前提
- SSMSをinstall済みであること
- kaggleのアカウントを登録していること
流れ
- Lakehouseを作り、titanicのデータをimportする
- SQL分析エンドポイントを用意する
- SSMSからSQL分析エンドポイントへアクセスする
Lakehouseを作り、titanicのデータをimportする
以下の記事の手順に沿って、importまで行ってください。
SQL分析エンドポイントを用意する
- Files > train.csv>データの読み込み>Spark をクリックし、コードを実行する
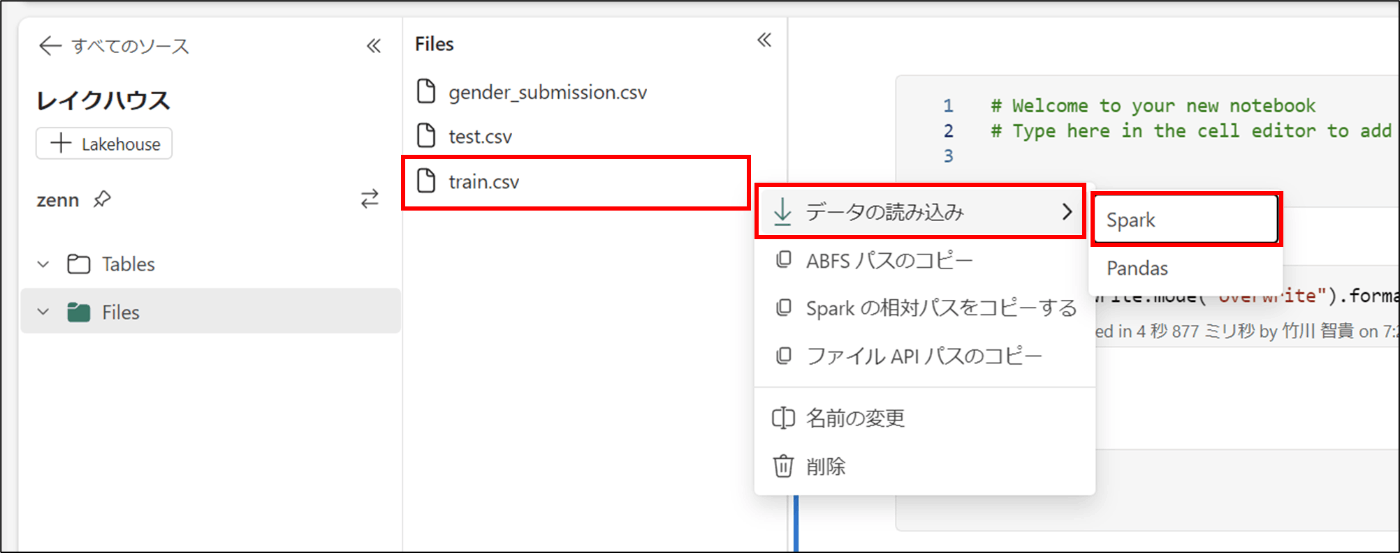
- 以下のコードを実行し、Table形式で保存する
df.write.mode("overwrite").format("delta").save("Tables/titanic")
