ゴール
目的
Delta Live Table内のダミーデータに対して、Lakeflow 宣言パイプライン を用いて、
UC Volumes からの取り込み〜配信テーブル管理の基本を掴みます。
できるようになること
- UC Volumes にダミーデータを書き出す
- Auto Loader で増分取り込み(Bronzeテーブルの作成)
- 取り込みデータにデータ品質ルールを適用(Silverテーブルの作成)
- AUTO CDC で最新スナップショット化と履歴化(Goldテーブルの作成)

完成イメージ:左からBronze、Silver、Gold×3
参考
こちらのチュートリアルを参考に実行しています。
チュートリアル
0: ダミ―データを生成する
まずは今回使用するダミーデータを作成します。
faker ライブラリが未インストールだとエラーになりますので、
最初のセルで %pip install faker を実行してください。
ダミーデータ生成用コード
# 事前にライブラリを入れておくと確実
# %pip install faker
# カタログ/スキーマ/ボリューム名(以降もずっと同じ名前を使います)
catalog = "workspace"
schema = dbName = db = "dbdemos_dlt_cdc"
volume_name = "raw_data"
spark.sql(f'CREATE CATALOG IF NOT EXISTS `{catalog}`')
spark.sql(f'USE CATALOG `{catalog}`')
spark.sql(f'CREATE SCHEMA IF NOT EXISTS `{catalog}`.`{schema}`')
spark.sql(f'USE SCHEMA `{schema}`')
spark.sql(f'CREATE VOLUME IF NOT EXISTS `{catalog}`.`{schema}`.`{volume_name}`')
volume_folder = f"/Volumes/{catalog}/{db}/{volume_name}"
try:
dbutils.fs.ls(volume_folder+"/customers")
except:
print(f"folder doesn't exists, generating the data under {volume_folder}...")
from pyspark.sql import functions as F
from faker import Faker
from collections import OrderedDict
import uuid
import random
fake = Faker()
fake_firstname = F.udf(fake.first_name)
fake_lastname = F.udf(fake.last_name)
fake_email = F.udf(fake.ascii_company_email)
fake_date = F.udf(lambda:fake.date_time_this_month().strftime("%m-%d-%Y %H:%M:%S"))
