やること
Lakehouse内のcsvファイルを読み込み、AOAIにプロンプトを投げる。
結果を受け取り、LakehouseのTableに保存する。
前準備
- 下記のコードを実行し、csvファイルを作成
import csv
# 英語の文章のリストを作成
English = [
"I love to travel and explore new places.",
"She is a talented singer and songwriter.",
"The sunsets in Santorini are breathtakingly beautiful.",
"Learning a new language can be challenging but rewarding.",
"The book I'm currently reading is very thought-provoking.",
"He has a great sense of humor and always makes me laugh.",
"The internet has revolutionized the way we communicate.",
"I enjoy cooking and trying out new recipes.",
"Exercise is important for maintaining good physical and mental health.",
]
# CSVファイルに出力
with open('sentences.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(["Englsih"])
for sentence in English:
writer.writerow([sentence])
print("CSVファイルに出力が完了しました。")
- NotebookとLakehouseを作成
↓作成手順
検証手順
- Notebookを開く

- Files>アップロード>ファイルのアップロードをクリック

- 「ファイル」をクリック

- 作成したcsvファイルをアップロード

- Notebookで下記のコードを実行し、csvファイルの中身を確認
df = spark.read.format("csv").option("header","true").load("Files/sentences.csv")
# df now is a Spark DataFrame containing CSV data from "Files/sentences.csv".
display(df)

6. テーブル作成
df = spark.read.format("csv").option("header","true").load("Files/sentences.csv")
# df now is a Spark DataFrame containing CSV data from "Files/sentences.csv".
table_name = "AOAI"
df.write.mode("overwrite").format("delta").save("Tables/"+table_name)
display(df)
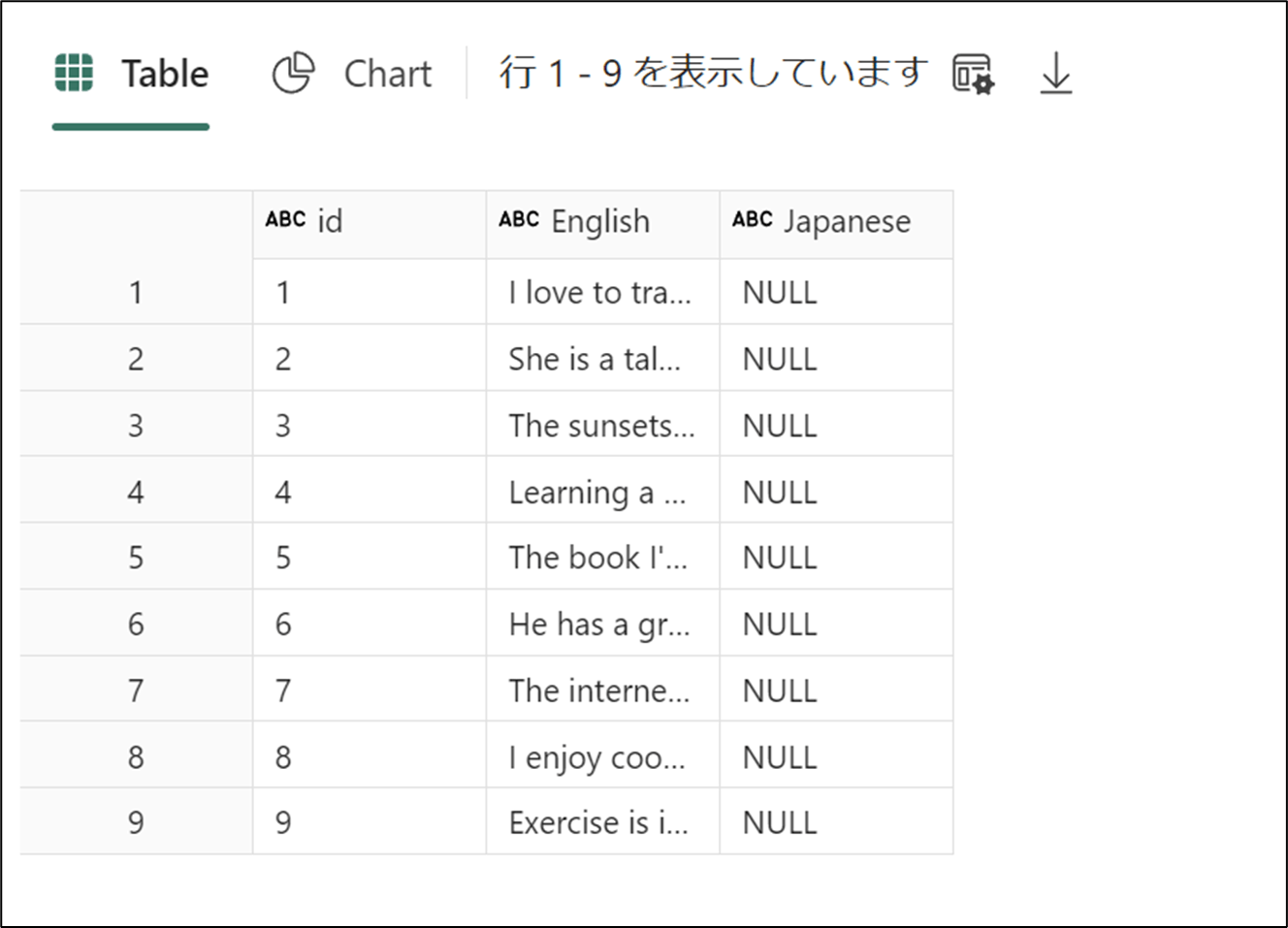
- 下記のコードを実行し、英語を日本語にするプロンプトを投げ、Japanseカラムに追加
import os
import openai
openai.api_type = "azure"
openai.api_version = "2023-05-15"
openai.api_base = "<Azure Open AIのエンドポイント>"
openai.api_key = <Azure Open AIのキー>"
# 英語テキストの全てのレコードを取得
english_texts = df.select("ID", "English").collect()
# 翻訳結果を格納するリスト
translated_rows = []
# それぞれの英語テキストを翻訳
for row in english_texts:
# Azure OpenAIを使用して翻訳
prompt = "Translate the following English text to Japanese: " + row['English']
response = openai.ChatCompletion.create(
engine="<モデル名>",
messages=[
{"role": "system", "content": "Assistant is a large language model trained by OpenAI."},
{"role": "user", "content": prompt}
]
)
# 翻訳されたテキストを取得
japanese_translation = response.choices[0].message['content']
translated_rows.append((row['ID'], japanese_translation))
# 新しいDataFrameを作成し、元のDataFrameに統合
translated_df = spark.createDataFrame(translated_rows, ["ID", "Japanese"])
# 元のDataFrameのJapaneseカラムを翻訳で更新
final_df = df.join(translated_df, "ID", "left_outer") \
.select(df["ID"], df["English"], translated_df["Japanese"])
# IDに基づいて結果をソート
final_df = final_df.orderBy("ID")
# 結果を保存
final_df.write.mode("overwrite").format("delta").save("Tables/AOAI")
- 下記のコードを実行し、Tableを確認する
df = spark.sql("SELECT * FROM AOAI.AOAI LIMIT 1000")
display(df)
- 日本語訳が追加されたことを確認


Discussion