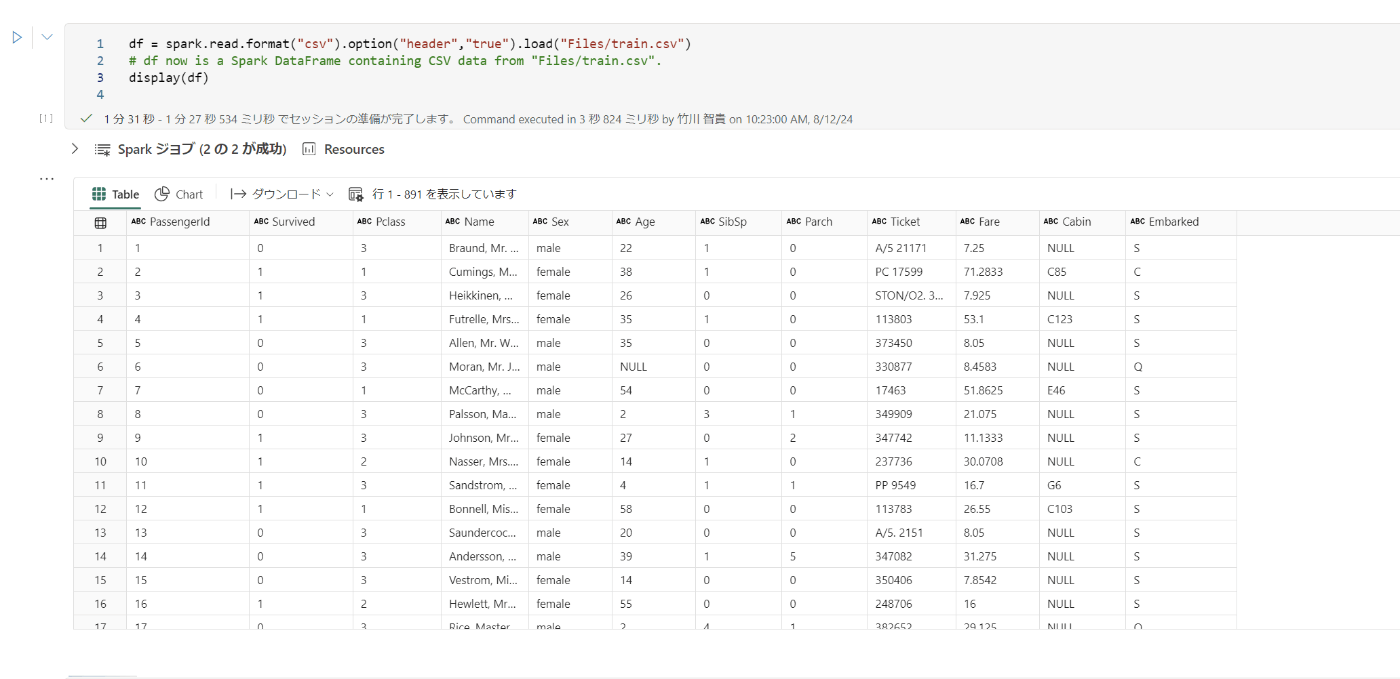
- 以下のコードを実行し、データを確認する
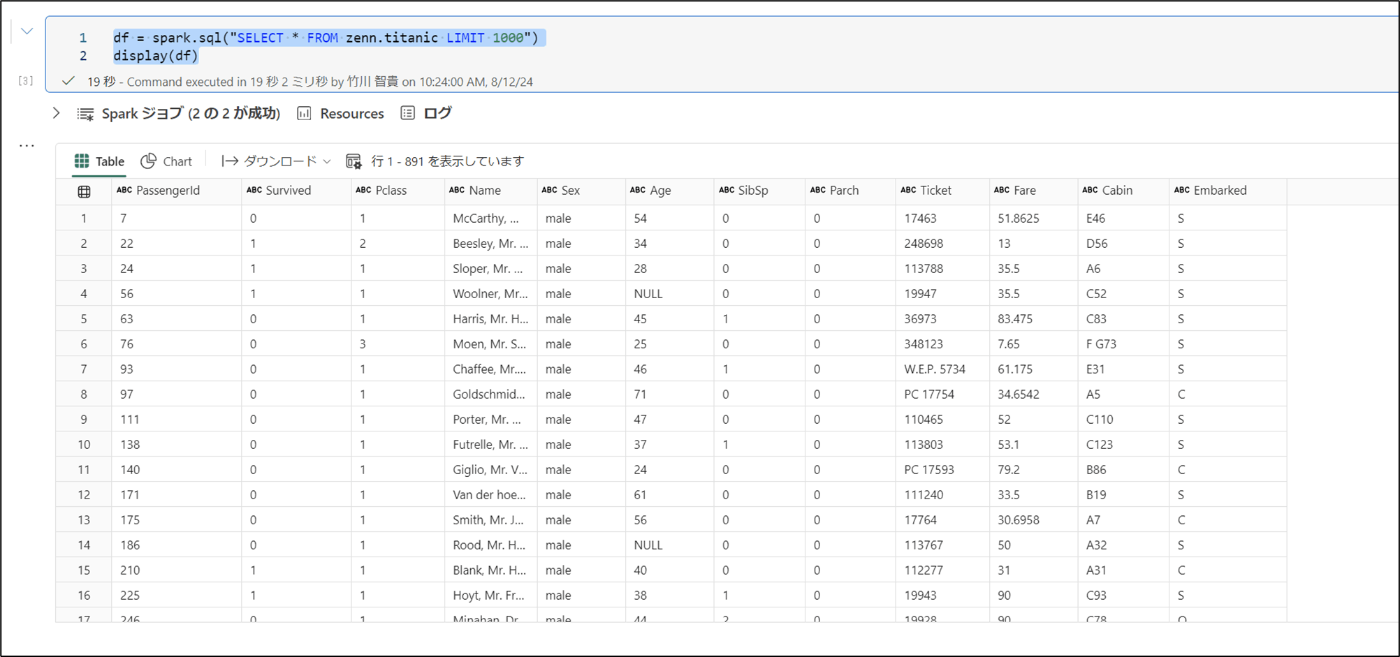
df = spark.sql("SELECT * FROM zenn.titanic LIMIT 1000")
display(df)
4. ワークスペースを開く
5. 該当のレイクハウス > SQL分析エンドポイントの・・・ をクリックする