fake_address = F.udf(fake.address)
operations = OrderedDict([("APPEND", 0.5),("DELETE", 0.1),("UPDATE", 0.3),(None, 0.01)])
fake_operation = F.udf(lambda:fake.random_elements(elements=operations, length=1)[0])
fake_id = F.udf(lambda: str(uuid.uuid4()) if random.uniform(0, 1) < 0.98 else None)
df = spark.range(0, 100000).repartition(100)
df = df.withColumn("id", fake_id())
df = df.withColumn("firstname", fake_firstname())
df = df.withColumn("lastname", fake_lastname())
df = df.withColumn("email", fake_email())
df = df.withColumn("address", fake_address())
df = df.withColumn("operation", fake_operation())
df_customers = df.withColumn("operation_date", fake_date())
df_customers.repartition(100).write.format("json").mode("overwrite").save(volume_folder+"/customers")
| address | firstname | id | lastname | operation | operation_date | |
|---|---|---|---|---|---|---|
| "5252 Margaret Key Suite 828\nMarybury..." | skaufman@pierce.org | Kimberly | 6bef15f7-a9f8-4731-9ec3-34646cdfda0c | Norman | UPDATE | 09-03-2025 06:12:35 |
| "2483 Robert Camp Apt. 425\nSouth..." | ramosbrian@paul.biz | Brittany | e39a109c-d5b9-466e-8fb1-d4714d9e9808 | Garza | DELETE | 09-02-2025 17:01:58 |
| "0936 Phillips Turnpike\nBrianfort..." | urich@cook-fleming.com | Christopher | 95a1...b1bd | Davis | APPEND | 09-01-2025 06:08:49 |
できたテーブル先頭3行はこんな感じ。
生データ相当の購入顧客テーブルと思っていただきたいです。
こんな感じの行が10000行あります。
1: パイプライン作成
次にパイプラインを作成します。
