目的
・リンナAIを誰もがファインチューニングできるようにする為のメモ
・なるべくお金をかけない
・AIの楽しさを世に広める
前提
・Googleアカウントが必要
Googleアカウントは個人用とビジネス用があるがどちらでもよい
・rinna/japanese-gpt2-smallを利用
推奨
・無料枠だと、GPUが足りないのでColab Pro+ \5,767/月の契約を追加すると尚好
(時間はいくらでもあるって人は追加不要。今回は追加契約なしで試してみる)
やったこと
- 準備①
- 準備②
- 学習環境の構築
- 学習用ファイルの設置
- 実行
1. 準備①
2ファイル準備が必要。以下のコードをそのままコピーしてローカルに作成する
- まずは、1ファイル目
ファイル名はなんでもいいが今回は「pip.sh」
pip install peft==0.9.0
pip install -Uqq transformers datasets accelerate bitsandbytes
pip install sentencepiece
pip install -f https://download.pytorch.org/whl/torch_stable.html torch==2.2.1
pip install numpy tensorboard
- 2ファイル目
ファイル名はなんでもいいが今回は「training.py」
import logging
import os
import json
import datetime
import torch
♯ import pandas as pd
from transformers import AutoTokenizer,AutoModelForCausalLM
from transformers import DataCollatorForLanguageModeling
from transformers import Trainer, TrainingArguments
from datasets import load_dataset, concatenate_datasets, DatasetDict
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training, TaskType
♯ トークナイズ
def tokenize(prompt, tokenizer):
result = tokenizer(
prompt,
truncation=True,
max_length=TOKEN_CUTOFF_LEN,
padding=False,
)
res = {
"input_ids": result["input_ids"],
"attention_mask": result["attention_mask"],
}
print('[tokenize] ' + json.dumps(res))
return res
# プロンプトテンプレートの準備
def generate_prompt(data_point):
result = f"### 入力: {data_point['prompt']} ### 回答: {data_point['target']}"
# 改行→<NL>
result = result.replace('\n', '<NL>')
return result
t_delta = datetime.timedelta(hours=9)
jst = datetime.timezone(t_delta, 'JST')
now = datetime.datetime.now(jst)
##### パラメータ
training_name = "exam01"
