目的
この記事でできるようになること
Databricksを用いて、
- 数百列 × 数千行のデータから、欲しいの情報を瞬時に切り出せるようになる
- 最新の予測データを取り出し、過去実績との比較グラフを作れるようになる
完成イメージ
- X軸:日付(今日は2024年7月11日くらいと思ってほしいです)
- y軸:気温
- 予測データ:2024年7月26日
- 実績データ:~2024年7月10日
- 折れ線:大阪市の各日の気温
- 青:最高気温
- 黄:最低気温

扱いやすかっただけで、本来気温に対してこんなことする意味はあまりないのですが、
(徐々に暑くなっていく7月を眺めるだけ…)
例えば何かの発注量や消費量、人口など、
「トレンドを掴むことに意義のあるデータ」を当てはめてイメージいただきたいです。
準備
すべてFree Editionで実行しています。
無料で操作感などを試せます。
対象データ
Databricksのワークスペースにデフォルトで存在している「受け取ったDelta共有」の
以下2つのsampleデータを使用します。
-
historical_daily_calendar_metric(実績)- 概要:2024/6/27~2024/7/11の期間における、合計43都市の気象データ実績が含まれています。気象データには、雲量、気温、度日、湿度レベル、降水量、風速などが含まれます。
- 行数:800
- 列数:108
-
forecast_daily_calendar_metric(予測)- 概要:2024/7/12~2024/7/26の期間における、合計43都市の気象データ予測が含まれています。気象データには、雲量、気温、度日、湿度レベル、降水量、風速などが含まれます。
- 行数:750
- 列数:264
そこまでビッグデータではないですが、とにかく列数が多いですね。
なぜか予測データには2倍以上の列があるのですが、今回は扱わないので置いときます。
ちなみにデフォルトのスキーマ(samples.accuweather)のままだと編集ができないので、
自分のワークスペースにコピーする必要があります。
このあたりの事前準備はDatabricksのAIチャットGenieを上手く活用しましょう。
テーブル情報など、色々教えてくれます。
出力イメージ

Databricks SQLで最新予報と過去実績を扱うビューを作る
0. Databricks SQLのビューとは
Databricks SQLにおける ビュー (VIEW) は、テーブルのデータを基にした「仮想的なテーブル」のことです。
ビューそのものはデータを持たず、あらかじめ書いた SELECT文の結果を呼び出せる仕組み です。
-
再利用できるSQL
毎回同じSELECTを書く代わりに、ビューを作っておけばSELECT * FROM v_latest_forecast;のように呼び出せる。 -
安全にデータを扱える
元のテーブルを直接触らずに加工・抽出できるので、データを壊さない。 -
フィルタリングや結合をあらかじめ仕込める
例えば「最新日付だけ」「大阪市だけ」「必要な列だけ」といった条件を組み込んでおける。
今回はこのビューを使って、「最新予報ビュー」「予報+実績ビュー」を作り、大量データから欲しい部分だけ抽出する便利さを体験します。
1. 最新予報ビューを作る
まずは「予測テーブルの最新日だけ」を返すビューを作ります。
SQLエディターで以下のクエリを実行します。
-- 最新予測の取得ビュー
CREATE OR REPLACE VIEW workspace.0902test.v_latest_forecast AS
SELECT *
FROM workspace.0902test.forecast_daily_calendar_metric
WHERE date = (SELECT MAX(date)
FROM workspace.0902test.forecast_daily_calendar_metric);
- ビュー名は
v_latest_forecast -
VIEWは「SELECTの結果」を再利用できる仮想テーブル - サブクエリでテーブル全体の
MAX(date)を求め、最新日に一致する全都市分のデータを取得する
出力イメージ
成功したらOKと出力されます