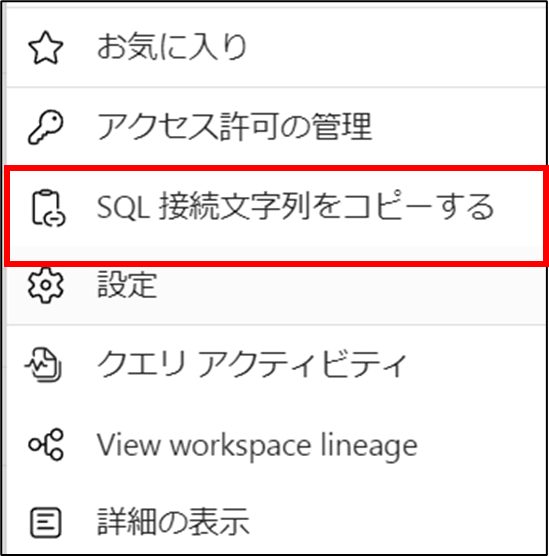
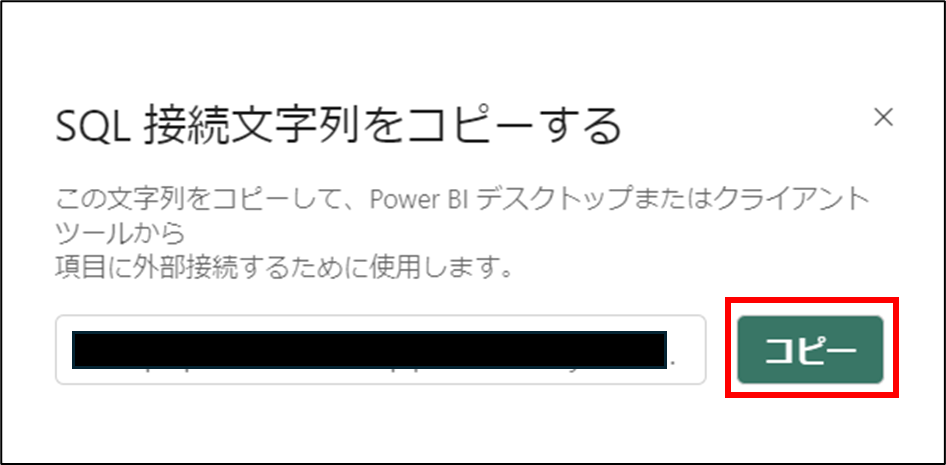
6. SQL接続文字列をコピーする をクリックする
7. コピー をクリックする
SSMSからSQL分析エンドポイントへアクセスする
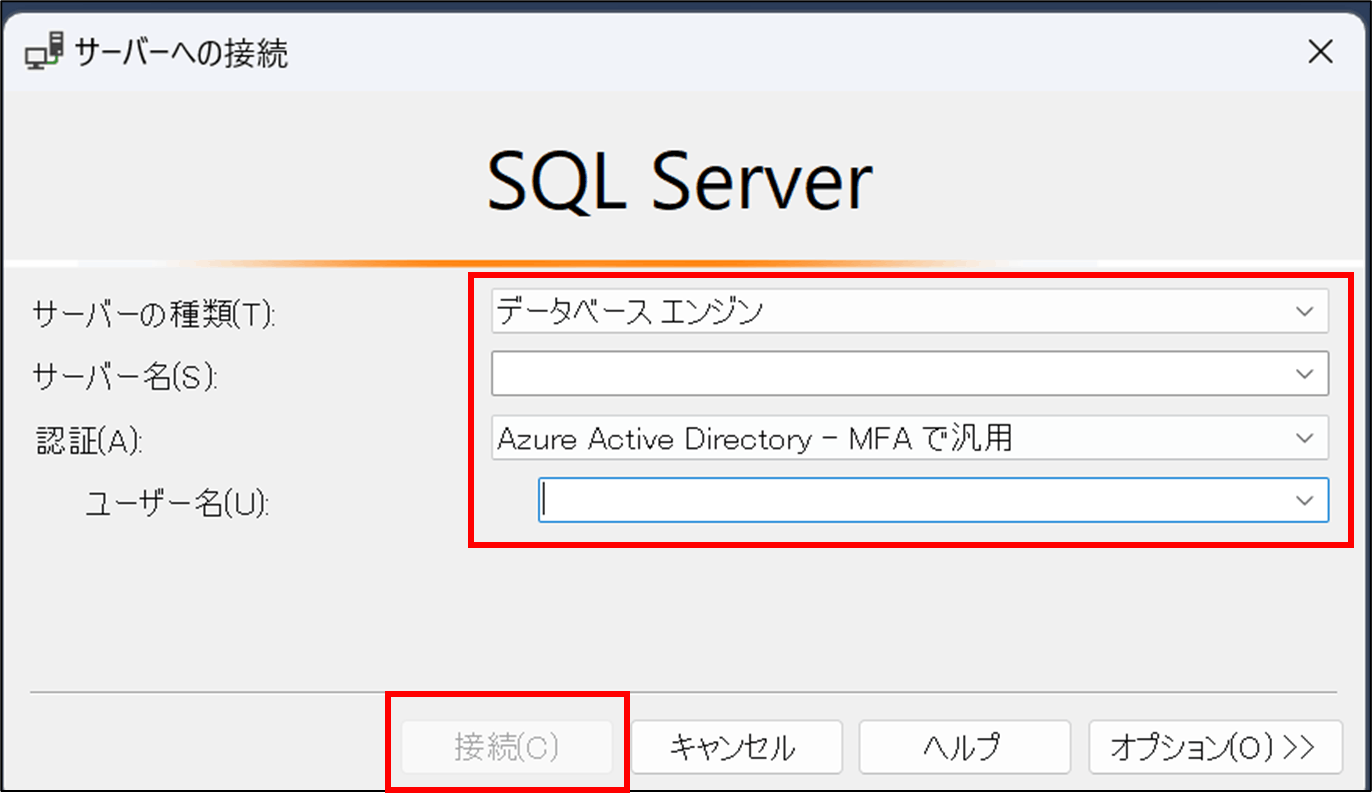
