リキッドクラスタリングとは?
Databricksの リキッドクラスタリング は、Delta Lake テーブルのデータを効率的に並び替える仕組みです。従来のパーティションやZ-ORDERに代わる 次世代のデータ配置最適化機能 として提供されています。
ポイントを要約すると以下の3つです。
- 物理パーティションを意識せずに、任意の列でデータをクラスタリングできる
= 「年月ごとにフォルダを分ける」みたいな物理分割を気にせず、欲しい列(例:日付、顧客IDなど)を軸に並び替えられる。
- データ更新や追加に応じて 自動でクラスタリングを維持する
= 新しいデータを入れても、裏で自動的に整理整頓されるので、後から手動で並び替えなくてよい。 - Z-ORDER のように手動で
OPTIMIZEを回さなくてよい
= 従来の「バッチ的に最適化ジョブを回す作業」が不要。放っておいても常に効率的な配置を維持してくれる。
従来のパーティション分割の限界
従来の PARTITIONED BY も、Hadoopやクラウドストレージ上で、指定した列の値ごとにディレクトリを切り分けてファイルを格納する方式でした。
-
メリット
-
WHERE year = 2025のようなクエリでは劇的にスキャン量を削減できる
-
-
デメリット
- パーティション数が増えるとメタデータ管理コストが急増
- 「日付+ID」など複数条件のフィルタには弱い
- 更新が多いテーブルでは再分割コストが発生
上記のように大規模データの扱い時にはデメリットも複数存在するため、
Databricks では、「パーティション機能= 大規模データや更新頻度が高いケースでは非推奨に近い扱い 」となってきています。

上記リファレンスにも「液体(リキッド)クラスタリングが推奨」と記載。液体…。
リキッドクラスタリングの登場
そのリキッドクラスタリングですが、これは物理的なパーティションではなく データの論理的な並び によって最適化します。
- 特に有効的なシナリオ
-
種類が多い列でよく絞り込み検索するテーブル
(例:顧客ID、商品コードなど、数が膨大で細かい条件検索が多い場合) -
データの分布が偏っているテーブル
(ある顧客や特定の日付だけデータが集中するようなケース) -
データ量がどんどん増えて運用が大変になるテーブル
(サイズ拡大に応じて手動メンテや最適化が必要になるもの) -
同時に複数の処理から書き込みが行われるテーブル
(リアルタイム更新や高頻度のデータ投入がある場合)
-
種類が多い列でよく絞り込み検索するテーブル
要するに、「複雑・大量・変化が激しいテーブルほど、リキッドクラスタリングの恩恵が大きい」 ってイメージのようです。
検証
検証内容
以上が前提として、本当にパーティションよりもリキッドクラスタリングのほうが便利なのか?ということを検証してみようと思います。
-
リキッドクラスタリング と パーティションテーブル を作成
-
同じ 100万件(行)超のダミーデータを投入
-
以下3種類の典型的なクエリを比較
- (A) 日付+顧客ID
- (B) 年月だけ
- (C) 顧客IDだけ
テーブル作成~ダミーデータ投入までの具体的な手順は割愛しますが、
主な違いはテーブル作成時、以下のようにリキッドとパーティションを指定していることです。
-- リキッドクラスタリングテーブル
USING delta
CLUSTER BY (order_date, customer_id); --違いはココ
-- パーティションテーブル
USING delta
PARTITIONED BY (year(order_date), month(order_date)); --違いはココ
実行クエリ
今回の比較では、以下の 3 パターンのクエリを、
リキッドクラスタリングテーブル と パーティションテーブル それぞれで合計6回実行しました。
-- (A) 日付 + 顧客ID
SELECT *
FROM `テーブルパス`
WHERE order_date BETWEEN '2022-01-01' AND '2022-12-31'
AND customer_id = 'CUST_123';
-- (B) 年月だけ
SELECT *
FROM `テーブルパス`
WHERE order_date BETWEEN '2023-05-01' AND '2023-05-31';
-- (C) 顧客IDだけ
SELECT *
FROM `テーブルパス`
WHERE customer_id = 'CUST_456';
出力結果
まずSQLエディターUIで、すぐに実行状況や所要時間など確認できます。
クエリー履歴から見ると、より詳細が表示できます。実行時間など確認できます。
さらに詳細を表示させるとこんな感じ。読み込んだ行数やファイル数など。