# GDrive
gdrive_path = "/content/drive/MyDrive"
# 基本パラメータ
model_name = "rinna/japanese-gpt2-small"
peft_name = f"{gdrive_path}/trained_model/lora-{model_name}/{training_name}"
output_dir = f"{gdrive_path}/temp/lora-{model_name}/{training_name}" # 関連ファイルを保存するパス
# トレーニングファイル
train_data_dir = f"{gdrive_path}/train/{training_name}"
train_data_files = [ f'{train_data_dir}/{f}' for f in os.listdir(train_data_dir) if os.path.isfile(os.path.join(train_data_dir, f)) ]
print('------------------ Train Files ------------------')
print(train_data_files)
print('------------------ ----------- ------------------')
# tokenize
TOKEN_CUTOFF_LEN = 256
VAL_SET_SIZE = 4
# LoRAのパラメータ(rinna/japanese-gpt-neox-3.6b)
# lora_config = LoraConfig(
# r=8,
# lora_alpha=16,
# lora_dropout=0.05,
# target_modules=["query_key_value"],
# bias="none",
# task_type=TaskType.CAUSAL_LM
# )
# LoRAのパラメータ(rinna/japanese-gpt2-small)
lora_config = LoraConfig(
r=8,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM
)
# 学習パラメータ
num_train_epochs = 300 # エポック数
learning_rate = 3e-4 # ラーニングレート
# eval_steps = 200 # 評価間隔(ステップ)
eval_steps = 5 # 評価間隔(ステップ)
# save_steps = 200 # モデルを保存する間隔
save_steps = 10 # モデルを保存する間隔
logging_steps = 5 # 途中経過を表示する間隔
logging_dir = f"{gdrive_path}/logging/lora-{model_name}/{training_name}"
##### tokenizer / model 準備
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto"
)
# cuda対応の場合はCUDAスイッチをON
if torch.cuda.is_available():
model = model.to("cuda")
# モデルの前処理
model = prepare_model_for_int8_training(model)
# LoRAモデルの準備
model = get_peft_model(model, lora_config)
# 学習可能パラメータの確認
model.print_trainable_parameters()
