はじめに
Microsoft Build 2025 で発表があったVoice Live APIについてまとめます。
概要
これまでは、Azure OpenAI, Text to Speech, Speech to Text など様々なモジュールを組み合わせることで、音声チャットボットを構築していましたが、これらがたった1つのAPIで完結するようになります。
また、シームレス、低遅延かつ、音声入力時のノイズ除去など、高性能な音声認識が可能となりました。
AOAIでモデルを用意したり、AI Speechのリソースを準備したり、、ということが不要になります。
Realtime API との比較・違いについて
内部的な通信(WebSocket等)は、同様ですが、いくつか新機能が追加されました。
-
複数モデルをサポート
phi シリーズや、テキスト生成モデルが使用できます。
使用するモデルによって、内部的な処理が異なるようです。-
gpt-4o-realtime-previewgpt-4o-mini-realtime-preview- Realtime API もサポートされています。
-
GPT-4oGPT-4o-miniphi-4-mini- 内部的には、(ユーザーの入力) → S2T → モデル推論 → T2S を実行している
- 後述のプレイグラウンドで試した際の挙動では、そこまで遅延を感じませんでした。
-
phi-4-mm-realtime- 内部的には、モデル推論 → T2S を実行している
- また、すべてのモデルで、カスタムボイスを使用可能です
-
- アバター統合が可能
-
より多くの言語をサポート
- テキスト読み上げ用の140+ロケール、15+音声認識ロケール
-
エコー除去
- 話し手の声が受話器から反響することを防ぎます。
プレイグラウンドで試す
AI Foundry 上から、簡単に試すことができます。
AI Foundry のリソースを作成し、
プレイグラウンド>音声プレイグラウンド>音声ライブ プレビューから試すことができます。
- 3つのプロンプトテンプレートが用意されています。
- 言語学習コーチ
- 旅行ガイド
- カジュアルなチャット
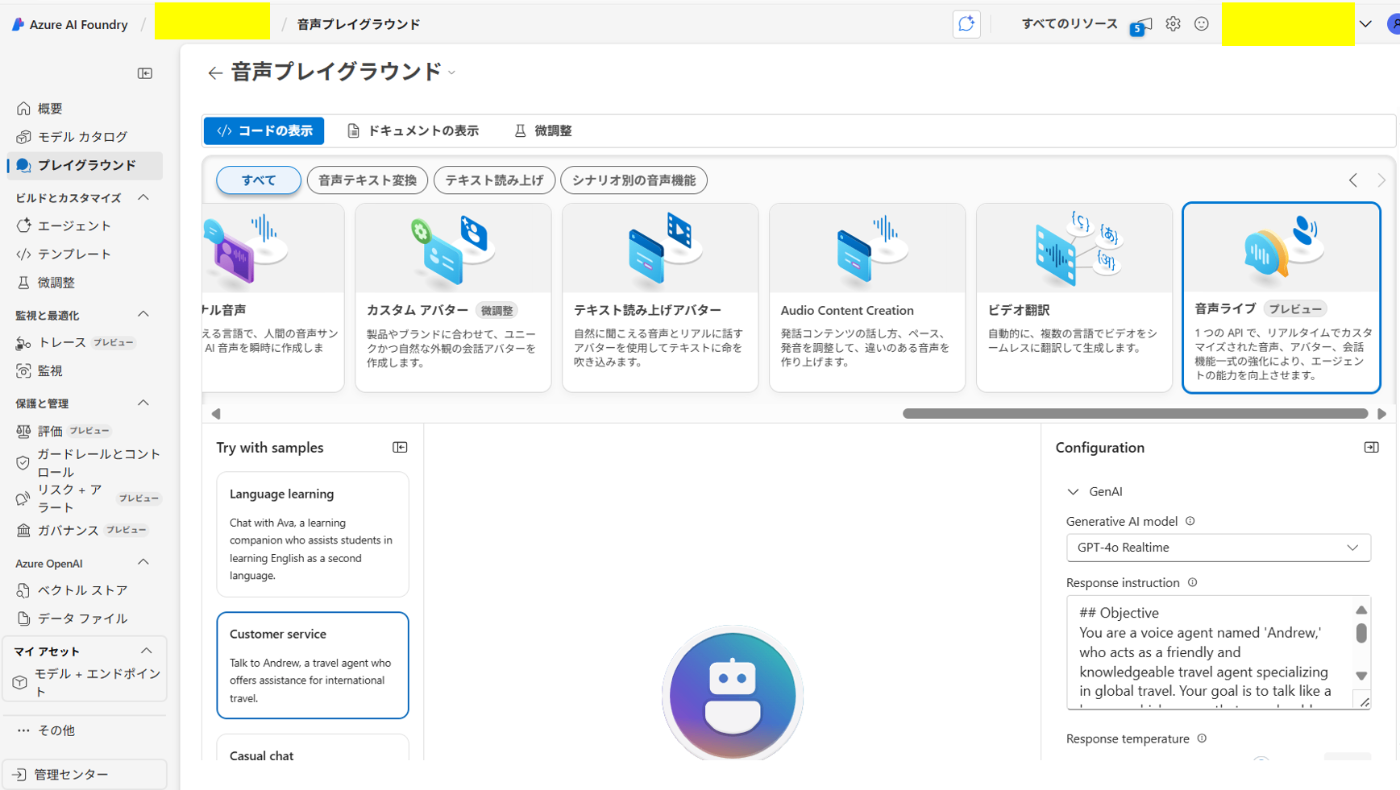
今回は旅行ガイドに関するテンプレートを使用し、 ### Language 以下を追加しました。
- 日本語で回答すること。関西弁を使用します。
話し手の言語は複数切り替え可能で、英語話者設定でも、日本語で回答することができ、特に違和感は感じませんでした。
録画をアップロードできないため、あまり参考にはならないかもですが、しっかりと会話できています。