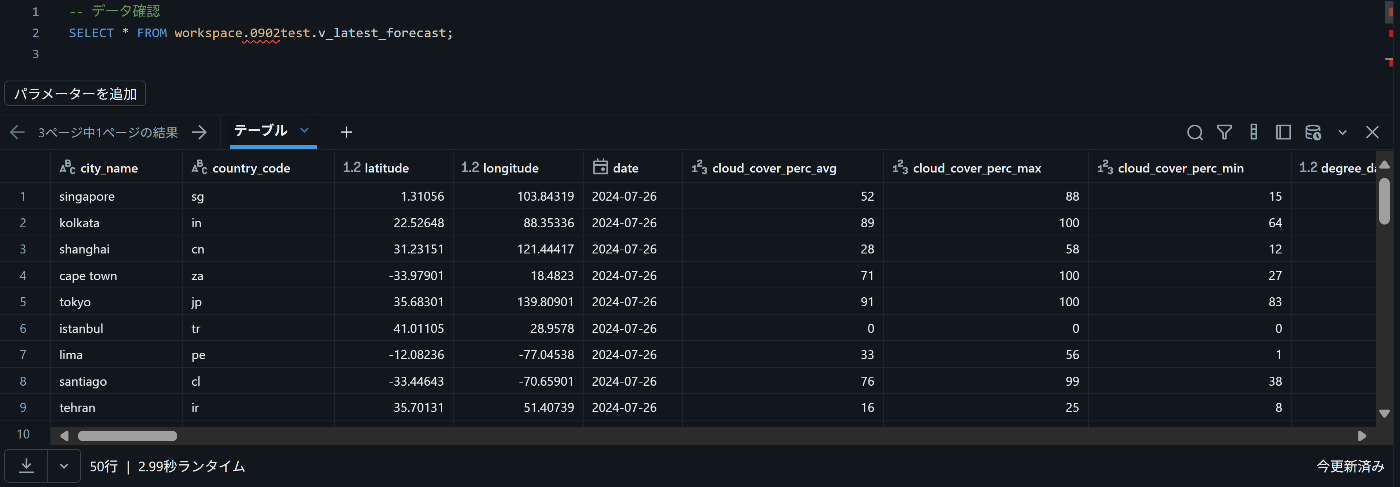
2. ビューを確認
1で作成したビューの中身や定義を確認します。
ビューのデータ確認
-- ビュー v_latest_forecast の中身を確認
SELECT * FROM workspace.0902test.v_latest_forecast;
出力イメージ
各国の7/26のみのデータを取得できています
ビューの定義・概要情報
DESCRIBE EXTENDEDでテーブルの定義を確認できます。
-- ビュー v_latest_forecast の定義を確認
DESCRIBE EXTENDED workspace.0902test.v_latest_forecast;
出力としては、まず列ごとのデータ型が表示され、
その下に # Detailed Table Information という項目があり、
ビューの場所や作成時刻、作成者などのメタ情報が確認できます。
出力イメージ

ビューの実行計画
実行計画とは、SQLを投げたときに、裏側でどう処理するかを示した設計図のようなものです。
Databricksはこの実行計画を基に「どの列を読むか」「どの順番で計算するか」などを最適化して、
高速に処理してくれます。
EXPLAIN COST を使えば、この設計図を確認でき、
「本当に最新日だけを読んでいるか?」などを検証できます。
-- 実行計画の確認
EXPLAIN COST
SELECT * FROM workspace.0902test.v_latest_forecast;
結構長いので省略しますが、概要をまとめると
-
MAX(date)を先に計算 → その日付だけをスキャンする計画になっている。 - 「最新日だけ読む」最短ルートが選ばれていて、無駄読みが避けられて高速
- Databricksの最適化が効いている状態
などのことがわかります。
実行計画の抜粋(折り畳み)
実行計画の抜粋
1) Optimized Logical Plan(論理計画)
Filter (isnotnull(date) AND date = scalar-subquery(...))
Statistics(sizeInBytes=517.1 KiB, rowCount=750)
-
やってること:
MAX(date)(サブクエリ)を先に求め、その値と一致するdateの行だけを残すフィルタ。 - 統計:テーブル推定サイズや行数(ここでは ~517KB / 750行)。コスト見積もりの根拠になる。
2) 「MAX(date)」は軽く解決される
LocalRelation [max(date)]
- サブクエリの結果は 1行だけ なので、ローカルに即時展開(重くない)。
3) Physical Plan(物理計画)
PhotonScan parquet ...
DataFilters: [isnotnull(date), date = Subquery ...]
- PhotonScan:Photon エンジンで Parquet をスキャン。
-
DataFilters:スキャン時点で
date = MAX(date)がプッシュダウンされ、不要データを読まない。
4) Optimizer Statistics
full = forecast_daily_calendar_metric
- 統計情報がそろっているテーブル。最適化判断の精度向上に寄与。
3. 予報&実績ビューを作る
次に「最新予報」と「過去実績」を結合したビューを作成します。
具体的には可視化や集計で扱いやすいよう、
最新予報(1日分) と 過去実績(複数日) を同じ列構造にそろえて 縦に結合 します。
CREATE OR REPLACE VIEW workspace.0902test.v_forecast_vs_actual AS
SELECT
'forecast' AS data_type, -- どちらの系データかを識別
city_name,
country_code,
date AS dt, -- 共通の日時カラム名に統一
temperature_max,
temperature_min,
precipitation_probability, -- 予報の降水「確率」
rain_lwe_total
FROM workspace.0902test.v_latest_forecast
UNION ALL
SELECT
'historical' AS data_type,
city_name,
country_code,
date AS dt,
temperature_max,
temperature_min,
precipitation_lwe_rate_avg AS precipitation_probability, -- 実績側は「降水量レート」を整形して名前合わせ
rain_lwe_total
FROM workspace.0902test.historical_daily_calendar_metric;
これでOKと出力されれば、比較ビューは完成です。
コードのポイントは以下です。
- 列名と並びを統一:
dateをdtに、降水系も 同じ見出し に合わせると、後段の可視化・集計がシンプルになります。この辺りはGenieが勝手に認識してくれて感動しました。 -
UNION ALLを使う理由⇒重複除去コストを避けたい、かつ「予報」と「実績」は性質が異なるため 重複除去しない のが自然でした。(UNIONだと重複が消える) -
data_typeで系列を分ける⇒グラフで色分け/集計でグルーピングが簡単に。
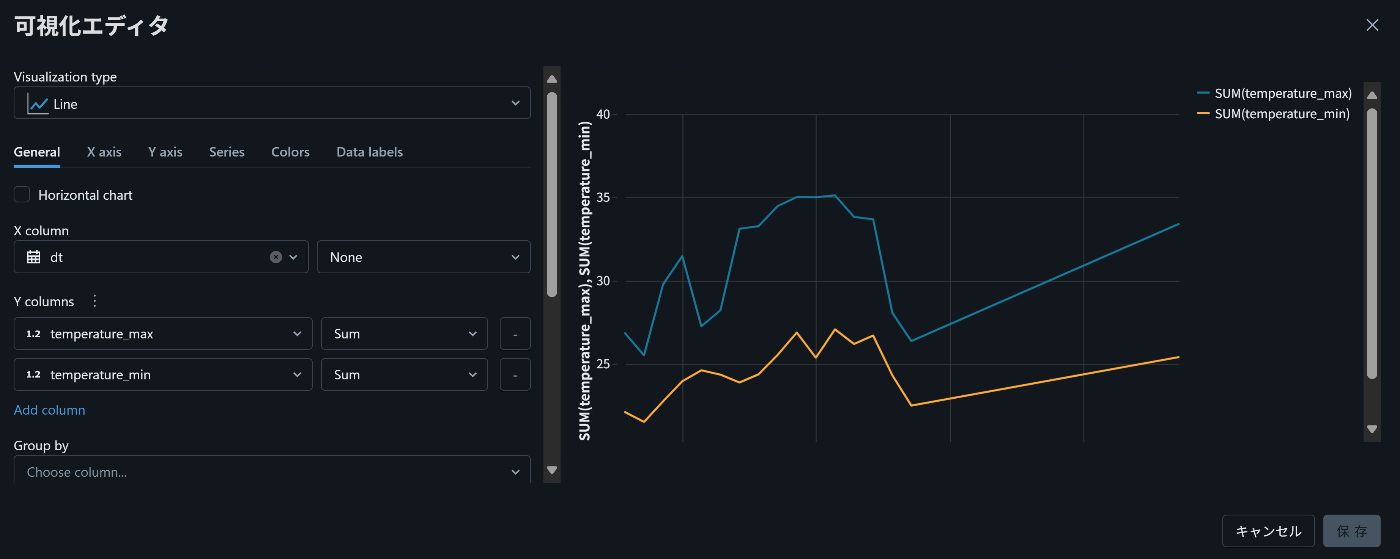
4. 都市ごとのデータを確認・可視化
3で作成したビューを使えば、都市ごとに予報と実績を並べて確認できます。
例えば大阪市を指定すると、最新予報(1行)+過去実績(複数行) が取得されます。
SELECT *
FROM workspace.0902test.v_forecast_vs_actual
WHERE city_name = 'osaka-shi'
ORDER BY dt DESC;
出力イメージ
日付の降順のため、先頭行が最新予報、それ以降が過去実績データ