# データセットの設定
train_dataset: DatasetDict = load_dataset(
'csv',
delimiter='\t',
column_names=['prompt', 'target'],
data_files=train_data_files
)
# 学習データと検証データの準備
train_val = train_dataset["train"].train_test_split(
test_size=VAL_SET_SIZE, shuffle=True, seed=42
)
train_data = train_val["train"]
val_data = train_val["test"]
print('------------------ Train Data ------------------')
print(train_data)
print('------------------ val Data ------------------')
print(val_data)
print('------------------ ---------- ------------------')
train_data = train_data.map(lambda x: tokenize(generate_prompt(x), tokenizer))
val_data = val_data.map(lambda x: tokenize(generate_prompt(x), tokenizer))
# データの入力に関する設定
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)
# 訓練に関する設定
training_args = TrainingArguments(
num_train_epochs=num_train_epochs,
learning_rate=learning_rate,
logging_steps=logging_steps,
logging_dir=logging_dir,
evaluation_strategy="steps",
save_strategy="steps",
eval_steps=eval_steps,
save_steps=save_steps,
output_dir=output_dir,
report_to=["tensorboard"],
save_total_limit=3,
push_to_hub=False,
auto_find_batch_size=True,
overwrite_output_dir=True, # ファイルを上書きするかどうか
per_device_train_batch_size=8, # バッチサイズ
)
##### トレーナーの設定
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_data,
eval_dataset=val_data
)
# 学習の実施
model.config.use_cache = False
trainer.train()
model.config.use_cache = True
# LoRAモデルの保存
trainer.model.save_pretrained(peft_name)
2. 準備②
notebookにアクセス
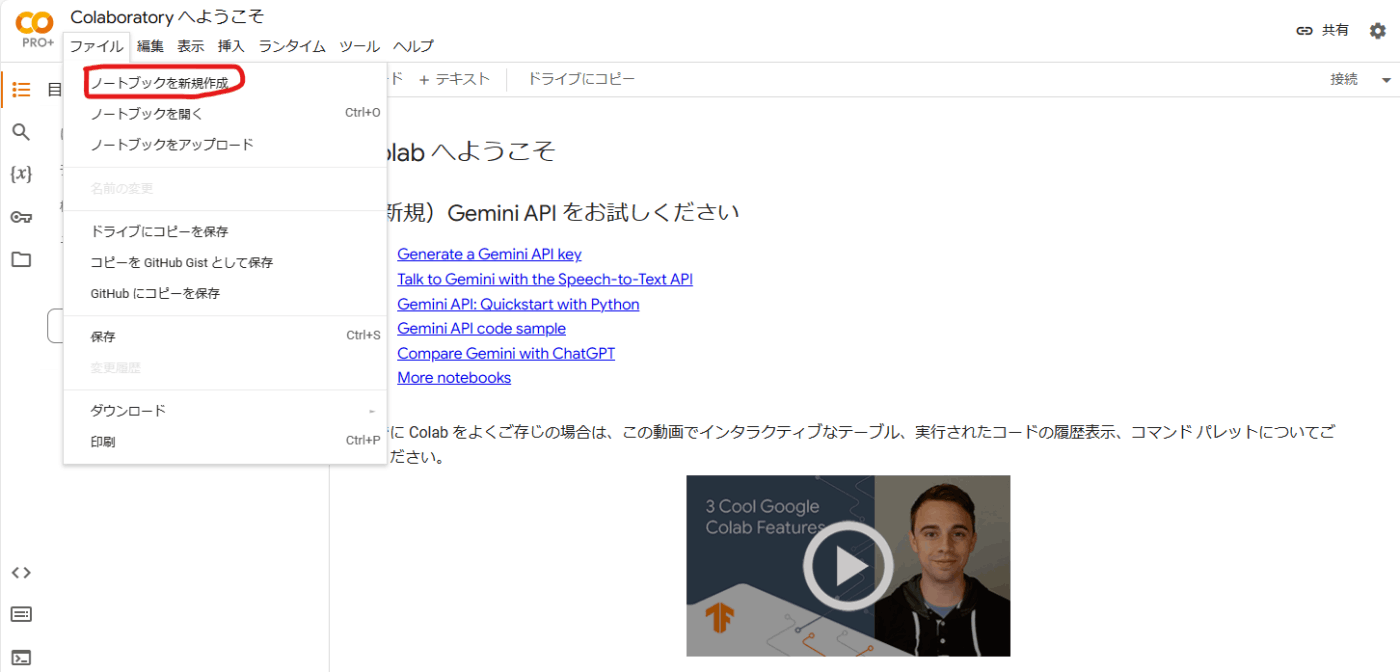
「ファイル」⇢「ノートブックを新規作成」をクリックし、新規ノートブックを作成
以下4個のPythonコードを新規ノートブックに書いて保存する
