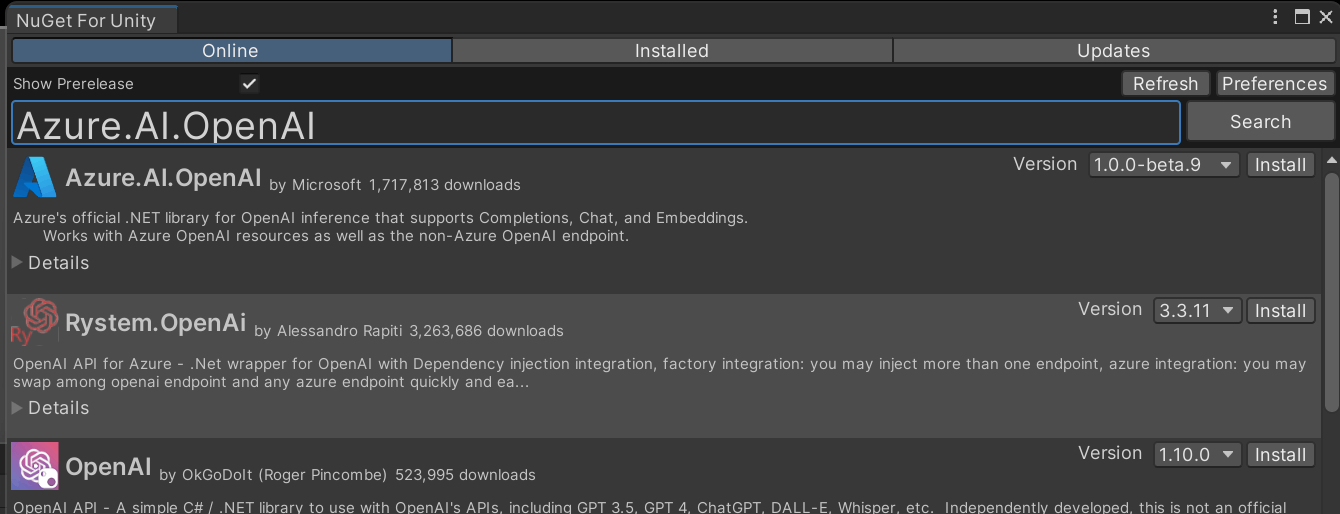
1. Azure.AI.OpenAIをプロジェクトに導入
※注意:Nugetで左上の「Show Prerelease」にチェックをつけないと表示されないのでチェックするように。
2. AI Speechの定義
Start関数内でspeechConfigを初期化します。
private SpeechConfig speechConfig;
void Start() {
speechConfig = SpeechConfig.FromSubscription("<your subscription>", "<your region>");
speechConfig.SpeechRecognitionLanguage = "ja-JP";
AudioConfig audioConfig = AudioConfig.FromDefaultMicrophoneInput();
recognizer = new SpeechRecognizer(speechConfig, audioConfig);
// ユーザーが喋ってるタイミングでリアルタイムに文字起こしをするイベントハンドラー
recognizer.Recognizing += (s, e) => {
recognizeText = e.Result.Text;
Debug.Log("RecognizingHandler: " + recognizeText);
};
// ユーザーが喋り終わったタイミングで実行されるイベントハンドラー
recognizer.Recognized += AskOpenAI;
recognizer.Canceled += (s, e) => {
recognizeText = e.ErrorDetails.ToString();
Debug.Log("CanceledHandler: " + recognizeText);
};
}
3. 文字起こし後の処理とGPTの定義
ユーザーが喋り終わったタイミングでAskOpenAI関数が実行されるようになってるので、テキストを受け取ってGPTにリクエストを投げます。
private async void AskOpenAI(object sender, SpeechRecognitionEventArgs e)
{
try
{
// ユーザーがしゃべった内容をテキスト化
recognizeText = e.Result.Text;
Debug.Log("RecognizedHandler: " + recognizeText);
OpenAIClient client = new OpenAIClient(new Uri(<your endpoint>), new AzureKeyCredential(<your key>));
var chatCompletionsOptions = new ChatCompletionsOptions()
{
DeploymentName = "<your deployment name>",
Messages =
{
new ChatMessage(ChatRole.User, recognizeText),
},
MaxTokens = 300
};
Response<ChatCompletions> response = client.GetChatCompletions(chatCompletionsOptions);
// GPTから返ってきたテキストを変数に入れる
responseTextFromGPT = response.Value.Choices[0].Message.Content;
}
catch (Exception ex)
{
Debug.Log(ex.Message);
}
}
4. GPTからのレスポンスを音声として出力する
音声合成用に追加で必要な定義があって、SpeechSynthesisVoiceNameを指定しないといけないので、Start関数内に追記します。
void Start() {
speechConfig = SpeechConfig.FromSubscription("<your subscription>", "<your region>");
speechConfig.SpeechRecognitionLanguage = "ja-JP";
// テキストから音声への変換を行う際に使用する音声(ボイス)を指定するためのパラメータ
speechConfig.SpeechSynthesisVoiceName = "ja-JP-NanamiNeural";
...
