ゴール
Databricks を日常的に使っていると、Notebook や SQL エディタで
「似たようなクエリ」を何度も書くことがよくあります。
条件をコピペして実行するたびに、(またこの WHERE 句を打っているな)と
感じる方も多いのではないでしょうか。
こうしたクエリの乱立は、
- 分析効率の低下(過去のクエリを探す時間がかかる)
- 再利用性の欠如(誰かが作った条件がチーム内で共有されない)
- パフォーマンス改善の視点が失われる(どんな条件が頻繁に使われているのか見えにくい)
といった課題につながります。そこで本記事では、
Databricks Unity Catalog の Query History(クエリ履歴) を活用して、
高頻度で使われている条件を特定し、それを View として保存・再利用する流れを紹介します。
保存されたViewをクエリーUIから選択
すぐに再利用できる
Query Historyとは?
Databricks では、Unity Catalog のシステムテーブル system.query.history を通じて、
SQL Warehouse や Serverless SQL で実行されたクエリ履歴を取得できます。
ここには、SQL Warehouseで実行されたクエリの情報が記録されます。
「SQL エディタで誰がどんなクエリを投げたか」を追跡できるイメージです。
取得できる主なカラムは以下のとおりです。
-
start_time: クエリの実行開始時刻 -
executed_by: クエリを実行したユーザー -
execution_status: クエリの成否(FINISHED / FAILED など) -
statement_text: 実際に実行された SQL 文
Databricksならではのメリット
BigQuery なら INFORMATION_SCHEMA.JOBS、Snowflake なら ACCOUNT_USAGE.QUERY_HISTORY など、
主要なDWHにも「クエリ履歴」を確認する機能はあります。
ただし、Databricksならではの強みもあります。
-
Unity Catalogで一元化
複数のワークスペースで実行されたクエリ履歴をまとめて管理できる。
組織全体での利用傾向を横断的に把握可能。 -
SQLとPythonを同じノートブックで扱える
履歴の抽出は SQL、抽出結果を使った View 生成や自動化は Python、
といった使い分けがシームレスに実現できる。 -
ガバナンスとの統合
Query History と Access History を組み合わせることで、
「誰が、どのデータを、どう参照したか」 を包括的に追跡できる。 -
パフォーマンス可視化が容易
実行時間、読み取り行数・バイト数、キャッシュ利用状況などが記録されるため、
どのクエリがボトルネックかを分析しやすい。 -
実行起点を特定できる
query_sourceにより、Notebook・ジョブ・ダッシュボードなど
「どのツールやワークロードから発行されたクエリか」が明確になり、
利用用途の把握や改善につなげられる。
つまり、単なる「ログ」ではなく、
監査・利用分析・再利用のサイクルを1つの環境で回せること が
Databricks ならではのメリットと言えそうです。