- パイプライン名:任意(ここでは
0904-pipeline-test) - パイプラインモード:トリガー(まずは手動実行でOK。後でスケジュールに変更可)
- 変換先(配信先):0で作成したカタログ/スキーマ(例:workspace.dbdemos_dlt_cdc) を指定
- ソースコード:本記事のコードを置いたノートブックを指定(例:/Users/ユーザー名/0904test/0904-pipeline-test)

2: 自動ローダーを作成(Bronze)
ここでは Auto Loader(自動ローダー) を使って、
ステップ0で作成した Volumes上のダミーデータをストリーミングテーブルに取り込みます。
データ基盤の世界では、このように外部から取り込んだ「加工前の生データ」を Bronze層 と呼びます。
特徴は以下の通りです。
- 目的:データを欠損や整形をせず、そのまま安全に保持する
- 利点:履歴をそのまま残せるため、後から検証や再処理に利用できる
Auto Loaderはストレージを監視し、新しいファイルが追加されると自動的に取り込んでくれる仕組みです。大量のファイルや継続的な更新を扱う場合、従来の単純な read.json より効率的かつ堅牢なのが特徴です。
以下をソースコードのノートブックに記述し、パイプラインを実行すると、
customers_cdc_bronze という Bronzeテーブル にデータが取り込まれます。
`customers_cdc_bronze`の作成
from dlt import *
from pyspark.sql.functions import *
# Bronze: 生データの取り込み先(ストリーミングテーブル)
dlt.create_streaming_table(
"customers_cdc_bronze",
comment="New customer data incrementally ingested from cloud object storage landing zone"
)
# Auto Loader で Volumes の JSON を読み取る
@append_flow(
target = "customers_cdc_bronze",
name = "customers_bronze_ingest_flow"
)
def customers_bronze_ingest_flow():
return (
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
# 0. の設定と合わせる
.load("/Volumes/workspace/dbdemos_dlt_cdc/raw_data/customers")
)

パイプラインを実行するとこんな感じで処理が進む

成功したらこんな感じ。ちょっと先まで作っているのはスルーいただいて
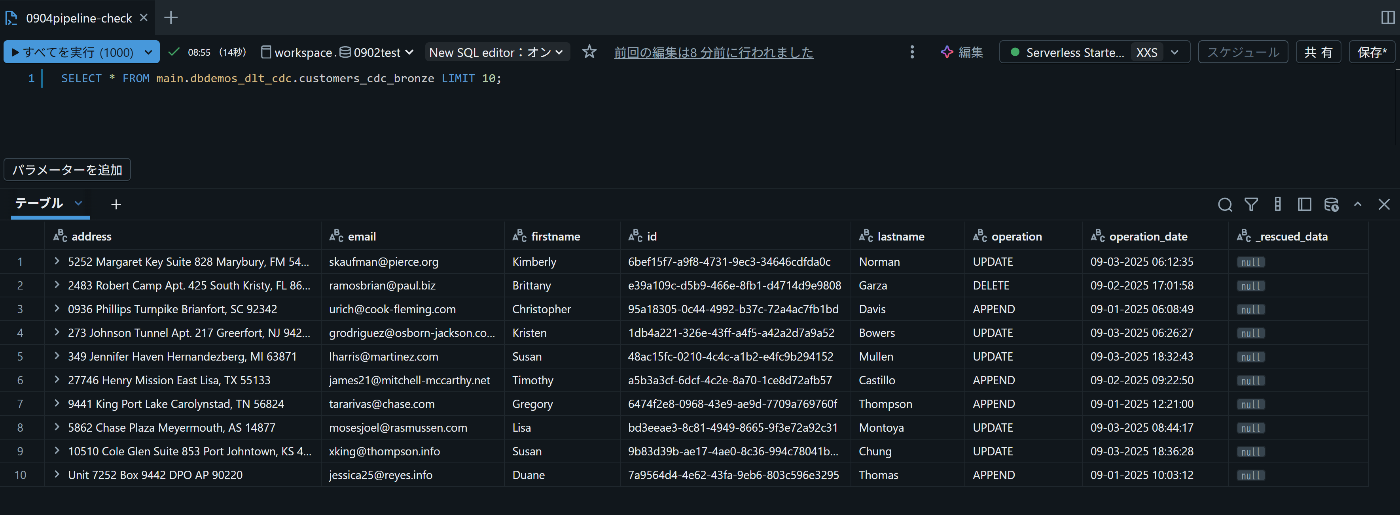
クエリで確かめるとブロンズっぽいとわかる
この段階ではまだ「生データそのまま」で、不正値や欠損も含まれており、
「ダミーデータをそのままDeltaテーブル化した状態」 です。
3: データをクリーンアップ(Silver)
