

やってみること
OpenAI Python SDKを使用して、Fabric の Azure OpenAI を使用してキー フレーズ抽出を行う
手順
- Microsoft Fabric(https://app.fabric.microsoft.com/home)にアクセス

- 「Synapse Data Engineering」をクリック

- 「ワークスペース」をクリック

- 作業を行うワークスペースをクリック

- 「+新規」をクリック

- 「ノートブック」をクリック

- ノートブックが開くことを確認

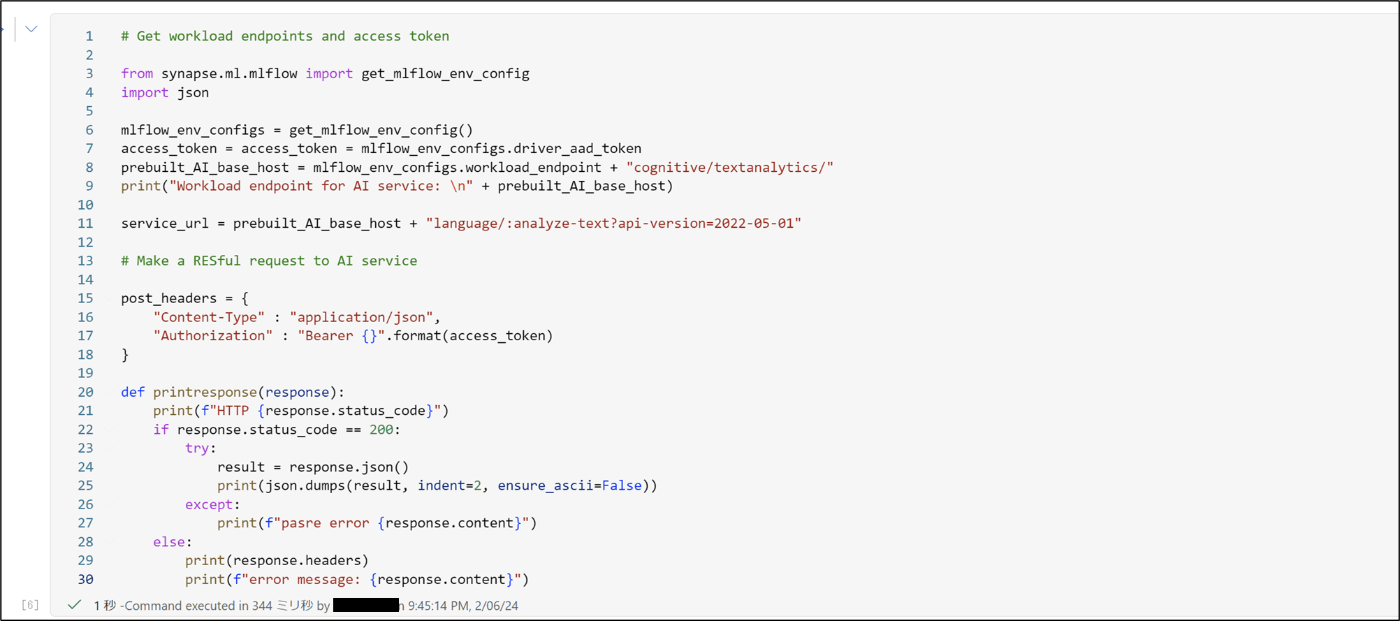
- 下記のコードを実行し、AIサービスに接続する
# Get workload endpoints and access token
from synapse.ml.mlflow import get_mlflow_env_config
import json
mlflow_env_configs = get_mlflow_env_config()
access_token = access_token = mlflow_env_configs.driver_aad_token
prebuilt_AI_base_host = mlflow_env_configs.workload_endpoint + "cognitive/textanalytics/"
print("Workload endpoint for AI service: \n" + prebuilt_AI_base_host)
service_url = prebuilt_AI_base_host + "language/:analyze-text?api-version=2022-05-01"
# Make a RESful request to AI service
post_headers = {
"Content-Type" : "application/json",
"Authorization" : "Bearer {}".format(access_token)
}
def printresponse(response):
print(f"HTTP {response.status_code}")
if response.status_code == 200:
try:
result = response.json()
print(json.dumps(result, indent=2, ensure_ascii=False))
except:
print(f"pasre error {response.content}")
else:
print(response.headers)
print(f"error message: {response.content}")
9. 下記のコードを実行する
post_body = {
"kind": "KeyPhraseExtraction",
"parameters": {
"modelVersion": "latest"
},
"analysisInput":{
"documents":[
{
"id":"1",
"language":"ja",
"text": "あの人は凄く怖いが、スタッフは凄く優しいです。"
}
]
}
}
post_headers["x-ms-workload-resource-moniker"] = str(uuid.uuid1())
response = requests.post(service_url, json=post_body, headers=post_headers)
# Output all information of the request process
printresponse(response)
- 出力結果を確認
HTTP 200
{
"kind": "KeyPhraseExtractionResults",
"results": {
"documents": [
{
"id": "1",
"keyPhrases": [
"スタッフ"
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2022-10-01"
}
}
※出力結果の解説 by ChatGPT
この出力結果は、指定されたテキストから抽出されたキーフレーズを示しています。具体的には以下の通りです。
HTTP 200: リクエストが正常に完了したことを示しています。
"kind": "KeyPhraseExtractionResults": この結果がキーフレーズ抽出の結果であることを示しています。
"documents": テキストの集合に対する分析結果が含まれています。ここでは1つのテキスト("id": "1")の結果のみが含まれています。
"id": "1": テキストに対して指定した一意の識別子です。
"keyPhrases": テキストから抽出されたキーフレーズのリストです。この場合、"スタッフ"がキーフレーズとして抽出されています。
"warnings": このリストには警告が含まれますが、今回は空です。これは分析中に問題が発生しなかったことを示しています。
"errors": このリストにはエラーが含まれますが、今回は空です。これは分析中にエラーが発生しなかったことを示しています。
"modelVersion": "2022-10-01": 使用されたモデルのバージョンを示しています。
この結果から、提供されたテキスト("あの人は凄く怖いが、スタッフは凄く優しいです。")から「スタッフ」がキーフレーズとして抽出されたことがわかります。このキーフレーズは、テキストの主要なトピックや主題を表していると考えることができます。

Discussion