ファイル名は任意なので今回は「rinna_training_.ipynb」とする
- 1個目
!sh ./drive/MyDrive/script/pip.sh
- 2個目
!python ./drive/MyDrive/script/training.py
- 3個目
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
gdrive_path = "/content/drive/MyDrive"
training_name = "exam01"
# rinna/japanese-gpt2-smallでファインチューニングしてみる
model_name = "rinna/japanese-gpt2-small"
peft_name = f"{gdrive_path}/trained_model/lora-{model_name}/{training_name}"
# モデルの準備
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
)
# トークナイザーの準備
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
# LoRAモデルの準備
model = PeftModel.from_pretrained(
model,
peft_name,
device_map="auto"
)
# 評価モード
model.eval()
# プロンプトテンプレートの準備
def generate_prompt(data_point):
if data_point["input"]:
result = f"""### 指示:
{data_point["instruction"]}
### 入力:
{data_point["input"]}
### 回答:
"""
else:
result = f"""### 指示:
{data_point["instruction"]}
### 回答:
"""
# 改行→<NL>
result = result.replace('\n', '<NL>')
return result
# テキスト生成関数の定義
def generate(instruction,input=None,maxTokens=256):
# 推論
prompt = generate_prompt({'instruction':instruction,'input':input})
input_ids = tokenizer(prompt,
return_tensors="pt",
truncation=True,
add_special_tokens=False).input_ids
outputs = model.generate(
input_ids=input_ids,
max_new_tokens=maxTokens,
do_sample=True,
temperature=0.7,
top_p=0.75,
top_k=40,
no_repeat_ngram_size=2,
)
outputs = outputs[0].tolist()
print(tokenizer.decode(outputs))
# EOSトークンにヒットしたらデコード完了
if tokenizer.eos_token_id in outputs:
eos_index = outputs.index(tokenizer.eos_token_id)
decoded = tokenizer.decode(outputs[:eos_index])
# レスポンス内容のみ抽出
sentinel = "### 回答:"
sentinelLoc = decoded.find(sentinel)
