執筆日
2025/08/10
追記: 2025/08/11
概要
2025/08/08についにOpenAIからGPT-5が発表されました。
個人的にはGPT-4.5やGPT-4.1を使ったときは賢いけど使いづらい、安くて使いやすいけどLLMとしての進歩はあんまり?という印象だったので、その辺りが解消されたメジャーアップデートになっていると嬉しいなと思っていましたが、まさにそんな感じの発表内容でした。メジャーアップデートということで色々と新機能も沢山追加されていてしゃぶりがいがありそうな内容でしたので、特に気になった点を気ままに語っていこうと思います。今回はエンジニア・非エンジニア問わず読めるコードレスな内容です。
(自分が気になったところだけピックするので全網羅はしません(LLMに要約させたんじゃなくてちゃんと読んだよアピール))
値段
個人的には最新モデルが出ると毎回これが一番最初に気になってしまいます。モデル変更の提案をするとき安いと提案しやすいし、自分でテストする時もバリバリ使ってみるぞ~という気持ちになります。逆に高いとそれだけで性能度外視で触る気もなくなってしまいます。
気になる結果は……デデン!安い!!うれしい!!!
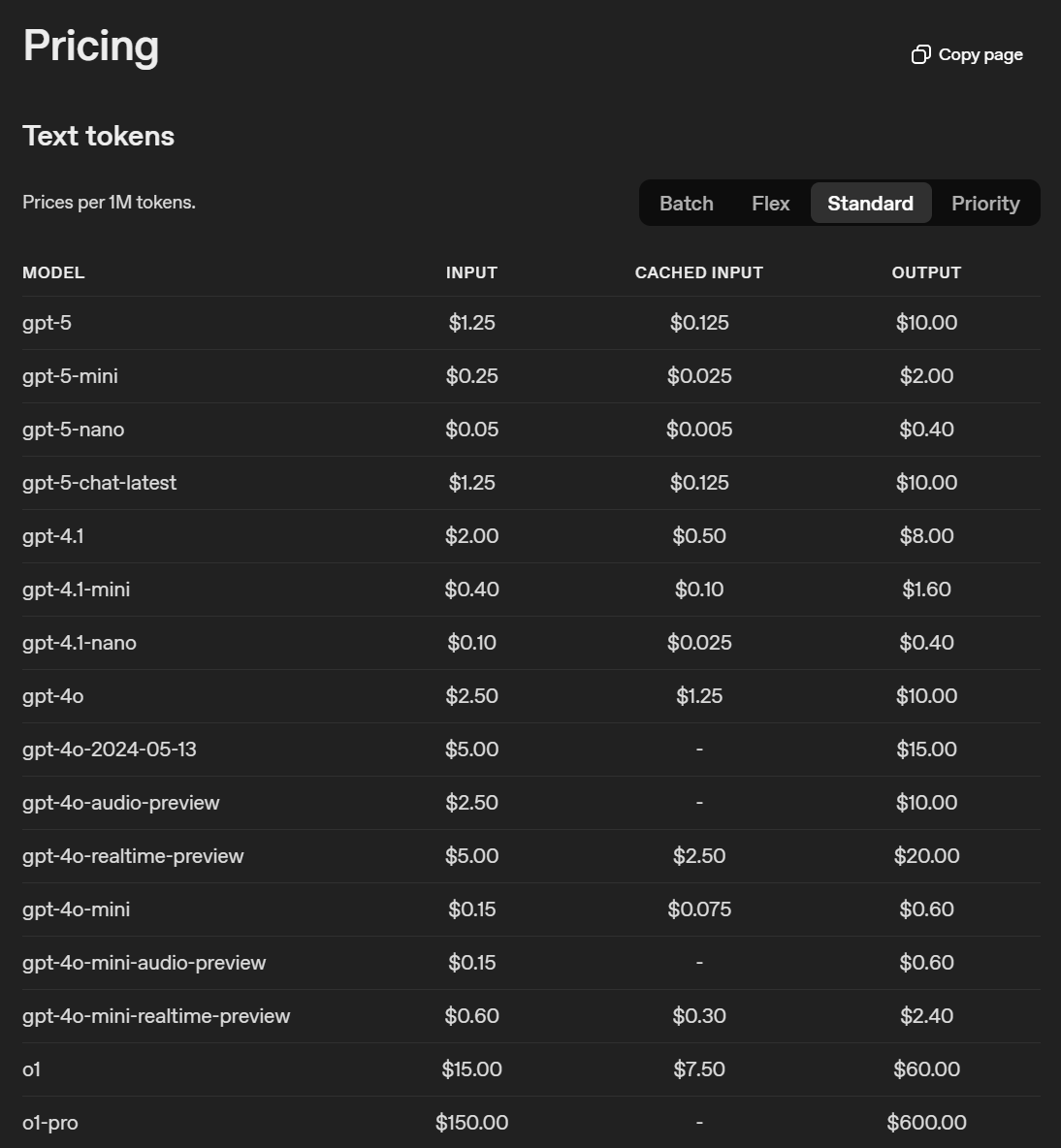 なんと入力トークンは
なんと入力トークンはGPT-4oから半額、GPT-4.1の5/8で圧倒的な安さです。出力トークンはGPT-4.1が少し安いですが、RAGの開発という観点では圧倒的に入力の分量が多いためRAG開発者には朗報です。ただ、口述しますがGPT-5はデフォルトが推論モードなのでその場合は出力も結構使います。ただ従来の推論モデルと比べて圧倒的に安いです。
というわけで値段を確認して使いたい気持ちが湧いたところで、ここからが本題になります。
情報ソース
主要な情報はOpenAIのNewsから以下を確認するのが良いと思います。
- GPT-5 モデル紹介
- GPT-5 開発者向けモデル紹介
- GPT-5 システムカード
- GPT-5 の安全性について: モデル回答の安全性について紹介されています。今回はこれ以上触れませんので気になる方はご確認ください。