- SSMSを開く
- 以下のパラメータを入力し、接続 をクリックする
- サーバーの種類(T):データベースエンジン
- サーバー名:SQL分析エンドポイント
- 認証(A):Azure Active Directory-MFAで汎用
- ユーザー名:メールアドレス
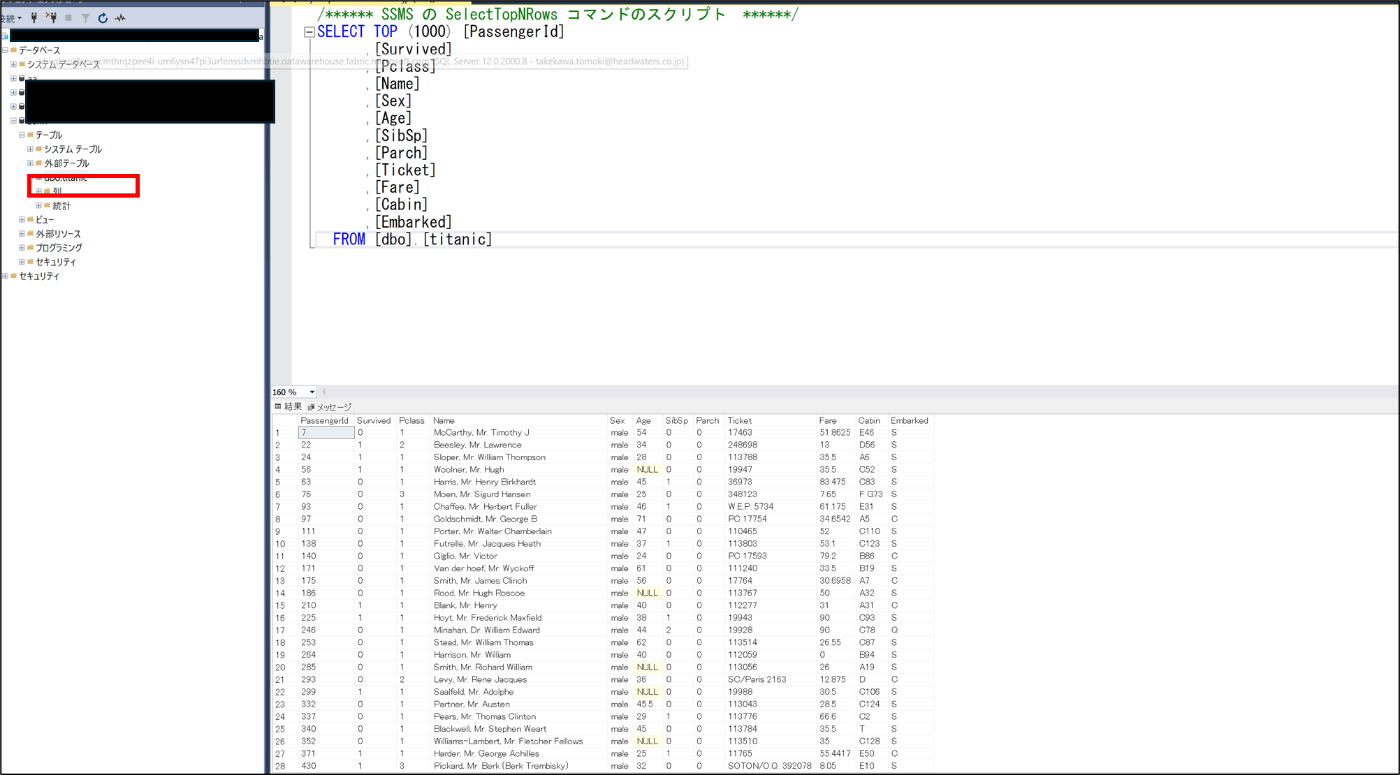
- 作成したTableが確認できることを確認

Discussion