このデータをそのまま可視化エディターに渡せば、気温や降水傾向などをグラフ化できます。
この辺りは直観的にできて最高です
5. (任意)ZORDERでパフォーマンス改善
データ量が増えると検索速度が気になる場面が出てきます。
そんな時に使えるのがDatabricksの ZORDER です。
よく使う検索キーでデータを並べ替えることで、I/Oを削減しクエリを高速化できます。
OPTIMIZE workspace.0902test.forecast_daily_calendar_metric
ZORDER BY (city_name, date);
OPTIMIZE workspace.0902test.historical_daily_calendar_metric
ZORDER BY (city_name, date);
特に都市+日付での絞り込み
WHERE city_name = 'osaka-shi' AND dt BETWEEN ...
のようなクエリが高速化され、分析やダッシュボードがサクサク動くようになります。
まとめ
今回はDatabricks SQLを用いて以下のことを整理しました。
-
ビューの基本
DESCRIBE EXTENDEDやEXPLAIN COSTを用いて、ビューの仕組みや実行計画を確認 -
実践的な利用
「最新予報」と「過去実績」をビューでまとめ、都市ごとに必要なデータを抽出・可視化 -
パフォーマンス改善
大量データでも都市+日付単位の検索が効率的になるよう、ZORDERを活用
ここからさらに発展させると、より実用的な分析環境になります。
- 誤差分析:予報と実績の差を計算し、都市ごとの予測精度を評価する
- ダッシュボード化:可視化ツールや Databricks SQL ダッシュボードで、予測と実績を一目で比較できる仕組みを作る
- 自動化:定期的にビューを更新し、毎日の最新予報と直近の実績を常に参照できるようにする
とても便利かつ難しくないので触っていても楽しいのですが、
強いて言えばできることが多すぎてどこから手を付けていいのやら~となりそうな気がします。
検証繰り返してそれぞれの業務に合った活用法を探したいですね。

Discussion
FreeEditionの制約事項などを追記しました。