次は Bronzeテーブルに取り込んだ生データをクレンジングして、Silverテーブルを作成 します。
ここではデータ品質を守るために 「期待値(Expectations)」 を定義し、条件に合わない行は自動的に除外します。
具体的には次のルールを設定します。
-
IDが存在すること(id IS NOT NULL) -
操作タイプが有効であること(
APPEND / DELETE / UPDATEのいずれか) -
JSONが正しく読み取られていること(
_rescued_data IS NULL)
この処理により、欠損や不正値を含んだ行は削除され、CDC処理に耐えられるクリーンなデータセット になります。
ここで、「生ログ(Bronze)」から「利用可能なデータ(Silver)」になる ということです。
以下のコードを実行すると、customers_cdc_clean が作成されます。
`customers_cdc_clean`の作成
dlt.create_streaming_table(
name = "customers_cdc_clean",
expect_all_or_drop = {
"no_rescued_data": "_rescued_data IS NULL",
"valid_id": "id IS NOT NULL",
"valid_operation": "operation IN ('APPEND', 'DELETE', 'UPDATE')"
}
)
@append_flow(
target = "customers_cdc_clean",
name = "customers_cdc_clean_flow"
)
def customers_cdc_clean_flow():
return (
dlt.read_stream("customers_cdc_bronze")
.select("address", "email", "id", "firstname", "lastname", "operation", "operation_date", "_rescued_data")
)
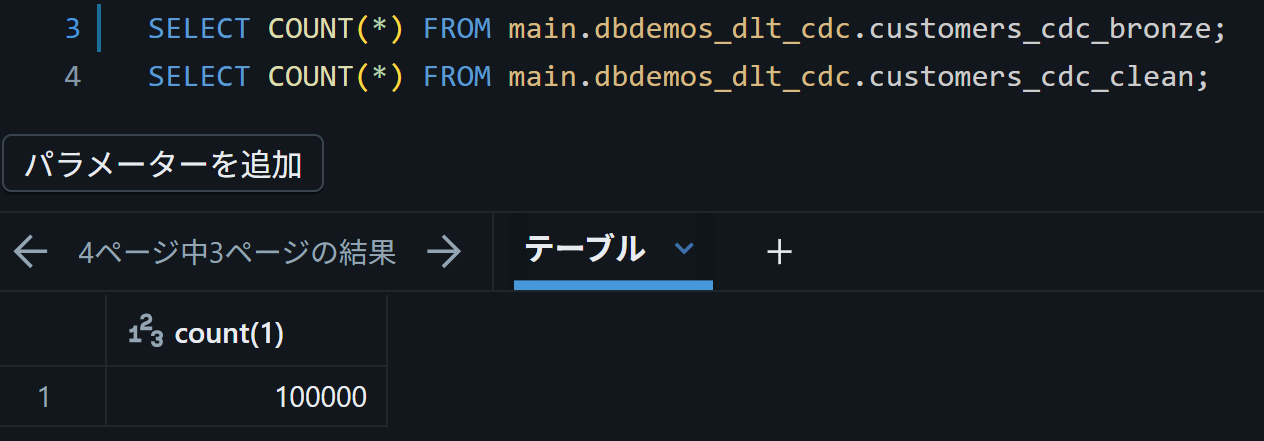
ブロンズテーブルのレコード数は10000あったが…
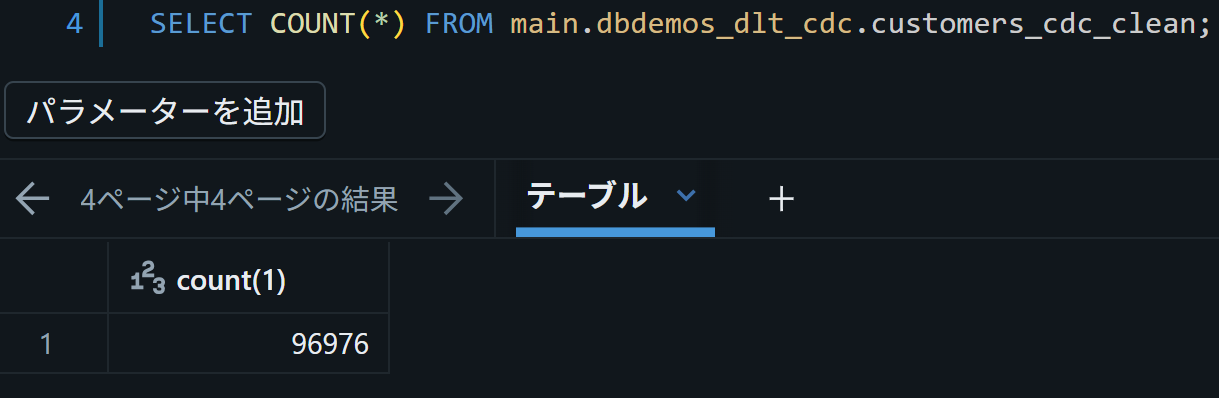
シルバーテーブルになる過程で3000くらい除かれた
4: AUTO CDCで最新データのみ抽出(Gold-1)
ここでは、最新状態の顧客テーブル(customers) を構築します。
CDCデータには「追加(APPEND)」「更新(UPDATE)」「削除(DELETE)」が混在しているため、
単純に取り込むだけでは 重複や古い値が残ってしまう ことがあります。
これを使いやすくするために利用するのが AUTO CDC フロー です。
AUTO CDC は、Databricksの機能のひとつで、
Change Data Capture(CDC:変更データ捕捉)を自動処理する仕組み です。
Databricks Lakeflow 宣言パイプラインに組み込まれており、
以下のようなことを自動で行ってくれます。
- 主キー(ここでは
id)を基準にレコードを照合 -
operation_dateを使って最新の行を特定 -