(この辺りはデスク調査なので違っている場合はご指摘いただけると嬉しいです)
参考:
Viewの作成
対象テーブル
本記事では、検証用に作成した main.seto-test.orders というテーブルを題材にします。
サンプルの受注データを模したもので、以下のような特徴があります。
- 行数: 約 24,000 行(1日あたり200件 × 直近120日分の注文データを想定)
- データの粒度: 日単位の受注レコード
主なカラムは以下のとおり
| カラム名 | 説明 |
|---|---|
order_id |
注文を一意に識別するID(UUID形式) |
customer_id |
顧客を識別するID(ランダム生成) |
region |
地域(例: APAC, JPN, EMEA, AMER) |
channel |
注文チャネル(例: WEB, MOBILE, STORE, PARTNER) |
status |
注文ステータス(例: PAID, PENDING, CANCELLED, REFUNDED) |
order_date |
注文日付(過去120日分をカバー) |
amount |
注文金額(100〜1000程度のランダムな数値) |
このテーブルを題材にすることで、「実際によく使われるWHERE句」が
Query History にどう記録されるのかを再現できるようにします。
検証環境の準備
次に、対象テーブルに対して「よく使われるであろうクエリ」を実行し、
Query History に履歴を残す準備をします。
以下のような3種類の典型的なクエリを用意しました。
実際の業務でも似たような条件が繰り返し使われるケースを想定しています。
直近 7 日間に実行されたクエリのWHERE句ごとの出現回数を集計
-- A: APAC × 直近30日(★★★1番頻出のクエリ)
SELECT count(*)
FROM main.`seto-test`.orders
WHERE region = 'APAC'
AND order_date >= current_date() - INTERVAL 30 DAYS;
-- B: JPN × 直近7日(★★中頻度で実行されるクエリ)
SELECT avg(amount)
FROM main.`seto-test`.orders
WHERE region = 'JPN'
AND order_date >= current_date() - INTERVAL 7 DAYS;
-- C: WEBチャネル × 当月(★たまに集計されるクエリ)
SELECT region, sum(amount) AS revenue
FROM main.`seto-test`.orders
WHERE channel = 'WEB'
AND date_trunc('month', order_date) = date_trunc('month', current_date())
GROUP BY region;
- クエリ A は 一番頻出にしたいので 5〜6 回
- クエリ B, C は 2〜3 回
という感じで実行しています。
高頻度クエリを抽出
次に、Query History から「どの条件がよく使われているか」を抽出 します。
