はじめに
FabricのNotebookを触ってみました。
適当にいじって遊んでいたらData Wranglerの機能を見つけたのでご紹介します。
ちなみにWranglerとは「口論者」「数学の学位試験の一級合格者」「カウボーイ」という意味があるようです。
Data Wranglerとはデータを扱える一級者てきな意味合いなのでしょうか…
前提
こちらの記事を参考にNotebookで適当なテストデータを作成しています。
10個前後のデータがあれば大丈夫です。
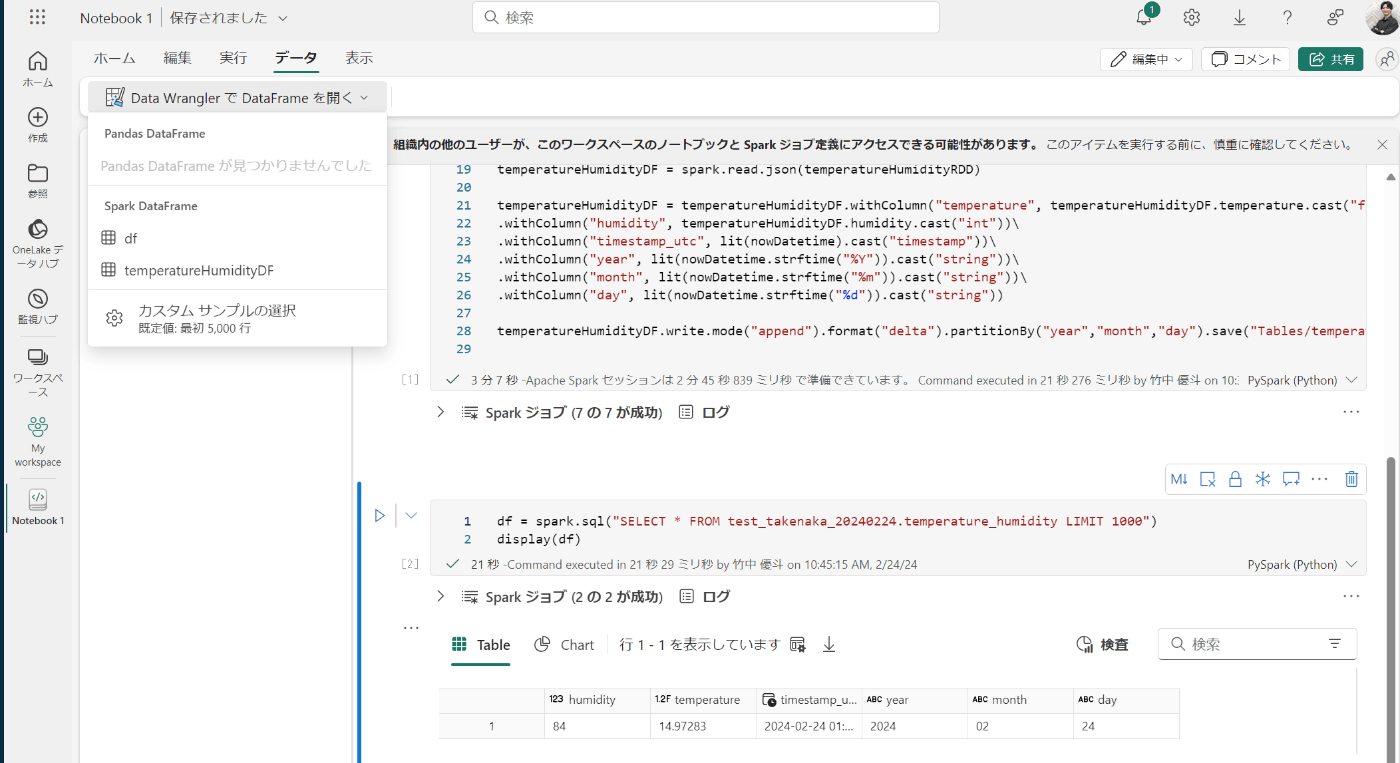
Data Wranglerを選択
