🧪 検証内容
Azure AI Foundry に登録されている オーディオモデル を使用し、
STT(Speech-to-Text) 機能の動作を検証しました。
また、前回行ったWebAPI(Speech Recognition)を使ったSTT検証の続きでもあります。
検証に使用したモデル
- gpt-4o-transcribe
- gpt-realtime
※今回は検証目的のため mini 版 を利用しています。
モデルの違い
gpt-4o-transcribe
- 主な用途:音声 → テキスト変換(音声認識 / Speech-to-Text)
-
特徴:録音済みの音声ファイル(例:
.wav,.mp3,.m4aなど)をアップロードし、その内容をテキスト化。 非リアルタイム処理に向いており、バッチ変換用途に最適です。
gpt-realtime
- 主な用途:リアルタイム音声対話(音声⇄音声 / Speech-to-Speech)
-
特徴:
WebRTC / WebSocket / SIP などのリアルタイム通信プロトコルを用いて、
音声ストリームを逐次解釈し、応答を返す双方向通信が可能。
今回はリアルタイム文字起こし(STT)用途として動作検証を行います。
🌐 プロトコルの違い
gpt-realtime モデルはリアルタイム通信に対応しており、
現在 WebRTC, WebSocket, SIP の 3 種類のプロトコルが利用可能です。
以下にそれぞれの概要をまとめます。
| 技術 | 主な用途 | 通信方向 | 使用層 | 主な利用例 |
|---|---|---|---|---|
| WebRTC | ブラウザ間の音声・映像・データ通信 | 双方向(P2P) | アプリ層(ブラウザ) | ビデオ通話、音声チャット、リアルタイムコラボ |
| WebSocket | サーバーとクライアント間の常時通信 | 双方向(サーバー⇔クライアント) | アプリ層 | チャット、株価配信、リアルタイムストリーミング |
| SIP | 通話セッションの制御(VoIP) | 双方向(制御信令) | アプリ層+通信制御層 | IP電話、PBX、企業通話管理 |
各プロトコルの通信フローや実装手順は、Microsoft 公式ドキュメントに詳しく記載されています。
Azure AI Foundry — Realtime Audio Overview
💻 実装
gpt-4o-transcribeの実装
最初にカスタムフックを実装します。
音声入力された個々のデータをまとめたもの(chunks)をaudio/webm形式にしてBlobを作成します。
さらに、API側で問扱いやすいようにFormDataに格納し送信します。
"use client";
import { useCallback } from "react";
type TranscribeResponse = {
text?: string;
[k: string]: unknown;
};
export function useSendToTranscribe() {
const sendChunksToAPI = useCallback(
async (chunks: BlobPart[], mimeType: string) => {
if (!chunks || chunks.length === 0) return;
try {
const blob = new Blob(chunks, { type: mimeType });
const fd = new FormData();
fd.append("audio", blob, "recording.webm");
const res = await fetch("/api/transcribe", { method: "POST", body: fd });
if (!res.ok) {
let errMsg = `HTTP ${res.status}`
console.error("Transcribe API error:", errMsg);
return;
}
const data = (await res.json()) as TranscribeResponse;
if (data.text) {
console.log("Transcribe result:", data.text);