Databricks では Unity Catalog のシステムテーブル system.query.history に
直近のクエリが保存されています。
このテーブルの statement_text 列には実際に実行された SQL 文が入っているため、
正規表現で WHERE 句だけを抜き出して頻度をカウントすることができます。
以下は、直近 7 日間に実行されたクエリの中から、main.seto-test.orders を参照しているものを対象に、WHERE 句ごとの出現回数を集計する SQL です。
直近 7 日間に実行されたクエリのWHERE句ごとの出現回数を集計
-- 直近7日間に実行されたクエリ履歴から、対象テーブルを参照するものを抽出し、
-- WHERE句ごとに頻度をカウントして上位3件を取得する処理
WITH q AS (
SELECT
-- クエリ本文(statement_text)を小文字化し、余分なスペースを正規化
lower(regexp_replace(statement_text, '\s+', ' ')) AS st
FROM system.query.history
WHERE start_time >= current_timestamp() - INTERVAL 7 DAYS -- 直近7日間に絞る
AND execution_status = 'FINISHED' -- 成功したクエリのみ対象
AND statement_text ILIKE '%seto-test%.orders%' -- 対象テーブルを含むクエリに限定
),
w AS (
SELECT
-- 正規表現で WHERE 〜 (GROUP BY / ORDER BY / LIMIT) の部分だけを切り出す
trim(
regexp_extract(
st,
'where (.*?)( group by| order by| limit|$)',
1
)
) AS where_clause
FROM q
)
SELECT
-- WHERE句ごとに出現回数を集計
where_clause, COUNT(*) AS runs
FROM w
WHERE where_clause IS NOT NULL
GROUP BY where_clause
ORDER BY runs DESC
LIMIT 3; -- 上位3件を取得

実際の出力例*
予定通り、クエリAが最も高頻度で実行されていることがわかります。
続いて クエリB,クエリCがそれに続いています。
頻出条件をView化する
高頻度で実行されているクエリ条件がわかったため、 View として保存 します。
これにより毎回同じ WHERE 句を書かなくても、すぐに分析へ活用できるようになります。
今回は、上位 3 つの条件をそのまま v_orders_top1, v_orders_top2, v_orders_top3 としてビュー化しました。
View化
-- 頻出クエリの上位3条件を View として保存する
-- これにより毎回同じ WHERE 句を書く必要がなくなり、再利用性が高まる
-- 1位: APAC × 直近30日
-- 「APAC地域かつ直近30日の注文」を簡単に呼び出せるビュー
CREATE OR REPLACE VIEW main.`seto-test`.v_orders_top1 AS
SELECT *
