Microsoft主催のGraphRAGセッションに参加したので、ざっくり概要をメモします。
RAGの課題2つ
1. 複数チャンクの情報を統合しての理解、またインデックス全体の理解が必要な抽象的な質問に不向き
→複数の業務マニュアルを取り込んだインデックスに対し、「在庫の修正方法教えて」などの曖昧な質問をすると様々な在庫の修正(海外/国内向けの在庫、予定在庫を増やしたいのか、履歴を修正したいのかなど)に関するチャンクが検索され、チャンク間の情報や関係性を考慮した回答するなどは苦手そう
→「過去2週間のメールについて最新情報を教えて」や「xx型の産業機器で最新モデルを教えて」など、インデックス全体の理解が必要そうな質問はそのまま検索しても、正しい情報は取得できなさそうな気がします。
2. プロンプトに含まれる情報が多すぎる場合(1Mトークン以上)、AOAIの回答精度が低下する
→ドキュメント全体の文書をプロンプトに入れて、要約するなどは回答トークンの制限もありますし、そもそも難しそう。
このような課題を解決する手段として、"From Local to Global: A Graph RAG Approach to
Query-Focused Summarization"という論文をベースにしたGraphRAGについての紹介がありました。
Microsoft Azure GraphRAGのポイント2つ
-
インデックス作成
→LLMでテキストデータセット全体からKnowledge graphを作成 -
検索クエリ
→クエリ時にKnowledge graphの階層データを利用してプロンプトを拡張
インデックス作成の概要
大まかな流れで言うと、ドキュメントからナレッジグラフのレポートを作成したのち、コミュニティと呼ばれる要約をさらに作成します。


ここでいうSemantic Search DBはGraphDBかと思いましたが、リソース的にはBlobStorageに置かれたParquetファイルのようです。
(AcceleratorでGraphRAG環境を作成するとCosmosDBやAI Searchが作成されるので、GraphDB的な機能があるのかと思いましたが、AzureにGraphDB的なリソースはまだないみたいです)
インデックス作成パイプラインのデータフロー

グローバルクエリとローカルクエリ
GraphRAGにはインデックス作成と同様にクエリ検索にも工夫があり、
グローバルクエリとローカルクエリという2つの検索方法があります。
(どっちのクエリを使うべきかの判断まではしてくれませんがLLMでできるかと)
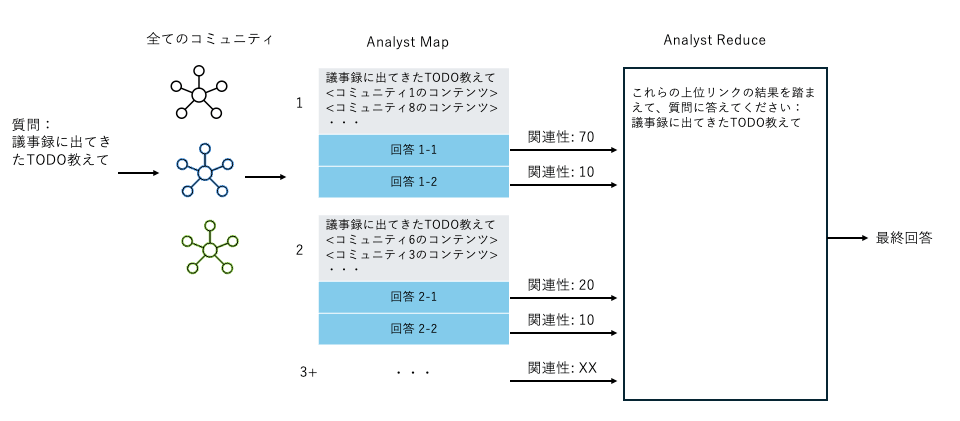
グローバルクエリとは
- コミュニティの要約レポートを活用して、データセットに関する全体的な質問についての推論のためのグローバル検索
- 回答を作成するためにデータセット全体の情報を集約する必要があるクエリに適している
- リソースを大量に消費する検索方式
Step1:
生成AIモデルを使用して、コミュニティレポートのN個のチャンクごとに、ユーザーの質問に対する回答と、回答の品質を示す数値スコアを生成
Step2:
ランク付けされた中間応答を1つのコンテキストウィンドウに結合し、生成AIモデルを使用して最終的な応答を生成
グローバルクエリのイメージ
ローカルクエリとは
- 特定のエンティティに関する推論を、エンティティとその近傍と関連する概念にファンアウトして検索
- ドキュメントに記載されている特定のエンティティを理解する必要がある質問に適している
- リソース消費はグローバルクエリより少ない
Step1: Query-entity Mapping
ユーザークエリとエンティティの類似性スコアから、ユーザークエリに対するセマンティック関連性が最も高い上位Nグラフエンティティを抽出
Step2: Related Entity Extraction
step1で抽出した各エンティティについて、グラフ内の他のエンティティのグラフ埋込の類似スコアが最も高い上位Kの近傍を見つける
Step 3: Entity Relationship and Covariate Retrieval
ステップ1+2から抽出されたエンティティセットを基に、これらのエンティティ (クレームなど) に関連付けられているすべての共変量と、これらのエンティティ間の関係のすべてのレコードを取得
Step 4: Response Generation
ステップ3で構築されたユーザークエリとデータコンテキストを基に、生成AIモデルを使用して応答を生成
その他
Acceleratorの紹介やアーキテクチャのざっくりした説明がありました。
まとめ
GraphRAGは単にナレッジグラフでエンティティの関係性がわかるというだけでなく、インデックス作成とクエリ検索のアルゴリズムを工夫することで、従来のRAGの課題解決に役立ちそうでワクワクしました!
ちなみにAcceleratorで環境作って放置すると一日6,000円くらいかかるので(VMとAI Searchが高い)、その点は気をつける必要があります。

Discussion