GPT-5について(一般向け)
OpenAI CEO サム・アルトマン氏のツイート(Grokによる翻訳)より、
GPT-5はこれまでで最も賢いモデルですが、私たちが最も重視したのは、現実世界での有用性と大規模なアクセシビリティ/手頃な価格です。
もっともっと賢いモデルをリリースすることはできますし、実際にそうする予定ですが、これは10億人以上の人々が恩恵を受けるものです。
(世界のほとんどの人は、GPT-4oのようなモデルしか使っていません!)
ということで、GPT-5はモデルの賢さを上げてはいるものの、重視していることは多くの人に身近に使ってもらえるモデルにすることであるということです。GPT-4oに比べて賢いはずのo3のような推論モデルが多くの人にとって使いづらいモデルであったことを問題視しているようですね。他にも良いモデルの定義は個人個人で違うためユーザーに最適化が出来るようなモデルにすることも大事みたいなことを言っていた気がします。
GPT-5 モデル紹介に書いてある内容はGPTの大まかな性能や性質について、WebやアプリからアクセスするChatGPT上でのモデルの内容についてです。
リアルタイムルーター
ChatGPT上のGPT-5はユーザーの質問内容に応じて効率的なチャットモデルと深い推論が必要な思考モデルを自動で切り替える機能を内蔵しています。(以降このブログ上では非推論モデル・推論モデルと呼びます)すべての質問に対して時間をかけて推論するような無駄を回避することでより使いやすいモデルにしたいという狙いがあるのだと思っています。
GPT-5の思考能力
o3モデルとの比較でパフォーマンスを向上しつつ、途中のトークン利用量も50-80%削減され無駄な思考を必要とせず答えを導き出せるようなっているようです。ソフトウェアエンジニアリングの比較グラフを見ると、o3が一番深い推論で約14000トークンを使って出す答えより、GPT-5が一番浅い推論で約4000トークン使って出す答えの方が精度が高いという結果が出ています(これは元々GPT-5がエンジニアリングに強いという性質もあるため推論力比較としてはフェアではないかもしれませんが)。