}
return data;
} catch (err) {
console.error("Transcribe error:", err);
}
},
[]
);
return { sendChunksToAPI };
}
次にAPIを実装します。特に難しいところはありません。
import { NextRequest } from "next/server";
import { AzureOpenAI } from "openai";
export const runtime = "nodejs";
export async function POST(req: NextRequest) {
const form = await req.formData();
const blob = form.get("audio");
if (!(blob instanceof Blob)) return new Response("audio missing", { status: 400 });
const client = new AzureOpenAI({
endpoint: process.env.AZURE_OPENAI_AUDIO_ENDPOINT!,
apiKey: process.env.AZURE_OPENAI_AUDIO_API_KEY!,
apiVersion: process.env.OPENAI_AUDIO_API_VERSION!, //バージョンは公式ページを確認
deployment: process.env.AZURE_AUDIO_OPENAI_DEPLOYMENT!,
});
const file = new File([blob], "recording.webm", { type: blob.type || "audio/webm" });
const result = await client.audio.transcriptions.create({ model: "", file });
return Response.json(result); // { text: "..." }
}
gpt-realtimeの実装
カスタムフックの実装は長いので省略します。
公式ページに実装例があるので気になる方はこちらの記事を参考にしてみてください。
フックで実装することはWEBRTCを使ったリアルタイムセッションの確立です。
ユーザーから音声入力を受け取りWEBRCT経由で直接サーバーからレスポンを受け取ります。
gpt-realtimeをSTTで使う場合はsession.input_audio_transcriptionとsession.turn_detection.create_responseをfalseに設定する必要があります。
この辺のクライアント側の仕様はこちらにありました。
dc.onopen = () => {
dc.send(
JSON.stringify({
type: "session.update",
session: {
input_audio_format: "pcm16",
input_audio_transcription: {
model: "gpt-4o-mini-transcribe",
language: lang,
},
turn_detection: {
type: "server_vad",
threshold: 0.5,
prefix_padding_ms: 300,
silence_duration_ms: 500,
create_response: false,
},
},
})
);
};
API側の実装はエフェメラルキーを発行する実装のみです。
apiバージョンはドキュメントに記載のあるサポートしているAPIバージョンをご確認ください。
export const runtime = "nodejs";
export async function POST() {
const apiKey = process.env.AZURE_OPENAI_REALTIME_AUDIO_API_KEY!;
const resource = process.env.AZURE_OPENAI_REALTIME_AUDIO_RESOURCE!;