データタブから先程作成したDataFrameを選択します。
(画像の場合はdfを選択しました。なぜか紹介している記事で作ったものだとデータが入ってなかった)

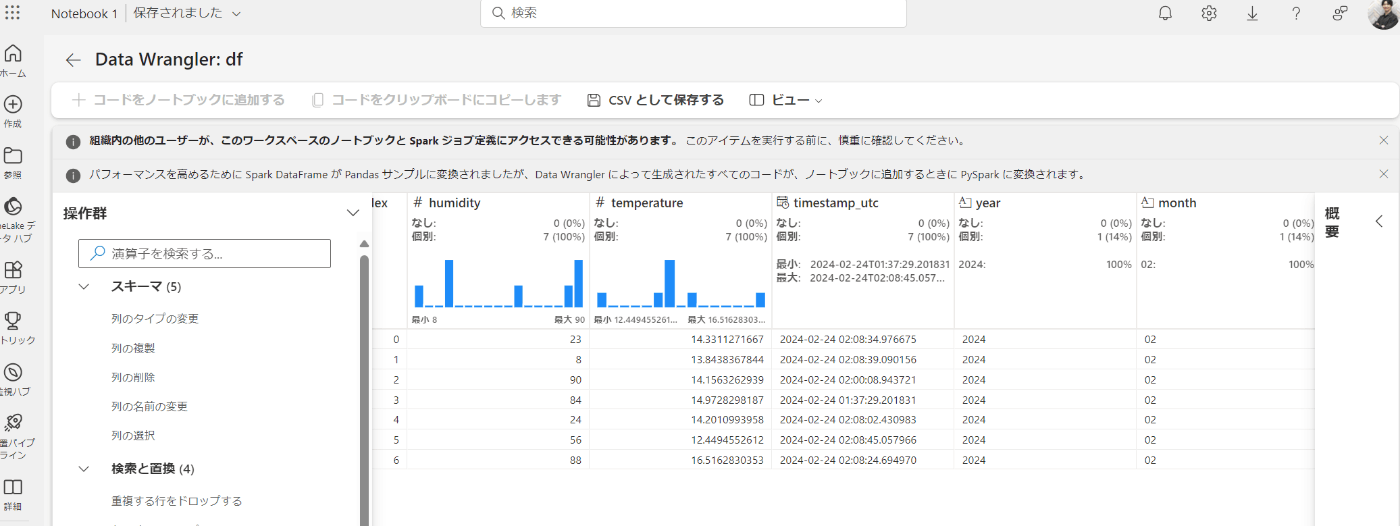
スキーマの操作
データのカラムに関する操作ができそうです。今回は「humidity」というカラム名を「湿度」に変換してみます。

適用をクリックすると、カラム名が変わりました。
簡単にカラムを追加、削除、編集できそうですね。

数値データの操作
数値データの切り捨てをしてみます。