Proモデルのリリース予定
具体的にいつとは明言されていませんが、さらに深く強力な推論が出来るGPT-5 proもリリースされる予定のようです。
追記: 既にChatGPTで使えるようです(ProユーザーのみのためPlusユーザーの私は使えませんでした……)
システムカードより
GPT-5 システムカードでは、既存のモデルとの互換性についてまとまっています。現状システムで使っているモデルを置き換えたい場合はこちらを参考にするのが良いでしょう。とはいえ、モデルの回答性質は完全には同じではないのでガチガチプロンプトチューニングしているシステムではモデルの置き換えは慎重に性能チェックをしたいです。またPDFを開けば実際のベンチマークテストの結果比較を確認できます。(ハルシネーションスコアとかもまとまってるので定量的な紹介がしたい場合はこちらを参考にするとよいでしょう)

(miniやnanoの置き換えがthinkingしかないのは軽量モデルに回答速度を期待している人からするとどうなんだろう……?GPT-5-mini, nanoの回答速度検証もしたい)
GPT-5について(開発者向け)
GPT-5 開発者向けモデル紹介は実際にAPIやSDKを使って開発を行う人向けの情報が多いです(とはいえマネジメント側の方もある程度目を通して欲しい内容ではあります)。
APIから使えるモデルの種類
4種類のモデルが選択できます。ChatGPTでのGPT-5は推論・非推論モードを自動で切り替えるルーターモデルですが、APIで呼び出されるGPT-5はchatが付いているモデル以外は推論モデルとして機能します。
GPT-5GPT-5-miniGPT-5-nanoGPT-5-chat-latest
この中では、GPT-5-chat-latest(latestが付いている辺り、マイナーアップデートが今後ありそう)が非推論モデルなので一般的なチャットbotの構築をする場合は、レスポンス重視でGPT-4oやGPT-4.1をこちらに置き換えて使うのが良いでしょう。
AgentやRAG開発で重要なスコアたち
GPT-5とo3, GPT-4.1を比較した棒グラフが出ていますが、GPT-4.1だけ非推論モデルなことには注意してください。(比較対象としてちょっとアンフェア)
ロングコンテキスト解釈
3.2万トークン以上で顕著に過去のモデルよりロングコンテキストを正確に読むことが出来ています。(というか過去モデルって思っていた以上に1万トークン程度でもコンテキストから外れた回答してしまう感じだったんだなと改めて確認できました……)

ちなみにGPT-4.1発表時のGPT-4oとの比較を見るとどれだけハルシネーション改善が進んだかより明確になります。(GPT-5の数値が高すぎてちょっと疑心暗鬼になりますが……)

指示追従性(intoroduction following)
最高の指示追従性があります。RAGやる上で必要不可欠な能力なので上がれば上がるほどうれしい。

適切なtool選択
tool呼び出しのベンチマークでは一部タスクで圧倒的なスコアを出しているようです。あまり変わらないものもあるため過度な期待はしない方が良いですが、着実にtool呼び出しの性能も上がっていますね。適切なtool選択はAgent開発において非常に重要になります。

事実認識(Factuality)
事実確認の信頼性が以前の推論モデルと比べて非常に高くなりました。というかo3ってこんなにハルシネーションキツかったのか……こわ。ユーザーを介さず推論を繰り返しているうちに前提を忘れてしまっていたんでしょうか。

新しい自由なtool形式
今までのカチカチJSON出力とは違うより自由な形式の出力固定化の方式みたいなものです。
弊社メンバーの竹川さんが早速コードやSQLの生成を試しています。
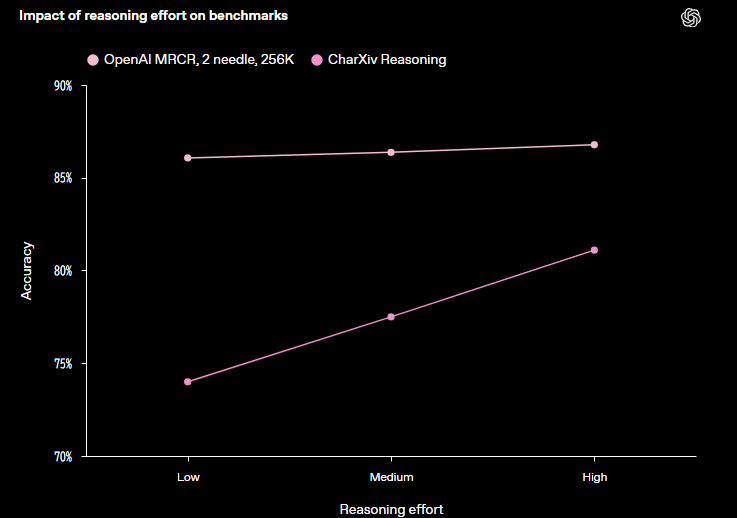
推論努力パラメータ(reasoning_effort)
推論モデルではどれくらい推論を頑張るかをパラメータで変更できます。タスクの難しさに応じてlow, medium, high, minimalの4段階調整が出来るようです。2つベンチ結果が載っていますが、簡単なタスクであればパラメータ依存が低く、難しいタスクの場合はパラメータ依存が大きくなっているのを確認できます。(minimalが載っていないけど本当にあるのか?)
回答の冗長性パラメータ(verbosity)
3段階(low, medium, high)で回答の冗長性を変更できます。プロジェクトで回答の長さや丁寧さにコメントをもらうことがまあまああると思いますが、プロンプトエンジニアリングではなくとりあえずこのパラメータを変更するところから始められるのはかなり便利なんじゃないかと思います(プロンプトエンジニアリングのふわっとした検証ではなく、「元々の機能でこれくらい変わります!」と言えるのは強い)
その他
公式の発表内容とは別に開発者にとってうれしい話
Azure OpenAI で使える
早速Azure AI Foundryで本家OpenAIで使えるのと同じ4種類のモデルデプロイが可能になっていました。HWS的にはこれがないと始まらないので即日対応ありがたいです。最近発表されたmodel router(画像の一番上にあるやつ)を使えばChatGPTと同じようにユーザーの質問に応じて推論・非推論モードの自動切換えも実現できます。