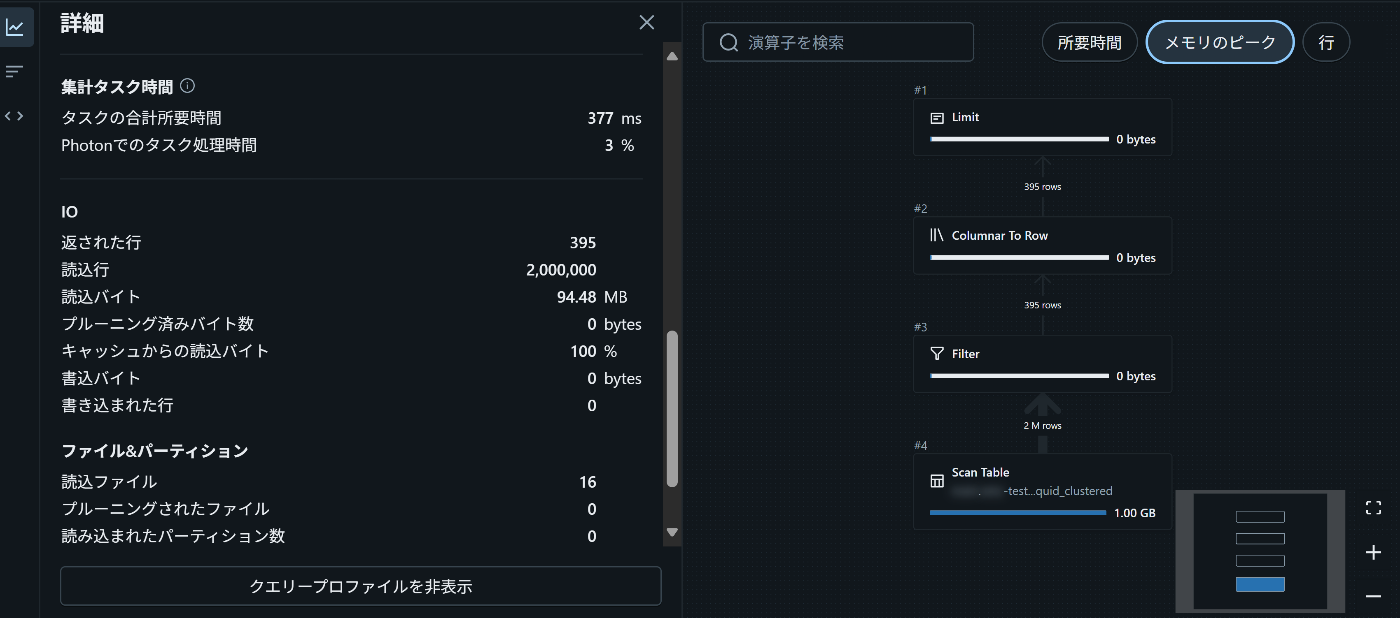
今回のクエリ結果一覧表
上記のイメージで、6種のクエリの出力結果を確認し、表にまとめてみました。
| ケース | 条件 | Liquid Clustering | Partitioned | ポイント |
|---|---|---|---|---|
| A | 日付+顧客ID |
返却行数: 395 時間: 1.31s 読込: 2M行 / 94.5MB / 16ファイル |
返却行数: 593 時間: 1.76s 読込: 3M行 / 117.7MB / 3ファイル |
複数条件(日付+顧客ID)に強いのは Liquid。読み込み件数が大幅に減って高速化している。 |
| B | 年月だけ |
返却行数: 1000 時間: 592ms 読込: 57K行 / 6.2MB / 16ファイル |
返却行数: 1000 時間: 528ms 読込: 61K行 / 64.7MB / 3ファイル |
単一キー(日付のみ)の場合は パーティション が効率的。Liquid との差は小さい。 |
| C | 顧客IDだけ |
返却行数: 1000 時間: 597ms 読込: 1.25M行 / 59MB / 16ファイル |
返却行数: 1000 時間: 534ms 読込: 1.03M行 / 64.7MB / 3ファイル |
顧客IDだけでは効果が限定的。Liquid も多少効くが、パーティションと大差なし。 |
まとめ
考察
1. 複数条件検索が多い業務ではリキッドクラスタリングが有利
- 「日付+顧客ID」など複数条件の検索では、リキッドの効果が明確。
- 今後の利用パターンが読み切れない分析テーブルは、リキッドを選ぶのが無難。
2. 日付中心のバッチ処理はパーティションでも十分
- 「年月だけ」の抽出では、パーティションがシンプルかつ効率的。
- ログや定例レポートなど、日付キーが唯一の条件ならパーティションが有効。
3. 顧客や商品 ID 単独検索は差が小さい
- ID 単独ではリキッドの効果は限定的。
- 件数が少なければ性能面で大きな問題になることは少ない。
テーブル作成時に意識すべきこと
とりあえず大量データを雑に用意しただけなので、リキッドクラスタリングの恩恵を100%享受できたかといわれるとそうでもないのですが、なんとなくできることは確認できました。
- パーティション=固定レーン:日付単位の処理には強いが、複数条件には弱い
- リキッド=オールラウンダー:複合条件や将来の変化に対応しやすいが、運用コストはゼロではない
「将来の利用が読めないならリキッド、利用条件が単純ならパーティション」
と考えてよいのかなと考えています。
この選択で後々の性能や運用負荷も変わるので、しっかりと将来的にどんな使われ方がされるテーブルかを考えて、テーブル作成する必要がありますね。

Discussion