DELETE指定された行を除去
結果として、customers テーブルには「常に最新の顧客データ」が保持されます。
つまり、「SilverのCDCデータ → 最新スナップショット」 という変換を担うのがこのステップです。
以下のコードを実行すると、customers というストリーミングテーブルが作成されます。
`customers`の作成
dlt.create_streaming_table(name="customers", comment="Clean, materialized customers")
dlt.create_auto_cdc_flow(
target="customers", # マテリアライズ先(最新の顧客スナップショット)
source="customers_cdc_clean", # 入力(クリーン済みCDCデータ)
keys=["id"], # 主キーでマッチング
sequence_by=col("operation_date"), # operation_dateで最新を判定
ignore_null_updates=False,
apply_as_deletes=expr("operation = 'DELETE'"), # DELETE操作を削除として適用
except_column_list=["operation", "operation_date", "_rescued_data"],
)
できたcustomersテーブルはこんな感じ。
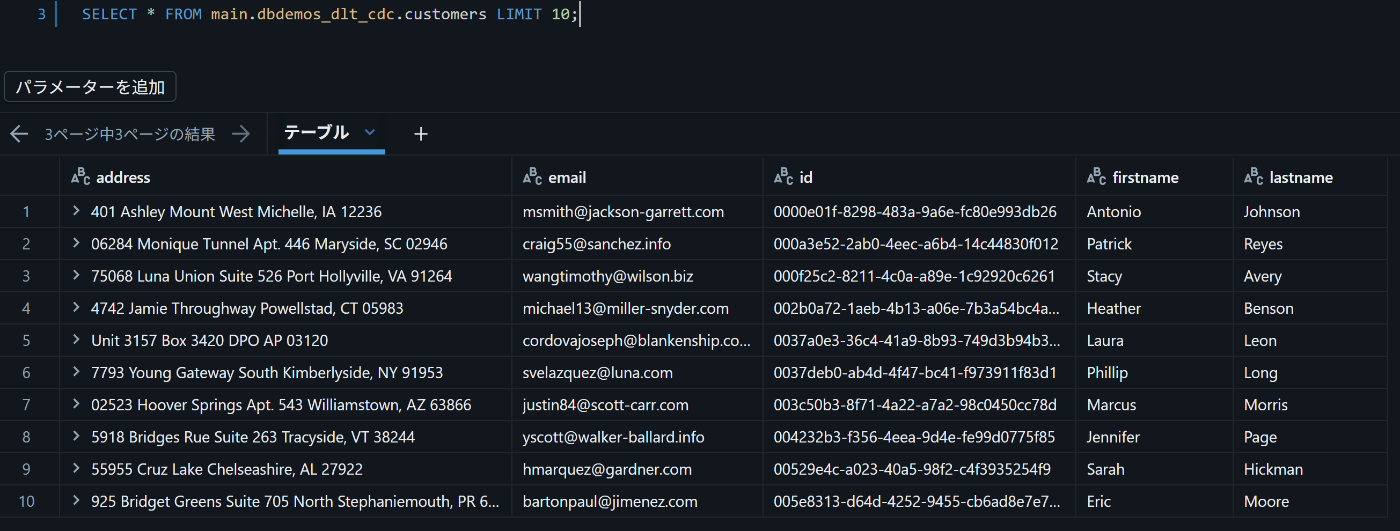
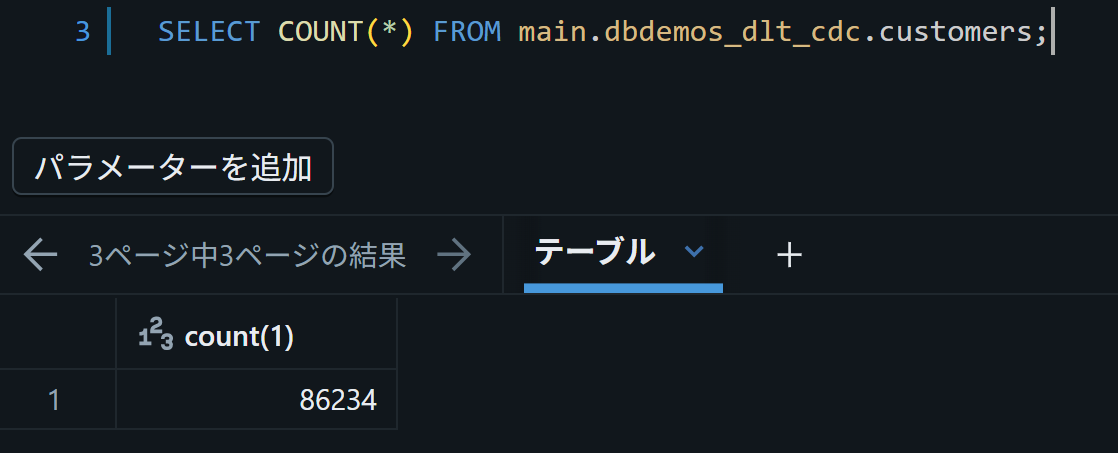
同じ顧客の重複分が除かれたので、レコード数も減っている
Silverテーブルまでは複数購入している顧客IDに対しては複数のレコードが混在していましたが、
この作業により最新のレコードのみになりました。
5: SCD Type 2 で全ての変更履歴を保持(Gold-2)
次に2つ目のGoldテーブルとして、 すべての変更(APPEND / UPDATE / DELETE)を履歴として保存するテーブル を作成します。
AUTO CDC の stored_as_scd_type="2" を指定すると、以下を自動で処理してくれます。
- 主キーごとに 有効期間(開始・終了時刻) を付与
- 現在フラグ を付与し「今のレコード」かどうかを判別
-
sequence_byの時系列に基づき、順序が乱れたイベントも正しく整理
ここでいう変更履歴とは、顧客データが時間とともにどう変わったか を一件ずつ記録したものです。履歴を保持することで、次のような分析や確認が可能になります。
-
特定の顧客の履歴を追跡
例:「この顧客はいつ住所が変更されたのか?」 -
任意の時点の状態を再現
例:「2025-09-02 時点ではこの顧客の住所は何だったか?」 -
複数の時点を横並びで比較
例:「2023年と2024年でこの顧客の住所はどう違っていたか?」
`customers_history`の作成
# 履歴テーブル(SCD2)を作成
dlt.create_streaming_table(
name="customers_history",