Github Copilot Chat で使える
コーディングモデルとして飛躍的に成長していることが明言されているのでこれが出来ないと話にならない時代になっていますが、早速設定できるようになっていました。ありがたい。
発表当日軽く触ってみた感じは賢いものの、レスポンス速度的にGPT-4.1を使った方が良いし、トークン利用割合がClaude-4-Sonnetと同じ割合だったのでう~~むという感じ……。(レスポンス速度は発表直後でAPIが込み合っていただけの可能性もありますが)
感想
GPT-5はAGI(汎用人工知能)を目指すような話が過去にあった気がしますが、実際に発表を見た感じでは今回はまだその段階ではないと思います。
しかし、AGIに向けて着実に必要な能力をGPTに追加する努力がされているのをヒシヒシと感じる内容だなと思いました。特にo3やGPT-4.5辺りでは賢さを向上させるところに全振りであるように感じましたが、今回のGPT-5はより便利に・ユーザーフレンドリになるようなアップデートを目指しているように感じました。
個人的には人間がLLMに歩み寄るべきだと思っているのですが、OpenAIのLLM開発はユーザーに歩み寄る方向性の開発も積極的にしているんだなと感じました。(サム・アルトマン氏の「もっともっと賢いモデルをリリースすることはできますし、実際にそうする予定ですが、これは10億人以上の人々が恩恵を受けるものです。」という発言からもそれが伝わってきます)
GPT-5 使っていきましょう!
追記: モデル発表後の反応
システムカードのところでも軽く言及しましたが、モデルの性質の変化は利用者にとって結構影響するという良い話題が出ていました。いくつかのWeb記事で言及されているのを見かけたのですが、一部のユーザーはGPT-4oと良い関係を築き過ぎていたため、GPT-5の簡素な返答に困惑しているようです。
OpenAIが大規模言語モデル(LLM)の新モデル「GPT-5」をリリースした。コーディング性能の向上やハルシネーション(幻覚)の抑制などの進化が強調されている一方で、従来モデル「GPT-4o」のアクセスが制限されたことに対し、SNS上で「#keep4o」ハッシュタグが話題となっている。ユーザーからは「暖かさや共感力が失われた」との声もみられる。
このような状況に対し、サム・アルトマン氏はこれは個人の見解であり、OpenAIの公式声明ではないとしつつも以下のようなツイートをしていました。(結構長文です)
「モデルへの愛着による心理的影響」「AIとの関係性の健全性」「社会的影響への責任」のような点について言及されており、人とAIが関わることが当たり前になった時代のAI開発の問題について慎重に考えなければならない段階にきていることを語っています。
エンジニアとしては、回答の傾向が大きく変わることによるお客様の満足度が変わることに対する不安はありますが、やはり総合的に判断すると最新モデルをどんどん導入していきたいという気持ちです。
AI全般の発展を見守る一個人としては、AI開発がこんなことを考慮しなければならない段階に来たことに対する、「現実がSFに一歩近づいた感」にすごくワクワクしています。

Discussion