LLM/SLM初学者です。
現実的な言語モデル(LLM/SLM)の軽量化アプローチをまとめます。
様々なPruning手法が論文として提案されているかと思います。
しかし、モデルのリリースが高頻度で行われる昨今において、コストを掛けて高度なPruning手法を実装している最中により小型で高性能なモデルが新しく登場してしまい、結局はそれを利用した方が容易に軽量化が図れてしまうというのが現実かと思います。
そこで、本記事では実装コストを顧みつつ、
「理論上は、〜」ではなく、「実際のところは、〜」を徒然と書いていきます。
Pruningの大別

Efficient Large Language Models: A Survey '24
Pruningはunstructuredとstructuredに大別されます。
それぞれで様々な手法が提案されていますが、大雑把には以下のイメージです。
構造をいじらない(値をいじる)Pruning、構造をいじるPruningです。

さて、本題です。
Unstructured pruningが有効なハードウェア・ランタイムは限られる
Unstructured pruningの目的は重み行列のスパース化です。つまり、行列のサイズやモデルのモジュール単位でみたときにはPruningによる変更点はありません。
つまり、スパース行列による計算効率化に対応しているハードウェア利用、およびランタイムでのスパース行列カーネルの利用を満たせなければ、ただ単に推論時間そのままにモデル精度を落としているにすぎません。
広く普及しているハードウェアでスパース行列カーネルを搭載しているものは多くありません。例えば、NVIDIAのAmpere以降のGPUであったり、AMDやQualcommの一部アクセラレータに限られます。その上で、ランタイム側(例えば、PyTorchやTensorflow, ONNXRT)から適切にスパース行列カーネルが呼び出されているかを確認する必要もあります。Pytorchでは、スパース演算はベータ対応しているようです。


Structured pruningも設計上難しいことがある
Stuctured pruningの目的はモデルのモジュール単位で一部を削除することです。分かりやすく総演算量を削減できそうですが、いくつか注意点があります。
Stuctured pruningの例
stuctured pruningで削除する単位をAttention単位とするとします。