切り捨てを行いたいカラム名を選択し適応をクリックします。
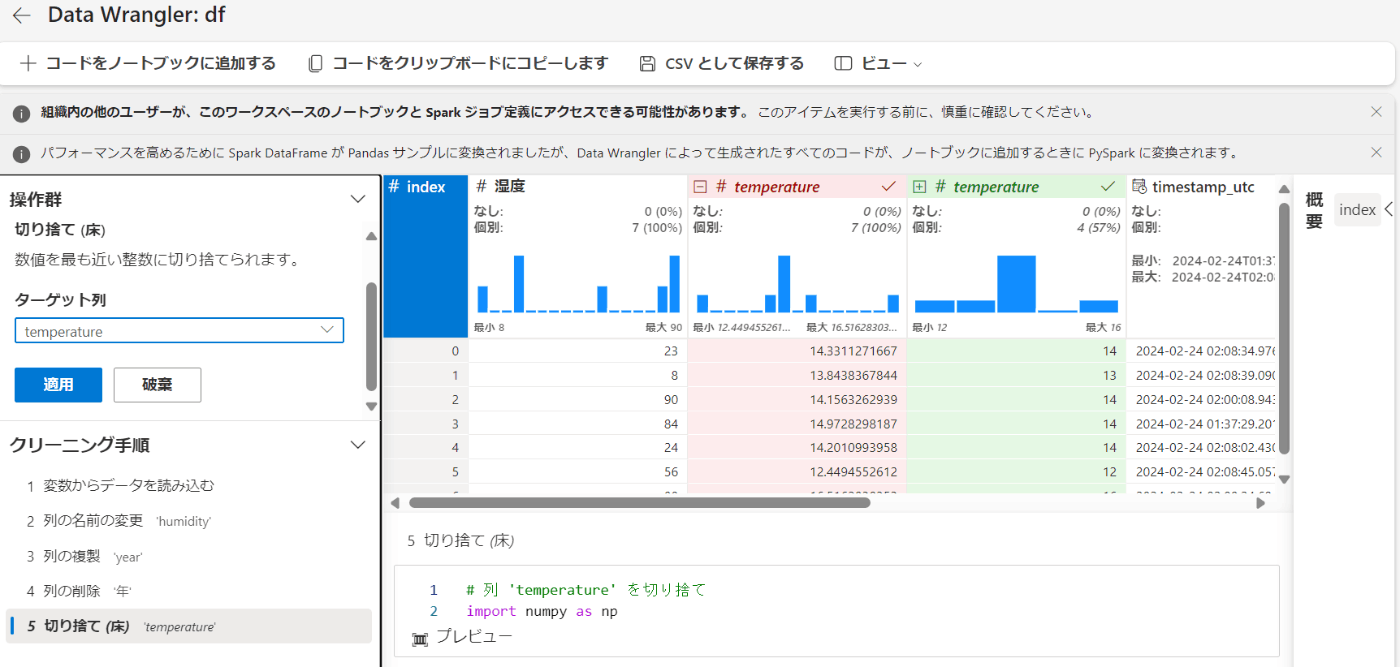
temperatureの小数点以降が切り捨てられました。
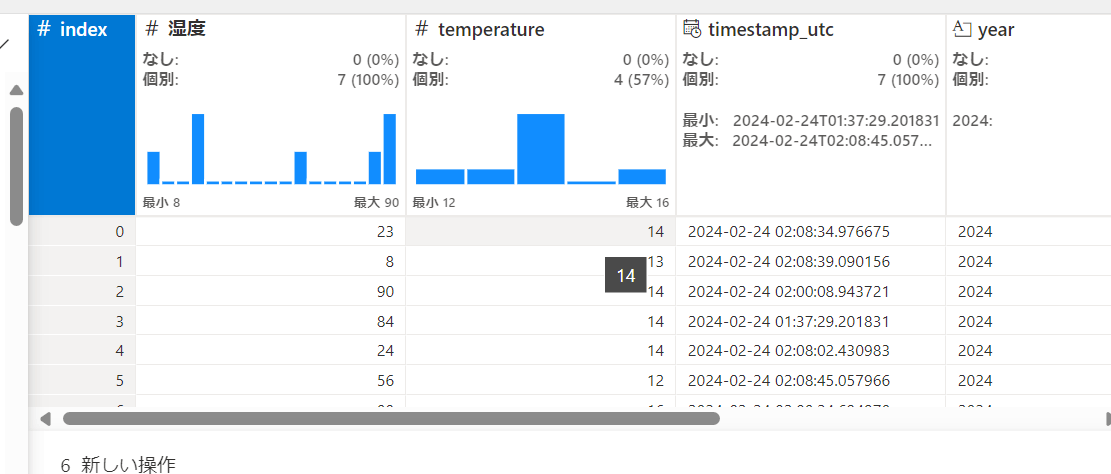
グループ化と集計
操作群からグループ化と集計をクリックします。
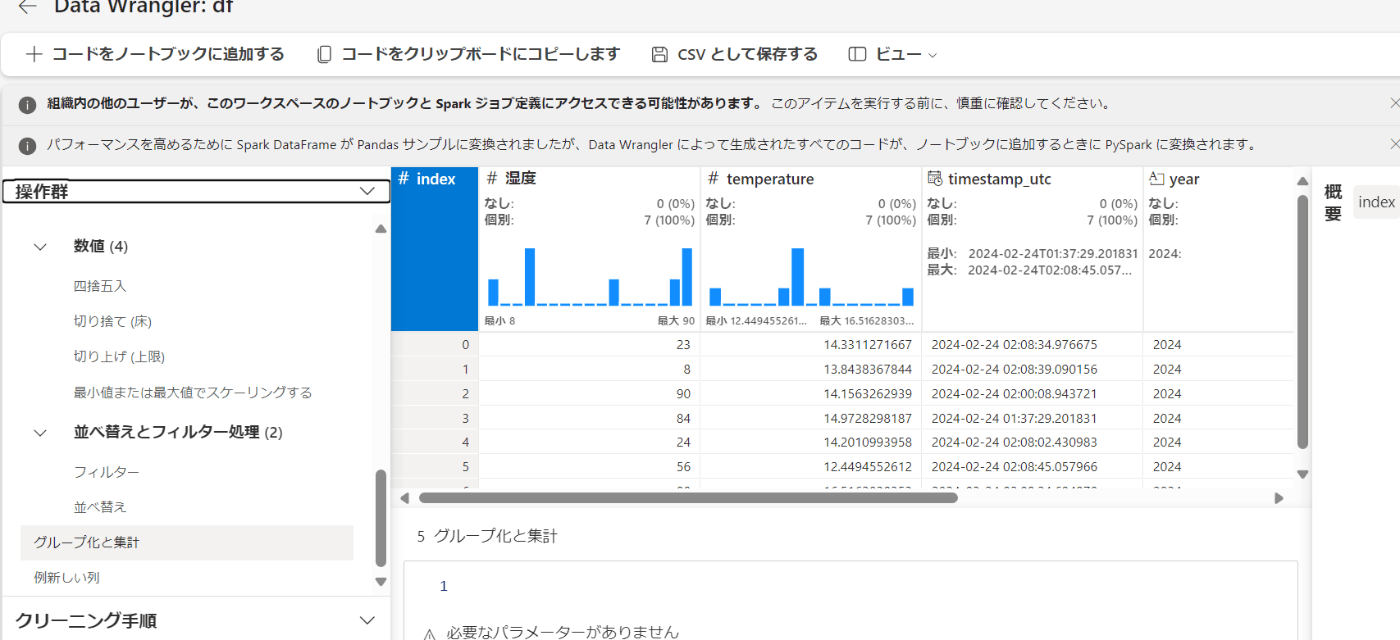
先程切り捨てしたtemperatureを選択します。
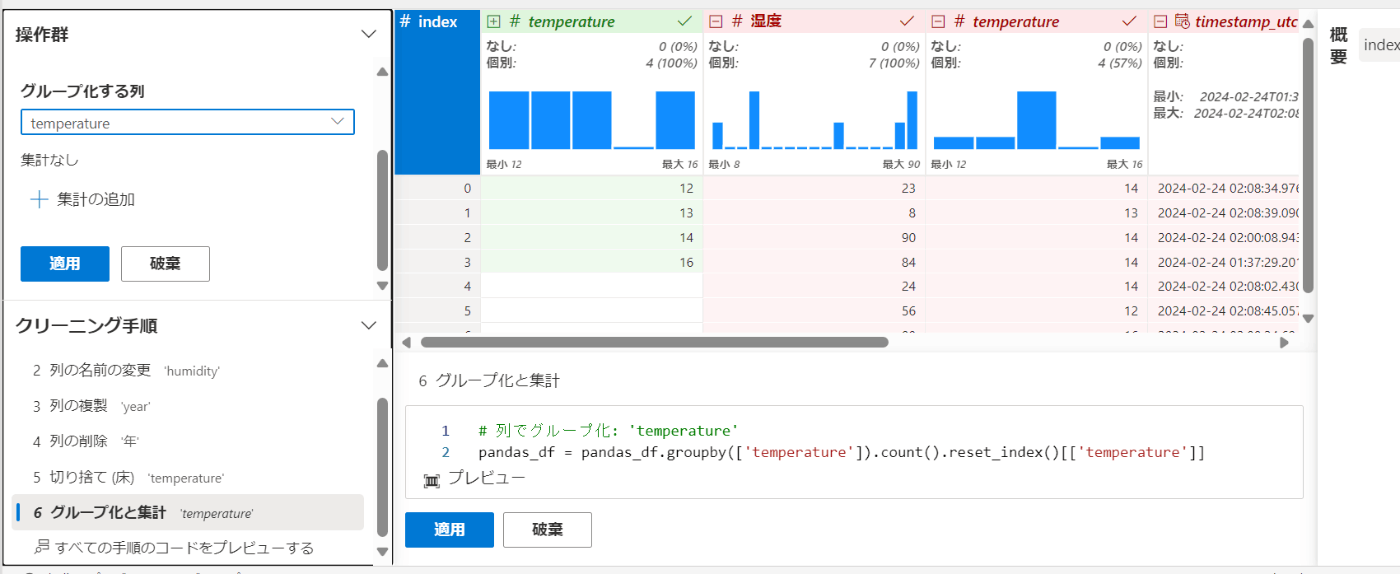