次にAskOpenAI関数内に音声出力する処理を追記します。
また、GPTにリクエスト~音声出力の間は新しいリクエストを受け付けたくないので、isTalkingフラグを使って制御します。
private bool isTalking = false;
private async void AskOpenAI(object sender, SpeechRecognitionEventArgs e)
{
try
{
// true(つまりGPTにリクエストを投げて音声で出力中)は処理をしないようにする
if (isTalking) return;
recognizeText = e.Result.Text;
// trueにして、ユーザーが喋ってもGPTにリクエストを投げないようにする
isTalking = true;
Debug.Log("RecognizedHandler: " + recognizeText);
OpenAIClient client = new OpenAIClient(new Uri(<your endpoint>), new AzureKeyCredential(<your key>));
....
responseTimeFromGPT = $"GPT Reponse.. {stopWatch.ElapsedMilliseconds}ms";
responseTextFromGPT = response.Value.Choices[0].Message.Content;
using (var speechSynthesizer = new SpeechSynthesizer(speechConfig))
{
var speechSynthesisResult = await speechSynthesizer.SpeakTextAsync(responseTextFromGPT);
// 音声出力が終わったらfalseに戻して、再びGPTにリクエストを投げれるようにする
isTalking = false;
}
}
5. GPTからのレスポンス時間を計測
最後にレスポンス時間を計測できるようにします。
喋り終わったタイミングでストップウォッチを開始して、GPTからレスポンスが返ってくるまでを計測します。
System.Diagnostics.Stopwatch stopWatch = new System.Diagnostics.Stopwatch();
...
private async void AskOpenAI(object sender, SpeechRecognitionEventArgs e)
{
try
{
if (isTalking) return;
// 初めの一回はStartメソッドを実行
if (stopWatch.ElapsedMilliseconds == 0)
{
stopWatch.Start();
} else
{
// 2回目以降はRestartメソッドを実行
stopWatch.Restart();
}
....
Response<ChatCompletions> response = client.GetChatCompletions(chatCompletionsOptions);
// GPTからレスポンスが来たらストップウォッチを止める
stopWatch.Stop();
// 計測時間を変数に格納
responseTimeFromGPT = $"GPT Reponse.. {stopWatch.ElapsedMilliseconds}ms";
....