FROM main.`seto-test`.orders
WHERE region = 'APAC'
AND order_date >= current_date() - INTERVAL 30 DAYS;
-- 2位: JPN × 直近7日
-- 「日本地域かつ直近7日の注文」を簡単に呼び出せるビュー
CREATE OR REPLACE VIEW main.`seto-test`.v_orders_top2 AS
SELECT *
FROM main.`seto-test`.orders
WHERE region = 'JPN'
AND order_date >= current_date() - INTERVAL 7 DAYS;
-- 3位: WEBチャネル × 当月
-- 「WEBチャネルの当月売上」を地域ごとに集計して呼び出せるビュー
CREATE OR REPLACE VIEW main.`seto-test`.v_orders_top3 AS
SELECT region, sum(amount) AS revenue
FROM main.`seto-test`.orders
WHERE channel = 'WEB'
AND date_trunc('month', order_date) = date_trunc('month', current_date())
GROUP BY region;
作成・保存に成功するとOKと出力されます。
出力の確認
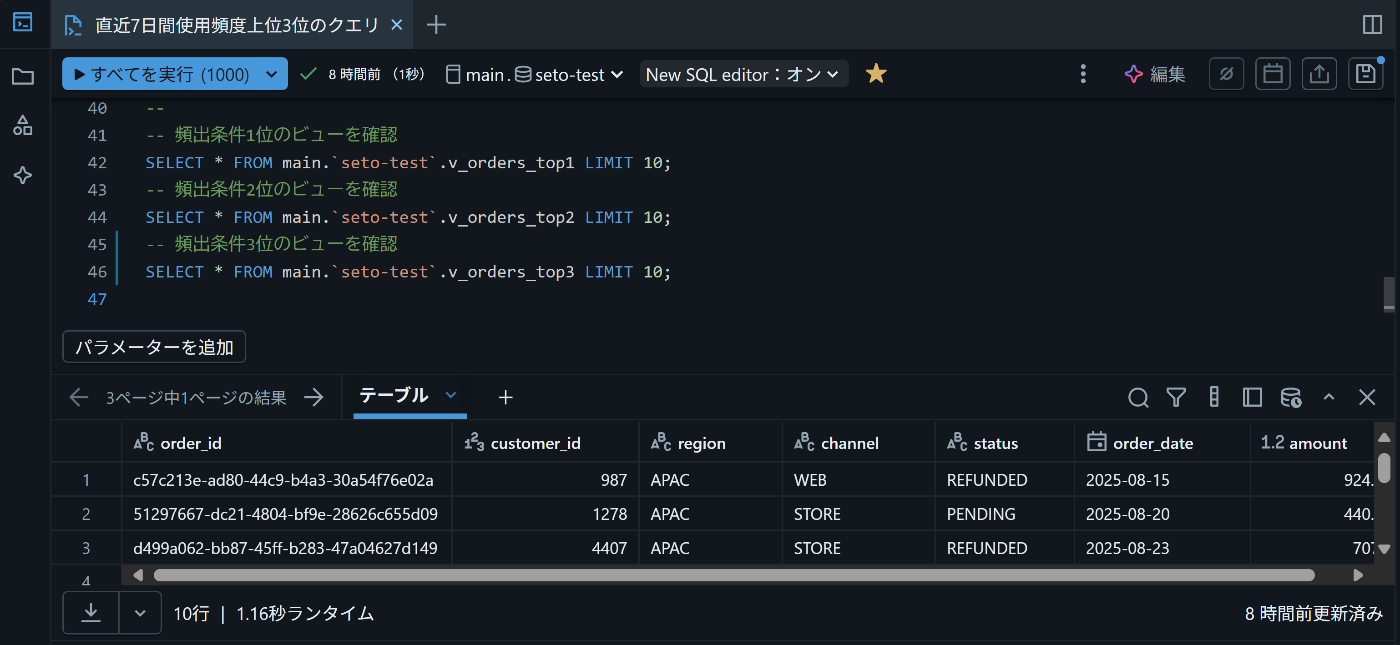
実際にビューを呼び出すと、意図した条件でデータが返ってくることが確認できます。
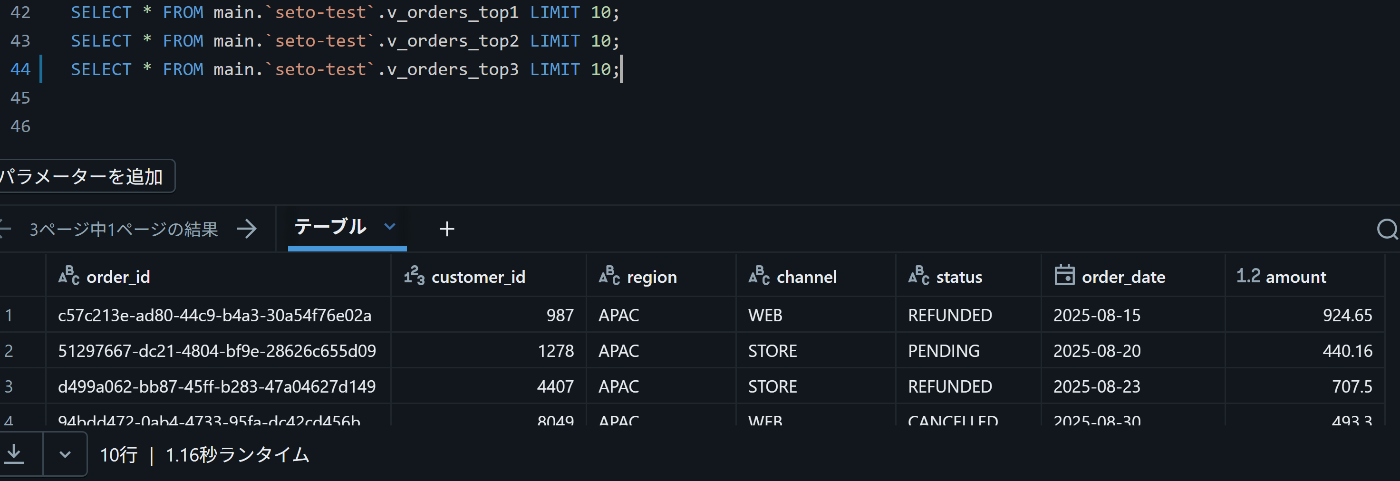
保存していたビューをSQL1行で実行

グラフ化もすぐにできます
(任意)自動化の方向性
今回の手順では、クエリ履歴を手動で集計し、上位 3 件をビュー化しました。
実際の運用では、これを 定期的に自動化するとさらに便利になります。
-
Notebook + Job
Python / SQL を組み合わせた Notebook を作成し、以下のように自動実行することも可能です。-
system.query.historyから直近の頻出 WHERE 句を抽出 - 上位 N 件を
CREATE OR REPLACE VIEWで更新
-
-
承認フロー
いきなり自動更新せず、Slack や Teams へ「候補のクエリ条件」を通知し、
チームで承認したものだけをビュー化する仕組みにすることも可能です。 -
パフォーマンス最適化
頻出ビューが重たい場合は、以下のような機能を組み合わせて負荷を下げる工夫も考えられます。- マテリアライズドビュー
- CTAS(Create Table As Select)での派生テーブル
- 定期リフレッシュ
まとめ
本記事では、Databricks の Query History を活用して、
よく使われるクエリ条件を特定し、View として整理する流れを紹介しました。
ポイントは、「みんなが実際に使っているクエリ」をデータドリブンに抽出できることです。
「よく使うWHERE句を“暗黙知”にせず、組織の資産にする」ことで、
チームの分析効率やガバナンスを一段階引き上げることができます。

Discussion