comment="Slowly Changing Dimension Type 2 for customers"
)
# すべての変更をSCD2として保存
dlt.create_auto_cdc_flow(
target="customers_history",
source="customers_cdc_clean",
keys=["id"], # 変更追跡の主キー
sequence_by=col("operation_ts"), # 時系列整合(ステップ③で作成)
ignore_null_updates=False,
apply_as_deletes=expr("operation = 'DELETE'"),
except_column_list=["operation", "operation_date", "_rescued_data", "operation_ts"],
stored_as_scd_type="2", # SCD Type 2 を有効化
) # 以後、開始/終了時刻や現在フラグなどを自動管理
「2025-09-02 12時に、どの顧客がどの住所を持っていたか」を表示させるとこんな感じです。

6: ユーザーごとの変更回数を集計(Gold-3)
customers_history テーブルには、各顧客が自分の情報に加えたすべての変更履歴が含まれていましたが、最後にそれを集計して、
どの顧客がどの項目を何回変更したか を可視化するビューを作成します。
以下のようなシナリオで役立ちます。
- 不正行為の検出:特定のユーザーだけが異常に頻繁に情報を変更していないかチェック
- レコメンデーション:入力項目の変化が多いユーザーに対して、改善提案や推奨設定を提示
- データ品質分析:どの項目が頻繁に変わっているかを把握し、システムや入力UIの改善につなげる
SCD2を適用した customers_history では重複がすでに整理されているため、
ユーザーIDごとにカウントするだけで簡単に集計できます。
集計ビューの作成コード
@dlt.table(
name = "customers_history_agg",
comment = "Aggregated customer history"
)
def customers_history_agg():
return (
dlt.read("customers_history")
.groupBy("id")
.agg(
count("address").alias("address_count"),
count("email").alias("email_count"),
count("firstname").alias("firstname_count"),
count("lastname").alias("lastname_count")
)
)
まとめ
データの取り込みからクレンジング、最新化、履歴管理、集計までを自動化した基本的なパイプラインを体験しました。
Engineer Associateの資格で学んだ範囲でもあるのですが、やはり手を動かすとわかることも多いと思います。
本当はジョブのスケジューリングなどもしようとしたのですが、今回はちょっと文章が長くなり過ぎたので次回以降にしたいと思います。

Discussion