const deployment = process.env.AZURE_OPENAI_REALTIME_AUDIO_DEPLOYMENT_NAME!;
const apiVersion = process.env.AZURE_OPENAI_REALTIME_AUDIO_API_VERSION!;
const sessionsUrl = `https://${resource}.openai.azure.com/openai/realtimeapi/sessions?api-version=${apiVersion}`;
const body = {
model: deployment,
voice: "verse", // 音声出力する場合
};
try {
const res = await fetch(sessionsUrl, {
method: "POST",
headers: {
"authorization": `Bearer ${apiKey}`,
"content-type": "application/json",
},
body: JSON.stringify(body),
});
if (!res.ok) {
const text = await res.text();
// Log detailed error to server console for debugging
console.error("/api/realtime/session failed:", {
status: res.status,
statusText: res.statusText,
body: text,
});
return new Response(JSON.stringify({ error: "sessions failed", detail: text }), {
status: res.status,
headers: { "content-type": "application/json" },
});
}
// 返ってくる JSON に ephemeral な client_secret が入っている
const json = await res.json(); // { id, client_secret: { value, ... }, ... }
return new Response(JSON.stringify(json), {
status: 200,
headers: { "content-type": "application/json" },
});
} catch (err: unknown) {
console.error("/api/realtime/session error:", err);
return new Response(JSON.stringify({ error: String(err) }), {
status: 500,
headers: { "content-type": "application/json" },
});
}
}
🔍検証
CopilotにUIを作成してもらいそれぞれ検証していきます。
※GIFの画質が荒かったので出力の画像を載せます。
gpt-4o-transcribeの検証
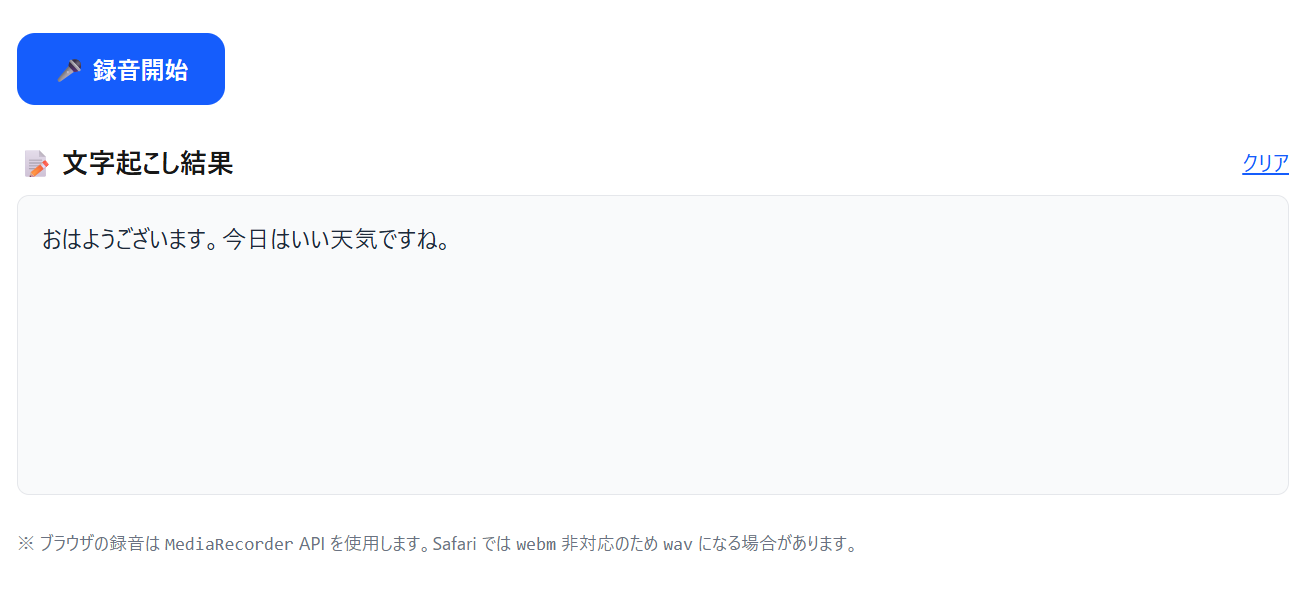
録音開始から録音停止までの間に入力された音声をバッチ処理でテキスト変換し返してくれました。音声入力も様々なパターンで試ましたがどれもテキスト変換の精度が高く感じました。
gpt-realtimeの検証
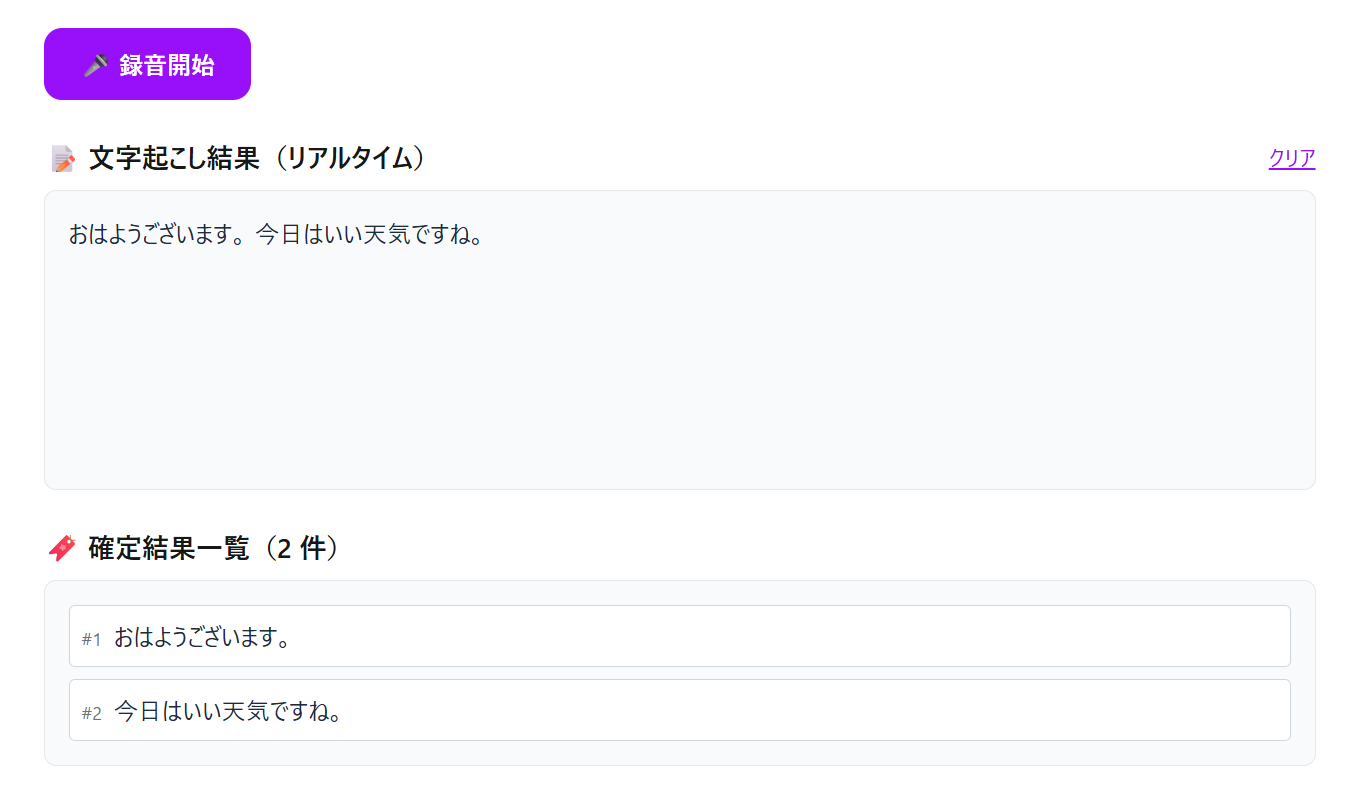
silence_duration_msを調整し単語間を識別することでほぼリアルタイムに文字起しが可能になりました。音声入力も様々パターンで試してみましたが、話すスピードを途中で変えてみたり
、文章の途中で無音の時間を入れたりするとテキスト変換の精度が落ちる場面がありました。
リアルタイム変換なので精度については難しい部分もあるのかなと感じました。
まとめ
本検証では STT(Speech-to-Text)の動作確認を実施しました。
今後は STS(Speech-to-Speech)や話者認識など、より幅広い音声技術の検証に取り組んでいけたらなと思います。
その他参考

Discussion