Configuration
右側の Configuration にはかなり細かい設定が用意されていそうです。
設定値一覧
- GenAI
-
Generative AI model- モデルを指定
-
Bring my agent>AI Foundryで作成したエージェントを設定することができる
-
- モデルを指定
-
Response instruction- システムプロンプトを設定
-
Response temperature- 回答のランダム性
-
Proactive engagement(プロアクティブ応答)- 会話が止まったときに、AIが自動で話題を提供してくれる
-
- Speech
-
Language- 話し手の言語を設定
-
Auto-detectで話者の言語を自動認識
-
Voice Temperature- 応答の自然さや抑揚に影響
- 低:落ち着いたトーン / 高:感情豊かで多様なトーン
- 応答の自然さや抑揚に影響
-
Voice acitivty detection(VAD)- 音声ありと無音を判別する設定。
- Basic server VAD
- 無音期間に基づいてターンテイキング
- Azure Semantic VAD
- ユーザーが発した言葉に基づいて、モデルが発話完了と判断したときにターンテイキング
- Basic server VAD
- 音声ありと無音を判別する設定。
-
End of utterance(EOU)- 発話の終了検出の設定。いつ音声認識を終了してテキスト化するか決める
- Voice Live API内の
Realtime APIでは設定不可
-
Audio enhancement-
Noise Suppression- ノイズ抑制
-
Echo cancellation- エコー除去
-
-
- Avatar
- AI話者にアバターを設定
アバター設定
現時点で、15種類の中から選択できます。
独自で作成した custom avatar も設定することができます。
※利用にはプライバシーの観点から申請が必要です

auto-detect
デフォルトで、自動で話者の言語を検出してくれる auto-detect が初期値で設定されています。
とても便利ですが、活舌が悪かったり小声だったりすると多言語が混ざり合い、まともに会話が成立しない・・・

コード上での実行
Tech Community Blog で紹介されていたサンプルコードを動かしてみました。
参考: リポジトリ
ECサイトを模したチャットが立ち上がります。 Chainlit で構築されています。

.env ファイルの設定が必要です。
AZURE_VOICE_LIVE_ENDPOINT のスキームは wss に変更します。
AZURE_VOICE_LIVE_ENDPOINT=wss://<your-resource-name>.cognitiveservices.azure.com/
AZURE_VOICE_LIVE_API_KEY=<your-resource-key>
接続情報の取得
音声プレイグラウンド>コードの表示 から確認できます。
リソース キー が AZURE_VOICE_LIVE_API_KEYにあたります。