例えば、Phi-4-mini-instructモデルの中枢は32layer × 24headのAttentionで構成されます。
以下は、ほぼ同一モデルの感度行列と呼ばれるもので、画素の1つ1つがAttentionを示します。
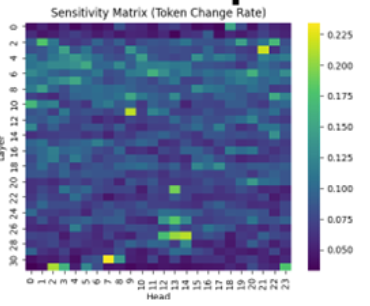
画素のスカラー値は、あるAttentionを無効化したときのモデル出力への変化量を示します。このような方法でモデル出力への影響が少ない一部のAttentionをStructured pruningすることが可能です。
詳細は、こちらへ。
Group query attention(GQA)
ここからStructured pruningの注意点について説明します。
現状のSoTA級モデル(Phi-4, Qwen3, Gemma3, Llama4など)はGQAを採用しています。イメージとしては以下の図の通りです。
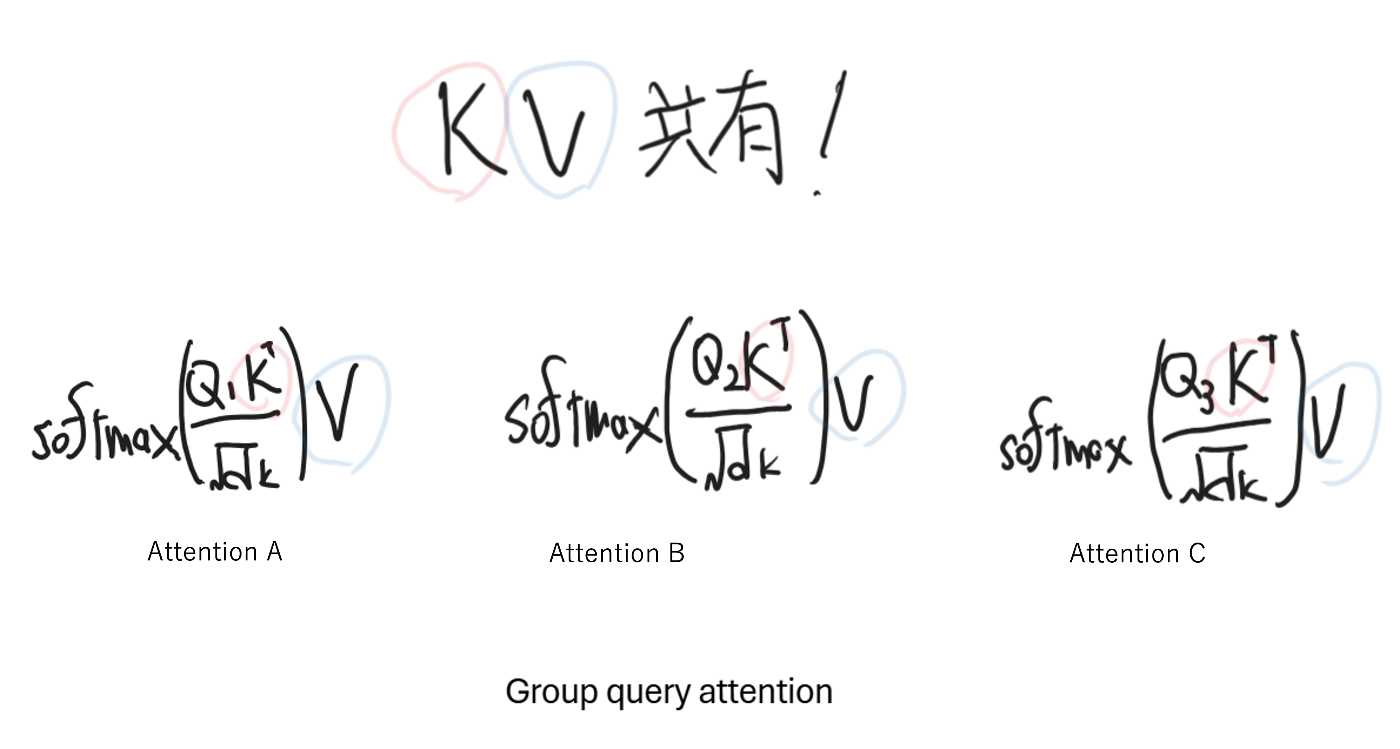
つまりGQA採用モデルをStuctured pruningする場合には、Attention単位ではなくKVを共有するAttention group単位でのpruningを検討する必要があるということです。
もう一段ややこしい点として、メモリ使用量削減が目的の場合には「KVを共有するAttention group単位」での検討が必要ですが、推論速度向上が目的の場合には「Attention単位」でも効果があります。
実装面でもAttention単位でのPruningは難しい
transformers libraryではモデル設定はconfig.jsonに記載されています。以下はPhi-4-mini-instructのconfig.jsonから一部を抜粋しています。
{
"_name_or_path": "Phi-4-mini-instruct",
...
"num_attention_heads": 24,
"num_hidden_layers": 32,
"num_key_value_heads": 8,
...
ここを確認するとnum_attention_headsとnum_hidden_layersが定義されていますが、つまりはAttentionがlayerごとに同数だけ存在すること、感度行列が長方形になることを前提とした実装になっています。したがって、Attention単位でpruningを行う場合には、config.jsonによって内部的に組み上げられるこの規格化されたAttentionアーキテクチャを変更する必要があり、実装コストが非常に大きいです。これは、「KVを共有するAttention group単位」でのpruningにも当てはまるかと思います。
多くのモデルがこのような実装になっているため、Attention単位でpruningが事実上難しいというのが現実です。
一方でlayerごとのPruningは容易なことが多い
Attention単位でpruningと違い、layerごとのPruningは容易なごとが多いです。以下の感度行列でいうと行ごとにモデルを削っていくイメージです。
理由としては、先ほどの通り「Attentionがlayerごとに同数だけ存在することを前提とした実装になっている」という点と干渉しない、かつ多くのモデルでlayerがnn.ModuleListで実装されているからです。nn.ModuleList実装されていると、Listと同じように[]operatorを使用して特定layerの削除が容易に行えます。
以下はPhi-4-mini-instructの例ですが、nn.ModuleListで実装されていることが確認できます。
class Phi3Model(Phi3PreTrainedModel):
def __init__(self, config: Phi3Config):
super().__init__(config)
self.padding_idx = config.pad_token_id
self.vocab_size = config.vocab_size
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
self.layers = nn.ModuleList(
[Phi3DecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
)
self.norm = Phi3RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.rotary_emb = Phi3RotaryEmbedding(config=config)
self.gradient_checkpointing = False
# Initialize weights and apply final processing
self.post_init()
ということで
Pruningは実装まで含めて考えると容易ではないということです。
重み共有に注意しながらnn.ModuleListを活用するのがアプローチしやすいかと思います。
Pruningによるモデルサイズ削減率について、10~20%程度が上限レベルという理解でしたが、最近は削減率50%ほどの手法も出てきており、実装リソースがあるならば積極的にPruningを導入してもよいかもしれません。
続編も書きます。

Discussion