温度が13度のデータ、14度のデータ群がグループ化されて、データの数やカラムが変わりました。
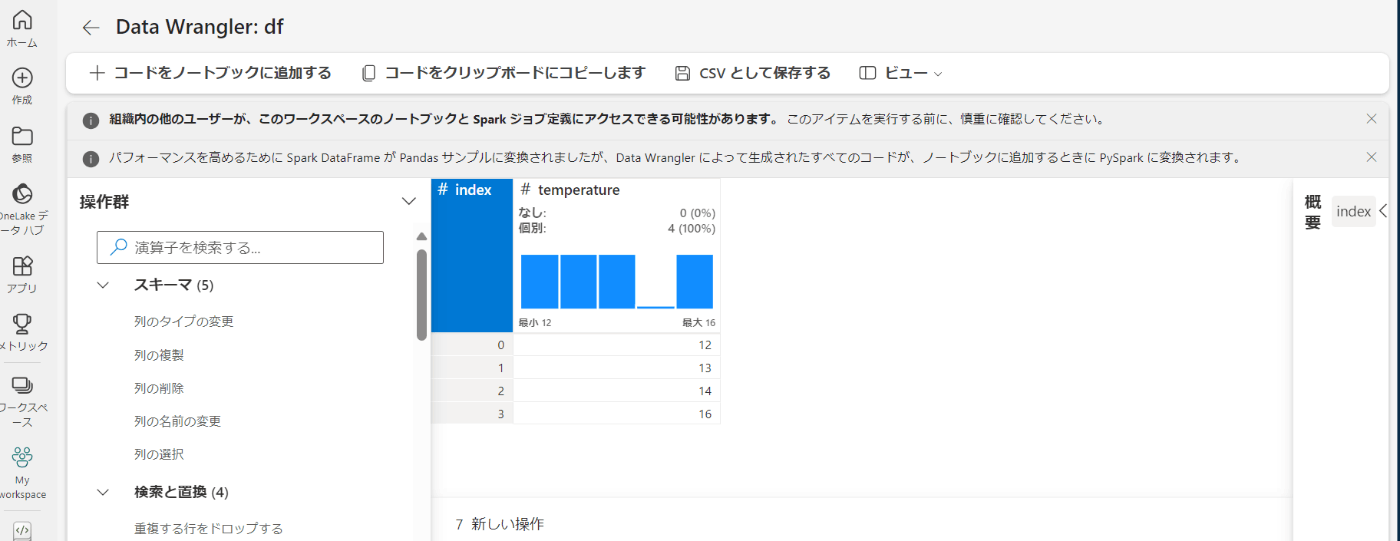
クリーニング手順
サイドバーの下の方に「クリーニング手順」というものがありました。なんだろうと思ってクリックしたら、これまで作業していたデータ処理の手順が一覧となって表示されていました。「すべての手順のコードをプレビューする」をクリックすると、これまでの処理がpythonコードとして表示されます。

一つひとつの作業をコードとして表示することも可能です。

おわりに
このData Wranglerの機能は、データ分析などの業務にて仕込みたいデータの前処理をGUIで実行できる機能だと言えそうです。
pythonを書いて正規化やグループ化などなど面倒な処理をしなくてもポチポチすればよしなに前処理できるのは、データサイエンティスト以外の素人やデータサイエンティスト初心者などにはありがたい機能だと思います。
自分みたいな浅い知識の人間でもそれっぽくデータの加工ができるのがこの機能の強みですね。
Fabricの思想がしっかり反映されていそうです。

Discussion
Wranglerの意味初めて知った!
これ使えば、検証のレポートとかのソースとしても使えそうだね<<
いいね!