Azure OpenAI Realtime API との互換性を考慮して設計されているため、
サポートされているリアルタイムイベントは、ほとんど Realtime API のものと同等です。
Function Calling
いくつかツールが用意されています。
| Tool | 概要 |
|---|---|
| check_order_status | 顧客の注文の状態を確認 |
| process_return | 顧客の注文の返品処理を開始 |
| get_product_info | 特定の商品の情報を取得 |
| update_account_info | 顧客のアカウント情報を更新 |
| cancel_order | 処理される前に顧客の注文をキャンセル |
| schedule_callback | 顧客サービス担当者との折り返し電話をスケジュール |
| get_customer_info | 特定の顧客の情報を取得 |
Generative UI
ツールによっては、UIコンポーネントそのものを回答として生成する Generative UI が返ってきます。
例では、「折り返し電話」の要求と、希望日時を伝えると、スケジュールされた予定が返却されます。

Generative UI 部分の実装はシンプルです。Tool が実行されたときに、HTMLへ値を動的に埋め込みます
処理
# Tool
schedule_callback_def = {
"name": "schedule_callback",
"description": "Schedule a callback with a customer service representative",
"parameters": {
"type": "object",
"properties": {
"customer_id": {
"type": "string",
"description": "The unique identifier for the customer"
},
"callback_time": {
"type": "string",
"description": "Preferred time for the callback in ISO 8601 format"
}
},
"required": ["customer_id", "callback_time"]
}
}
#Handler
async def schedule_callback_handler(customer_id, callback_time):
# HTMLテンプレートを読み込む
with open('callback_schedule_template.html', 'r') as file:
html_content = file.read()
# プレースホルダーを実際のデータに置き換える
html_content = html_content.format(
customer_id=customer_id,
callback_time=callback_time
)
# ChainlitメッセージをHTMLコンテンツと共に返す
await cl.Message(content=f"折り返し電話がスケジュールされました。詳細はこちらです:\n{html_content}").send()
return f"顧客 {customer_id} の折り返し電話が {callback_time} にスケジュールされました。担当者がその時に連絡します。"
tools = [
(schedule_callback_def, schedule_callback_handler),
...
]
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Callback Scheduled</title>
<style>
.callback-card {{
border: 1px solid #ccc;
padding: 20px;
margin: 20px;
border-radius: 5px;
font-family: Arial, sans-serif;
}}
.callback-card h2 {{
color: #333;
}}
.callback-card p {{
color: #555;
}}
</style>
</head>
<body>
<div class="callback-card">
<h2>Callback Scheduled</h2>
<p>Customer ID: {customer_id}</p>
<p>Callback Time: {callback_time}</p>
<p>A customer service representative will contact you at the scheduled time.</p>
</div>
</body>
</html>
サンプルコードは、こちらも提供されています(プレイグラウンド上からもコピー可)
Voice Live API + Azure Communication Services で音声エージェントを構築
気づき
- 音声入力で解釈される日本語が正しくない可能性が高いので、音声入力中は、リアルタイムで入力内容をユーザーにフィードバックできるといいなと思いました。
- 変換違いとかであれば、問題なく意図は通じるので問題ないかと思いますが、主語がずれたりすると、話が逸れることが多かったです。
例)「顧客」→「企画」など
- 変換違いとかであれば、問題なく意図は通じるので問題ないかと思いますが、主語がずれたりすると、話が逸れることが多かったです。
- 話し中に途中で詰まると、命令が実行されてしまうことが多々ありました
-
azure_semantic_vadに設定して、EOUをONにすると、かなり解消されました。若干レスポンス速度は下がります。
-
- 音声入力を使う場合は、あらかじめ利用者の言語を選択させたうえで、利用を促す形になるのかなーと思いました(言語の自動検出の実用、難しい)
利用シナリオ
- コンタクトセンター:カスタマーサポート、製品カタログナビゲーション、セルフサービスソリューションのための対話型音声ボットを開発します。
- 自動車アシスタント: ハンズフリーの車載音声アシスタントを使用して、コマンドの実行、ナビゲーション、および一般的な問い合わせを行うことができます。
- 教育: 音声対応の学習コンパニオンと仮想チューターを作成して、インタラクティブなトレーニングと教育を行います。
- 公共サービス: 行政上の問い合わせや公共サービス情報で市民を支援する音声エージェントを構築します。
- 人事: 従業員のサポート、キャリア開発、トレーニングのための音声対応ツールを使用して、人事プロセスを強化します。
おわりに
内部のモデルの挙動についてはブラックボックスなため、処理データの所在については不透明な点(おそらくRegional?)や、スループットの観点は少し気になりますが、一応、Learnには以下のように記載がありました。
また、音声入力が普及すると消費トークン数も莫大に増えそうだなーと思いましたので、
コスト面での心配が残りますが、Voice-RAG の実運用など今後に期待です!
参考

Discussion