6. AI Speechのストリーミングを開始・終了する関数
public async void ButtonClick()
{
// ストリーミング中は終了する
if (recognitionStarted)
{
await recognizer.StopContinuousRecognitionAsync().ConfigureAwait(true);
recognitionStarted = false;
spokenText.text = "Disconnected";
Debug.Log("RecognitionStarted: " + recognitionStarted.ToString());
}
// ストリーミングをしてない時は開始する
else
{
await recognizer.StartContinuousRecognitionAsync().ConfigureAwait(false);
recognitionStarted = true;
Debug.Log("RecognitionStarted: " + recognitionStarted.ToString());
}
}
7. UI上に反映
ストリーミング中はUIに反映されるようにします。
Update関数内に追記します。
// 文字起こしされたテキストを表示
public TMP_Text spokenText;
// GPTからのレスポンス時間を表示
public TMP_Text gptResponseTime;
// GPTからのレスポンス内容を表示
public TMP_Text gptResponseText;
void Update()
{
if (recognitionStarted)
{
spokenText.text = recognizeText;
gptResponseText.text = responseTextFromGPT;
gptResponseTime.text = responseTimeFromGPT;
}
}
8. UIの用意
以下の四つがあれば大丈夫です。
- ストリーミングを開始するボタン
- AI Speechでの文字起こしを表示するテキスト
- GPTからのレスポンス時間を表示するテキスト
- GPTからのレスポンス内容を表示するテキスト
AISpeechManagerのヒエラルキーでそれぞれ紐づけすることを忘れずに。
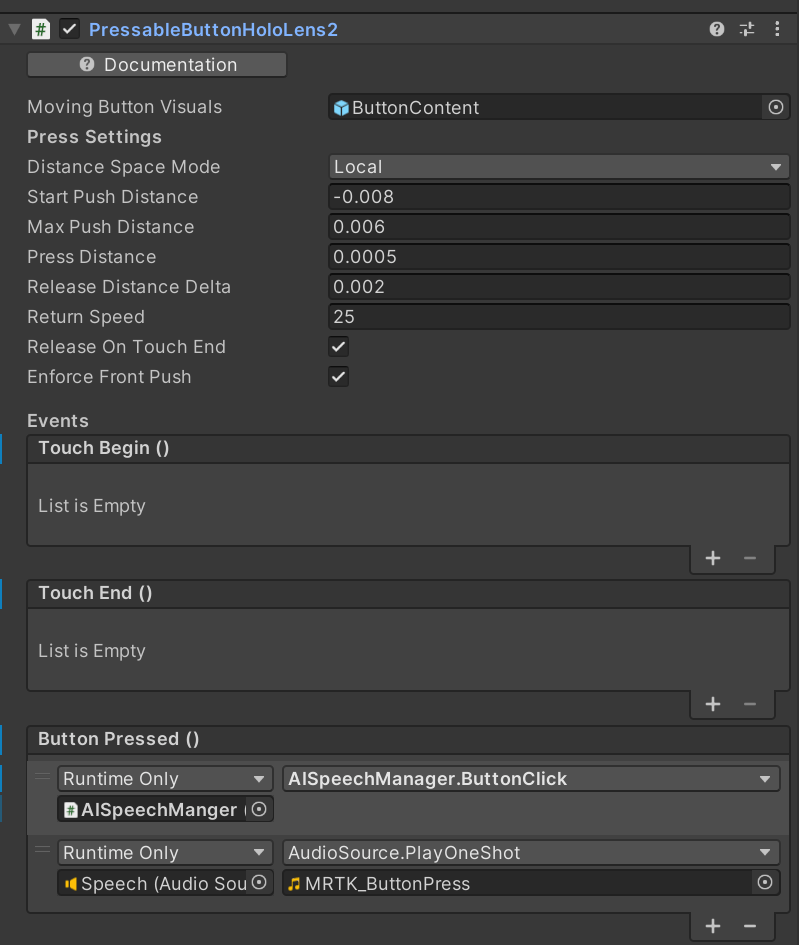
あとは用意したボタンのクリック時にButtonClick関数をするようにすればOKです。
検証
GPTからのレスポンスは1秒もかからないくらいです。
レスポンス内容を音声で出力するところが若干時間がかかるので、そこはUIを工夫して体感で遅延を感じないようにしようと思います。
あとはGPT3.5と4での比較も気になるので今度検証してみます。

Discussion
いいね!思ったよりスムーズ!
RAGとかするともう少し遅くなりそうっすね。