if sentinelLoc >= 0:
result = decoded[sentinelLoc+len(sentinel):]
print(result.replace("<NL>", "\n")) # <NL>→改行
else:
print('Warning: Expected prompt template to be emitted. Ignoring output.')
else:
print('Warning: no <eos> detected ignoring output')
- 4個目
generate("おはようございます")
ファイルを一度ダウンロードする

「ファイル」→「ダウンロード」→「.jpymbをダウンロード」
3. 学習環境の構築
- 「rinna_training_.ipynb」をアップロードする
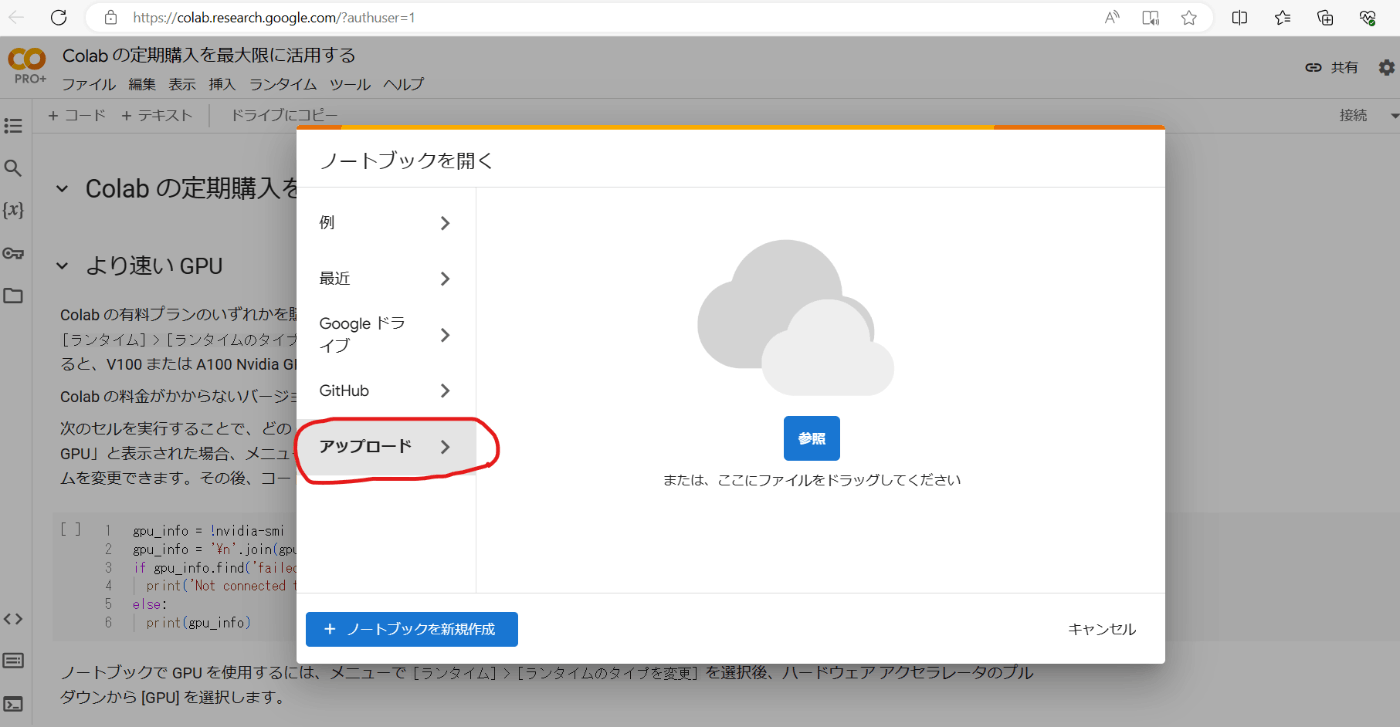
「アップロード」→「rinna_training_.ipynb」をドラック&ドロップ - ランタイム設定

「ランタイム」→「ランタイムタイプの対応を変更」をクリック
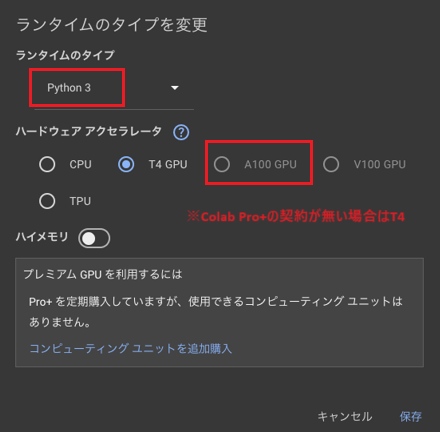
「保存」を押下 - Google Drive をマウント
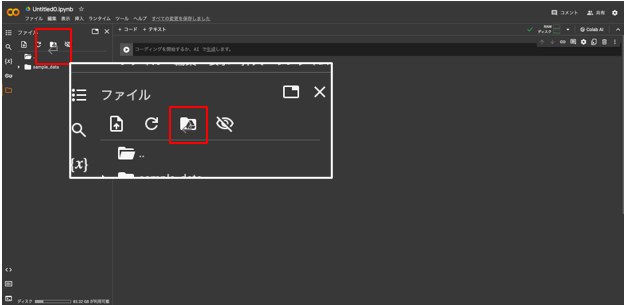
左側に縦に並んでいるフォルダーマーク→赤枠のマークをクリック
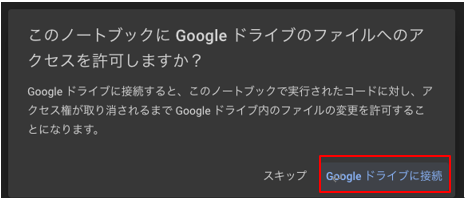
「Googleドライブに接続」をクリック
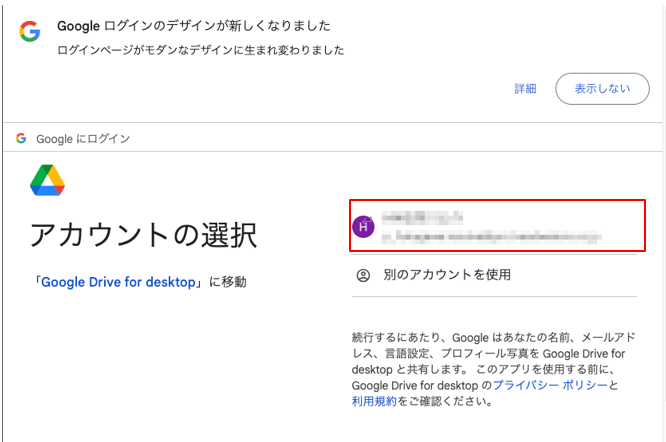
Googleにログインするアカウントをクリック
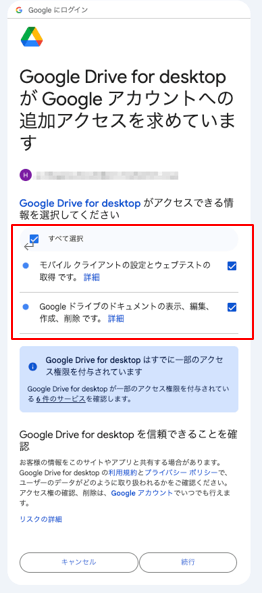
「すべて選択」→「続行」クリック
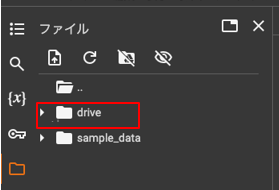
「drive」というフォルダが表示されていればマウント完了 - Google Drive上に学習に必要なファイルを配置する
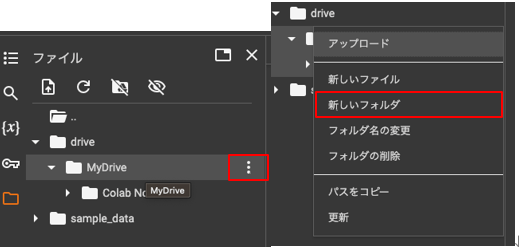
「MyDrive」→「新しいフォルダ」→「script」 フォルダを作成
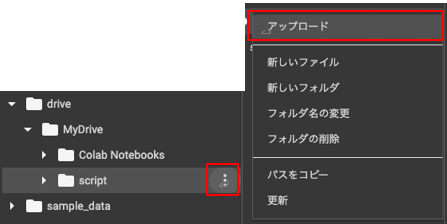
「script」→「アップロード」をクリック
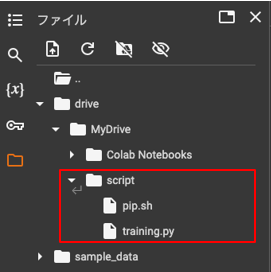
準備①で作成した「pip.sh」「training.py」をアップロード
4. 学習用ファイルの設置
「script」 フォルダと同じ要領で、「train」、trainの下に「exam01」を作成
「exam01」配下に配置したtsvファイルをすべて読み込む仕組みになっている
学習させたいデータをtsvファイル内に書いておくこと
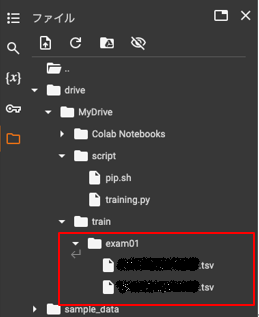
- 今回作成したデータの3行目まで

こんな感じにタブ区切りにすればOK
5. 実行
準備②で作成したPythonコードの1個目~4個目をノートブックの上から順番にポチポチするだけ

赤枠の矢印を押して、終わるのを待つのみ
ログがでるので、万が一エラーがあればここを確認、実行が終わると実行秒数が出る
- 最後の4個目はファインチューニングしたモデルに問い合わせの実行
色々入れてお試ししてほしい

試しに”桃と言ったらリンゴと答えるよね”と入れたら思った回答がでた!

思った回答が来なかった・・・

Discussion
リンナAIも触ってみたいです!(自分でやれよって話ですけど)